Skip to content
体验新版
项目
组织
正在加载...
登录
切换导航
打开侧边栏
PaddlePaddle
PaddleClas
提交
0707ff6f
P
PaddleClas
项目概览
PaddlePaddle
/
PaddleClas
1 年多 前同步成功
通知
115
Star
4999
Fork
1114
代码
文件
提交
分支
Tags
贡献者
分支图
Diff
Issue
19
列表
看板
标记
里程碑
合并请求
6
Wiki
0
Wiki
分析
仓库
DevOps
项目成员
Pages
P
PaddleClas
项目概览
项目概览
详情
发布
仓库
仓库
文件
提交
分支
标签
贡献者
分支图
比较
Issue
19
Issue
19
列表
看板
标记
里程碑
合并请求
6
合并请求
6
Pages
分析
分析
仓库分析
DevOps
Wiki
0
Wiki
成员
成员
收起侧边栏
关闭侧边栏
动态
分支图
创建新Issue
提交
Issue看板
未验证
提交
0707ff6f
编写于
7月 13, 2022
作者:
W
Wei Shengyu
提交者:
GitHub
7月 13, 2022
浏览文件
操作
浏览文件
下载
差异文件
Merge pull request #2123 from zoooo0820/add_train_cfg_for_calling
add training cfg for pphuman calling model
上级
d486dee2
1dfddd2b
变更
4
隐藏空白更改
内联
并排
Showing
4 changed file
with
384 addition
and
0 deletion
+384
-0
deploy/configs/inference_cls_based_action.yaml
deploy/configs/inference_cls_based_action.yaml
+33
-0
docs/images/action_rec_by_classification.gif
docs/images/action_rec_by_classification.gif
+0
-0
docs/zh_CN/algorithm_introduction/action_rec_by_classification.md
...CN/algorithm_introduction/action_rec_by_classification.md
+201
-0
ppcls/configs/practical_models/PPHGNet_tiny_calling_halfbody.yaml
...nfigs/practical_models/PPHGNet_tiny_calling_halfbody.yaml
+150
-0
未找到文件。
deploy/configs/inference_cls_based_action.yaml
0 → 100644
浏览文件 @
0707ff6f
Global
:
infer_imgs
:
"
./images/ImageNet/ILSVRC2012_val_00000010.jpeg"
inference_model_dir
:
"
./models/PPHGNet_tiny_calling_halfbody/"
batch_size
:
1
use_gpu
:
True
enable_mkldnn
:
True
cpu_num_threads
:
10
enable_benchmark
:
True
use_fp16
:
False
ir_optim
:
True
use_tensorrt
:
False
gpu_mem
:
8000
enable_profile
:
False
PreProcess
:
transform_ops
:
-
ResizeImage
:
resize_short
:
224
-
NormalizeImage
:
scale
:
0.00392157
mean
:
[
0.485
,
0.456
,
0.406
]
std
:
[
0.229
,
0.224
,
0.225
]
order
:
'
'
channel_num
:
3
-
ToCHWImage
:
PostProcess
:
main_indicator
:
Topk
Topk
:
topk
:
2
class_id_map_file
:
"
../dataset/data/phone_label_list.txt"
SavePreLabel
:
save_dir
:
./pre_label/
docs/images/action_rec_by_classification.gif
0 → 100644
浏览文件 @
0707ff6f
4.4 MB
docs/zh_CN/algorithm_introduction/action_rec_by_classification.md
0 → 100644
浏览文件 @
0707ff6f
# 基于图像分类的打电话行为识别模型
------
## 目录
-
[
1. 模型和应用场景介绍
](
#1
)
-
[
2. 模型训练、评估和预测
](
#2
)
-
[
2.1 PaddleClas 环境安装
](
#2.1
)
-
[
2.2 数据准备
](
#2.2
)
-
[
2.2.1 数据集下载
](
#2.2.1
)
-
[
2.2.2 训练及测试图像处理
](
#2.2.2
)
-
[
2.2.3 标注文件准备
](
#2.2.3
)
-
[
2.3 模型训练
](
#2.3
)
-
[
2.4 模型评估
](
#2.4
)
-
[
2.5 模型预测
](
#2.5
)
-
[
3. 模型推理部署
](
#3
)
-
[
3.1 模型导出
](
#3.1
)
-
[
3.2 执行模型预测
](
#3.2
)
-
[
4. 在PP-Human中使用该模型
](
#4
)
<div
align=
"center"
>
<img
src=
"../../images/action_rec_by_classification.gif"
width=
'1000'
/>
<center>
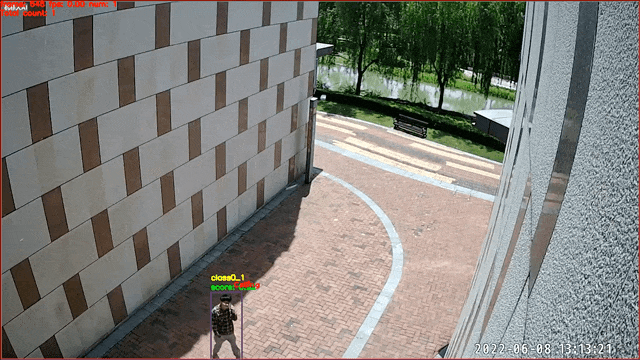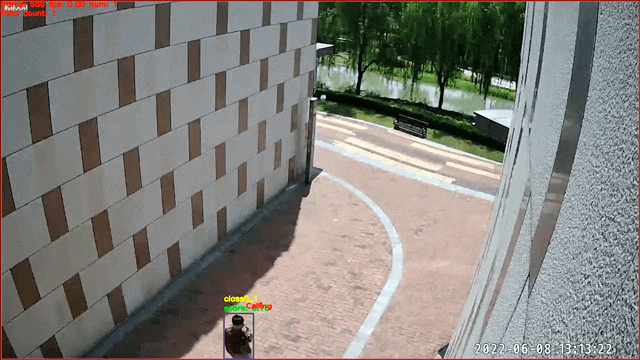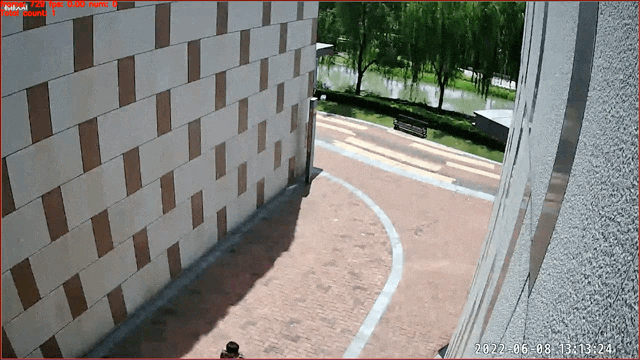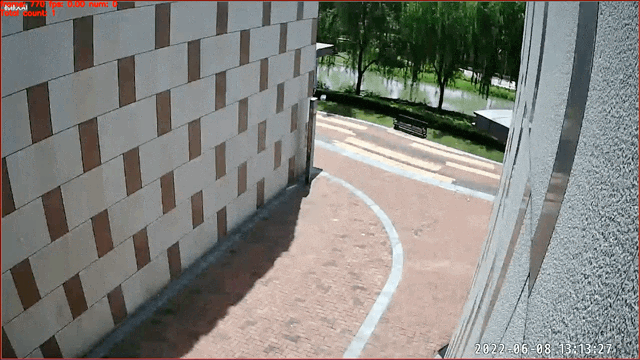
数据来源及版权归属:天覆科技,感谢提供并开源实际场景数据,仅限学术研究使用
</center>
</div>
<a
name=
"1"
></a>
## 1. 模型和应用场景介绍
行为识别在智慧社区,安防监控等方向具有广泛应用。根据行为的不同,一些行为可以通过图像直接进行行为判断(例如打电话)。这里我们提供了基于图像分类的打电话行为识别模型,对人物图像进行是否打电话的二分类识别。
| 任务 | 算法 | 精度 | 预测速度(ms) | 模型权重 |
| ---- | ---- | ---- | ---- | ------ |
| 打电话行为识别 | PP-HGNet-tiny | 准确率: 86.85 | 单人 2.94ms |
[
下载链接
](
https://bj.bcebos.com/v1/paddledet/models/pipeline/PPHGNet_tiny_calling_halfbody.pdparams
)
|
注:
1.
该模型使用
[
UAV-Human
](
https://github.com/SUTDCV/UAV-Human
)
的打电话行为部分进行训练和测试。
2.
预测速度为NVIDIA T4 机器上使用TensorRT FP16时的速度, 速度包含数据预处理、模型预测、后处理全流程。
该模型为实时行人分析工具
[
PP-Human
](
https://github.com/PaddlePaddle/PaddleDetection/tree/develop/deploy/pipeline
)
中行为识别功能的一部分,欢迎体验PP-Human的完整功能。
<a
name=
"2"
></a>
## 2. 模型训练、评估和预测
<a
name=
"2.1"
></a>
### 2.1 PaddleClas 环境安装
请根据
[
环境准备
](
../installation/install_paddleclas.md
)
完成PaddleClas的环境依赖准备。
<a
name=
"2.2"
></a>
### 2.2 数据准备
<a
name=
"2.2.1"
></a>
#### 2.2.1 数据集下载
打电话的行为识别是基于公开数据集
[
UAV-Human
](
https://github.com/SUTDCV/UAV-Human
)
进行训练的。请通过该链接填写相关数据集申请材料后获取下载链接。
在
`UAVHuman/ActionRecognition/RGBVideos`
路径下包含了该数据集中RGB视频数据集,每个视频的文件名即为其标注信息。
<a
name=
"2.2.2"
></a>
#### 2.2.2 训练及测试图像处理
根据视频文件名,其中与行为识别相关的为
`A`
相关的字段(即action),我们可以找到期望识别的动作类型数据。
-
正样本视频:以打电话为例,我们只需找到包含
`A024`
的文件。
-
负样本视频:除目标动作以外所有的视频。
鉴于视频数据转化为图像会有较多冗余,对于正样本视频,我们间隔8帧进行采样,并使用行人检测模型处理为半身图像(取检测框的上半部分,即
`img = img[:H/2, :, :]`
)。正样本视频中的采样得到的图像即视为正样本,负样本视频中采样得到的图像即为负样本。
**注意**
: 正样本视频中并不完全符合打电话这一动作,在视频开头结尾部分会出现部分冗余动作,需要移除。
<a
name=
"2.2.3"
></a>
#### 2.2.3 标注文件准备
根据
[
PaddleClas数据集格式说明
](
../data_preparation/classification_dataset.md
)
,标注文件样例如下,其中
`0`
,
`1`
分别是图片对应所属的类别:
```
# 每一行采用"空格"分隔图像路径与标注
train/000001.jpg 0
train/000002.jpg 0
train/000003.jpg 1
...
```
此外,标签文件
`phone_label_list.txt`
,帮助将分类序号映射到具体的类型名称:
```
0 make_a_phone_call # 类型0
1 normal # 类型1
```
完成上述内容后,放置于
`dataset`
目录下,文件结构如下:
```
data/
├── images # 放置所有图片
├── phone_label_list.txt # 标签文件
├── phone_train_list.txt # 训练列表,包含图片及其对应类型
└── phone_val_list.txt # 测试列表,包含图片及其对应类型
```
<a
name=
"2.3"
></a>
### 2.3 模型训练
通过如下命令启动训练:
```
bash
export
CUDA_VISIBLE_DEVICES
=
0,1,2,3
python3
-m
paddle.distributed.launch
\
--gpus
=
"0,1,2,3"
\
tools/train.py
\
-c
./ppcls/configs/practical_models/PPHGNet_tiny_calling_halfbody.yaml
\
-o
Arch.pretrained
=
True
```
其中
`Arch.pretrained`
为
`True`
表示使用预训练权重帮助训练。
<a
name=
"2.4"
></a>
### 2.4 模型评估
训练好模型之后,可以通过以下命令实现对模型指标的评估。
```
bash
python3 tools/eval.py
\
-c
./ppcls/configs/practical_models/PPHGNet_tiny_calling_halfbody.yaml
\
-o
Global.pretrained_model
=
output/PPHGNet_tiny/best_model
```
其中
`-o Global.pretrained_model="output/PPHGNet_tiny/best_model"`
指定了当前最佳权重所在的路径,如果指定其他权重,只需替换对应的路径即可。
<a
name=
"2.5"
></a>
### 2.5 模型预测
模型训练完成之后,可以加载训练得到的预训练模型,进行模型预测。在模型库的
`tools/infer.py`
中提供了完整的示例,只需执行下述命令即可完成模型预测:
```
bash
python3 tools/infer.py
\
-c
./ppcls/configs/practical_models/PPHGNet_tiny_calling_halfbody.yaml
\
-o
Global.pretrained_model
=
output/PPHGNet_tiny/best_model
-o
Infer.infer_imgs
={
your
test
image
}
```
<a
name=
"3"
></a>
## 3. 模型推理部署
Paddle Inference 是飞桨的原生推理库,作用于服务器端和云端,提供高性能的推理能力。相比于直接基于预训练模型进行预测,Paddle Inference可使用 MKLDNN、CUDNN、TensorRT 进行预测加速,从而实现更优的推理性能。更多关于 Paddle Inference 推理引擎的介绍,可以参考
[
Paddle Inference官网教程
](
https://www.paddlepaddle.org.cn/documentation/docs/zh/guides/infer/inference/inference_cn.html
)
。
<a
name=
"3.1"
></a>
### 3.1 模型导出
```
bash
python3 tools/export_model.py
\
-c
./ppcls/configs/practical_models/PPHGNet_tiny_calling_halfbody.yaml
\
-o
Global.pretrained_model
=
output/PPHGNet_tiny/best_model
\
-o
Global.save_inference_dir
=
deploy/models//PPHGNet_tiny_calling_halfbody/
```
执行完该脚本后会在
`deploy/models/`
下生成
`PPHGNet_tiny_calling_halfbody`
文件夹,文件结构如下:
```
├── PPHGNet_tiny_calling_halfbody
│ ├── inference.pdiparams
│ ├── inference.pdiparams.info
│ └── inference.pdmodel
```
<a
name=
"3.2"
></a>
### 3.2 执行模型预测
在
`deploy`
下,执行下列命令:
```
bash
# Current path is {root of PaddleClas}/deploy
python3 python/predict_cls.py
-c
configs/inference_cls_based_action.yaml
```
<a
name=
"4"
></a>
## 4. 在PP-Human中使用该模型
[
PP-Human
](
https://github.com/PaddlePaddle/PaddleDetection/tree/develop/deploy/pipeline
)
是基于飞桨深度学习框架的业界首个开源产业级实时行人分析工具,具有功能丰富,应用广泛和部署高效三大优势。该模型可以应用于PP-Human中,实现实时视频的打电话行为识别功能。
由于当前的PP-Human功能集成在
[
PaddleDetection
](
https://github.com/PaddlePaddle/PaddleDetection
)
中,需要按以下步骤实现该模型在PP-Human中的调用适配。
1.
完成模型导出
2.
重命名模型
```
bash
cd
deploy/models/PPHGNet_tiny_calling_halfbody
mv
inference.pdiparams model.pdiparams
mv
inference.pdiparams.info model.pdiparams.info
mv
inference.pdmodel model.pdmodel
```
3.
下载
[
预测配置文件
](
https://bj.bcebos.com/v1/paddledet/models/pipeline/infer_configs/PPHGNet_tiny_calling_halfbody/infer_cfg.yml
)
```
bash
wget https://bj.bcebos.com/v1/paddledet/models/pipeline/infer_configs/PPHGNet_tiny_calling_halfbody/infer_cfg.yml
```
完成后文件结构如下,即可在PP-Human中使用:
```
PPHGNet_tiny_calling_halfbody
├── infer_cfg.yml
├── model.pdiparams
├── model.pdiparams.info
└── model.pdmodel
```
详细请参考
[
基于图像分类的行为识别——打电话识别
](
https://github.com/PaddlePaddle/PaddleDetection/blob/develop/deploy/pipeline/docs/tutorials/action.md#%E5%9F%BA%E4%BA%8E%E5%9B%BE%E5%83%8F%E5%88%86%E7%B1%BB%E7%9A%84%E8%A1%8C%E4%B8%BA%E8%AF%86%E5%88%AB%E6%89%93%E7%94%B5%E8%AF%9D%E8%AF%86%E5%88%AB
)
。
ppcls/configs/practical_models/PPHGNet_tiny_calling_halfbody.yaml
0 → 100644
浏览文件 @
0707ff6f
# global configs
Global
:
checkpoints
:
null
pretrained_model
:
null
output_dir
:
./output/
device
:
gpu
save_interval
:
1
eval_during_train
:
True
eval_interval
:
1
epochs
:
50
print_batch_step
:
10
use_visualdl
:
False
# used for static mode and model export
image_shape
:
[
3
,
224
,
224
]
save_inference_dir
:
./inference
# training model under @to_static
to_static
:
False
use_dali
:
False
# model architecture
Arch
:
name
:
PPHGNet_tiny
class_num
:
2
# loss function config for traing/eval process
Loss
:
Train
:
-
CELoss
:
weight
:
1.0
epsilon
:
0.1
Eval
:
-
CELoss
:
weight
:
1.0
Optimizer
:
name
:
Momentum
momentum
:
0.9
lr
:
name
:
Cosine
learning_rate
:
0.05
warmup_epoch
:
3
regularizer
:
name
:
'
L2'
coeff
:
0.00004
# data loader for train and eval
DataLoader
:
Train
:
dataset
:
name
:
ImageNetDataset
image_root
:
./dataset/
cls_label_path
:
./dataset/phone_train_list_halfbody.txt
transform_ops
:
-
DecodeImage
:
to_rgb
:
True
channel_first
:
False
-
ResizeImage
:
size
:
224
-
RandFlipImage
:
flip_code
:
1
-
TimmAutoAugment
:
config_str
:
rand-m7-mstd0.5-inc1
interpolation
:
bicubic
img_size
:
224
-
NormalizeImage
:
scale
:
1.0/255.0
mean
:
[
0.485
,
0.456
,
0.406
]
std
:
[
0.229
,
0.224
,
0.225
]
order
:
'
'
-
RandomErasing
:
EPSILON
:
0.25
sl
:
0.02
sh
:
1.0/3.0
r1
:
0.3
attempt
:
10
use_log_aspect
:
True
mode
:
pixel
batch_transform_ops
:
-
OpSampler
:
MixupOperator
:
alpha
:
0.2
prob
:
0.5
CutmixOperator
:
alpha
:
1.0
prob
:
0.5
sampler
:
name
:
DistributedBatchSampler
batch_size
:
128
drop_last
:
False
shuffle
:
True
loader
:
num_workers
:
2
use_shared_memory
:
False
Eval
:
dataset
:
name
:
ImageNetDataset
image_root
:
./dataset/
cls_label_path
:
./dataset/phone_val_list_halfbody.txt
transform_ops
:
-
DecodeImage
:
to_rgb
:
True
channel_first
:
False
-
ResizeImage
:
size
:
224
interpolation
:
bicubic
backend
:
pil
-
NormalizeImage
:
scale
:
1.0/255.0
mean
:
[
0.485
,
0.456
,
0.406
]
std
:
[
0.229
,
0.224
,
0.225
]
order
:
'
'
sampler
:
name
:
DistributedBatchSampler
batch_size
:
128
drop_last
:
False
shuffle
:
False
loader
:
num_workers
:
2
use_shared_memory
:
False
Infer
:
infer_imgs
:
docs/images/inference_deployment/whl_demo.jpg
batch_size
:
1
transforms
:
-
DecodeImage
:
to_rgb
:
True
channel_first
:
False
-
ResizeImage
:
size
:
224
-
NormalizeImage
:
scale
:
1.0/255.0
mean
:
[
0.485
,
0.456
,
0.406
]
std
:
[
0.229
,
0.224
,
0.225
]
order
:
'
'
-
ToCHWImage
:
PostProcess
:
name
:
Topk
topk
:
2
class_id_map_file
:
dataset/phone_label_list.txt
Metric
:
Train
:
-
TopkAcc
:
topk
:
[
1
,
1
]
Eval
:
-
TopkAcc
:
topk
:
[
1
,
1
]
编辑
预览
Markdown
is supported
0%
请重试
或
添加新附件
.
添加附件
取消
You are about to add
0
people
to the discussion. Proceed with caution.
先完成此消息的编辑!
取消
想要评论请
注册
或
登录
{kind=link}