Merge pull request #171 from littletomatodonkey/fix_main
add faq and competition en doc
Showing
docs/en/competition_support_en.md
0 → 100644
docs/en/faq_en.md
0 → 100644
{kind=link}
124.1 KB
{kind=link}
{kind=link}
| W: | H:
| W: | H:
{kind=link}
{kind=link}

| W: | H:

| W: | H:
{kind=link}
{kind=link}

| W: | H:

| W: | H:
{kind=link}
{kind=link}
| W: | H:
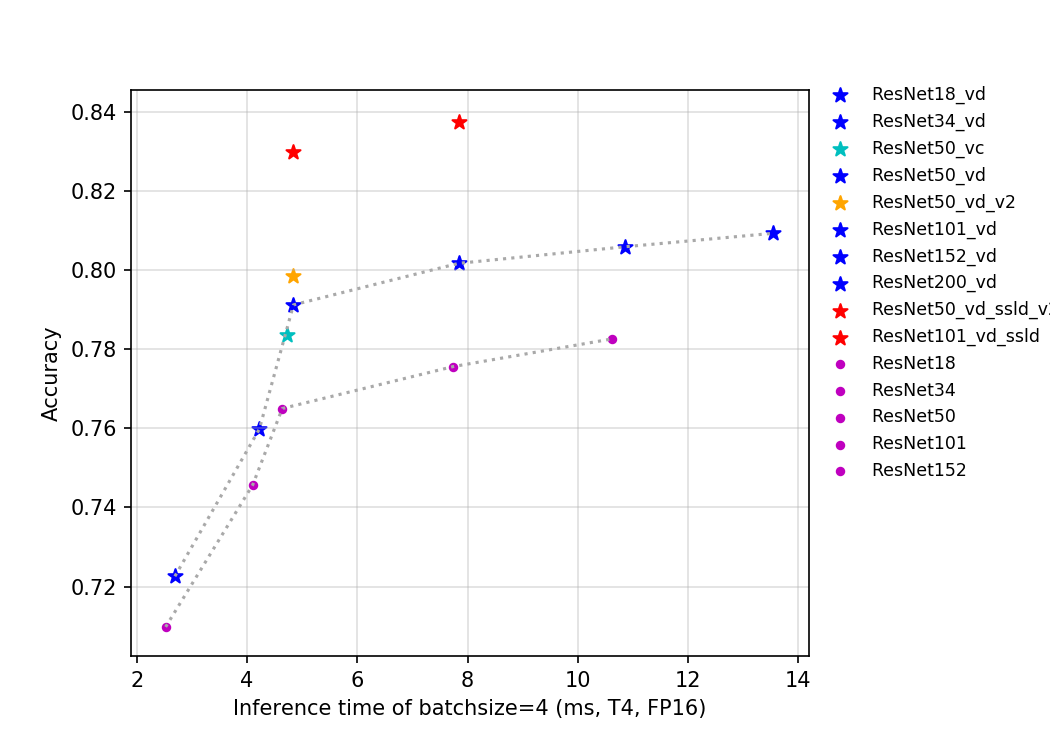
| W: | H:
{kind=link}
{kind=link}
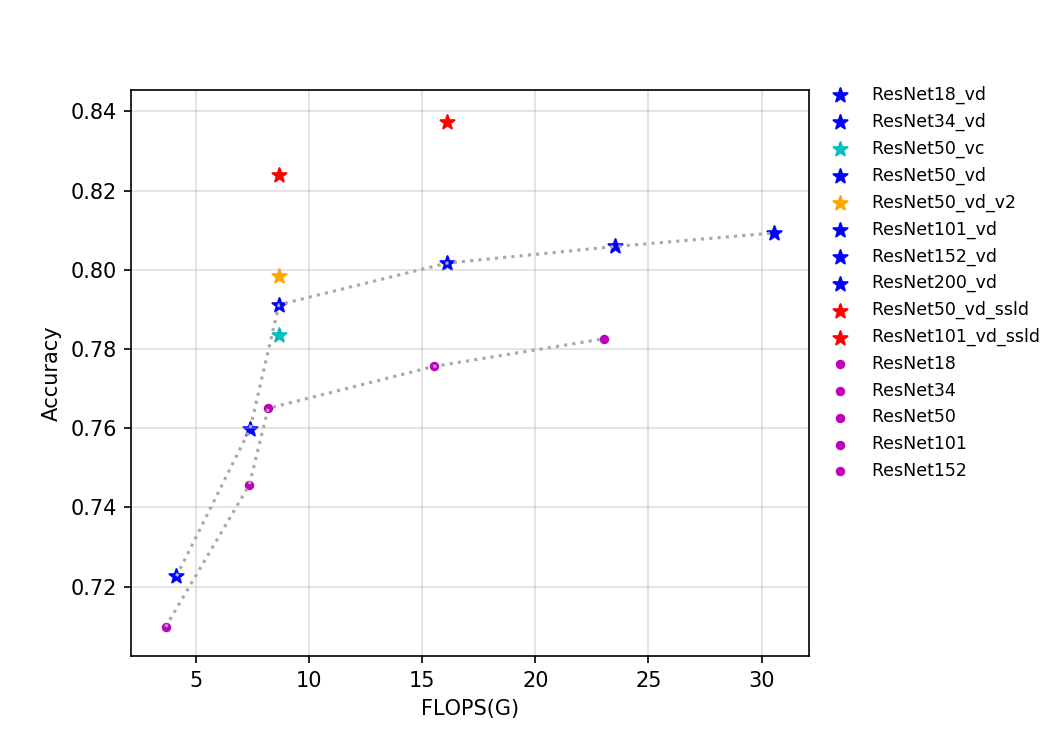
| W: | H:
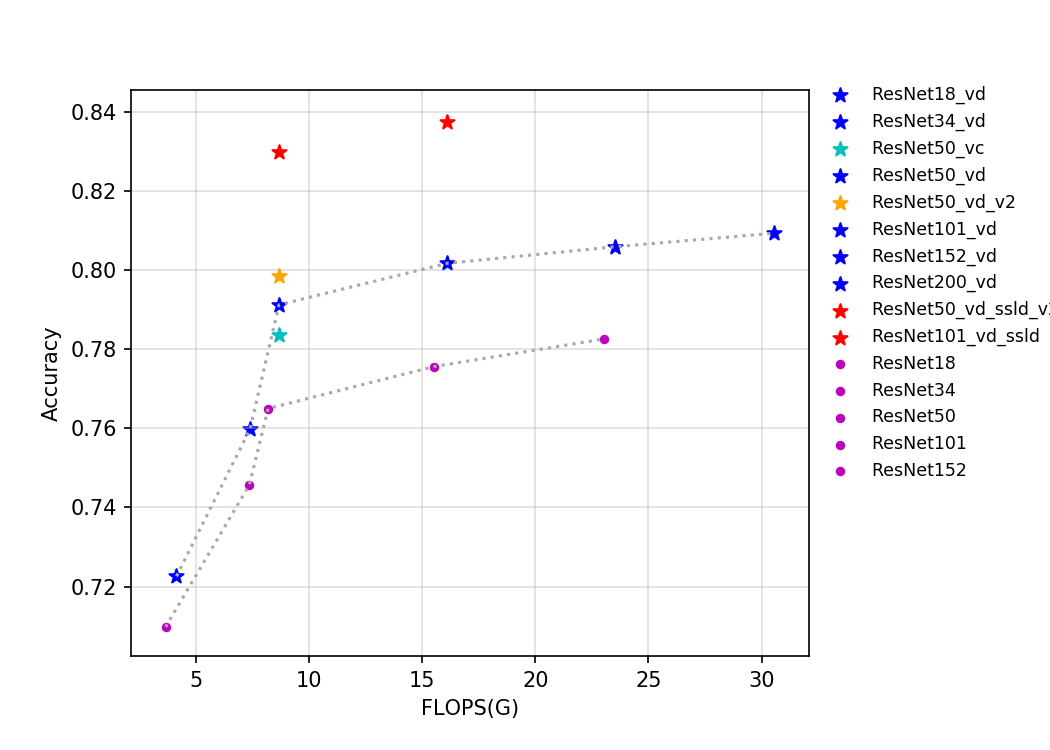
| W: | H:
{kind=link}
{kind=link}
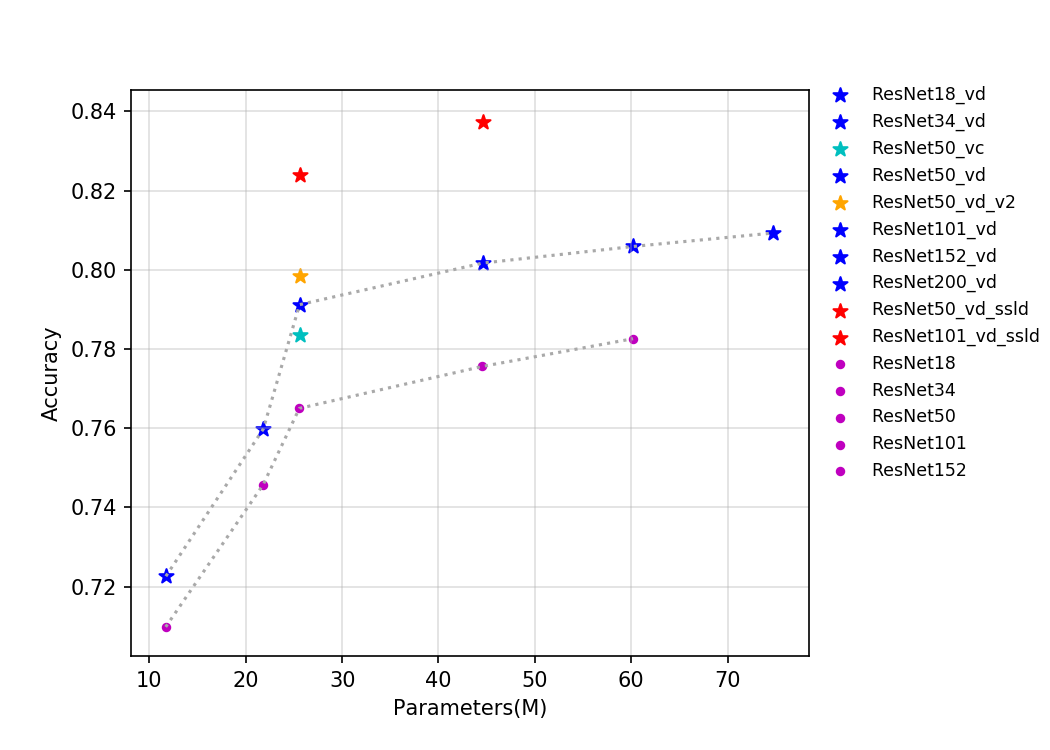
| W: | H:
| W: | H:
{kind=link}
{kind=link}
| W: | H:
| W: | H:
{kind=link}
{kind=link}
| W: | H:
| W: | H: