Created by: still-wait
PR types
New features
PR changes
APIs
Describe
add paddle.nn.SmoothL1Loss. This operator is calculate smooth_l1_loss. Creates a criterion that uses a squared term if the absolute element-wise error falls below 1 and an L1 term otherwise. In some cases it can prevent exploding gradients. Also known as the Huber loss.
class:
class paddle.nn.SmoothL1Loss(reduction='mean')functioanl:
def paddle.nn.functioanl.smooth_l1_loss(input, label)docs


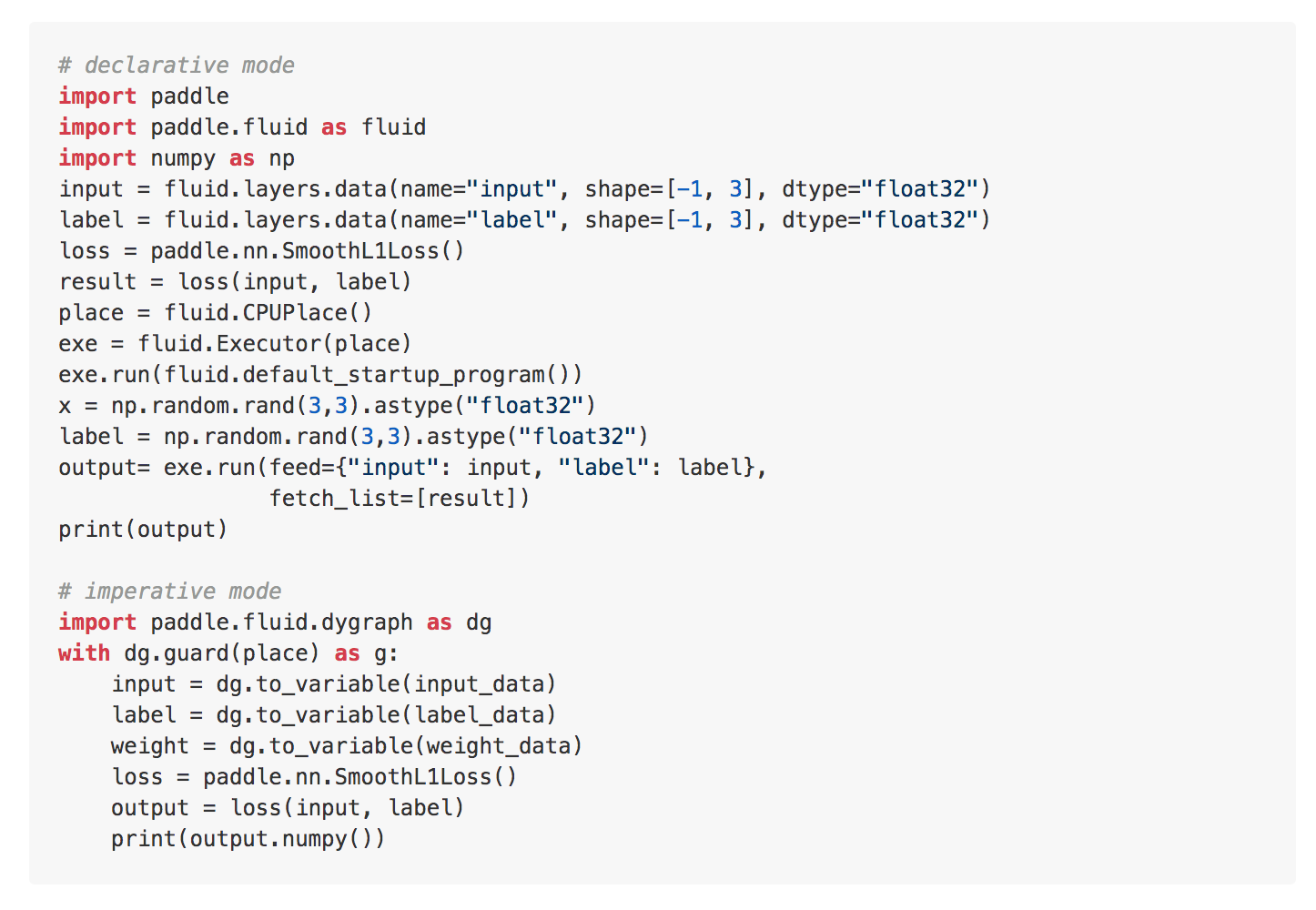
Examples:
# declarative mode
import paddle
import paddle.fluid as fluid
import numpy as np
input = fluid.layers.data(name="input", shape=[-1, 3], dtype="float32")
label = fluid.layers.data(name="label", shape=[-1, 3], dtype="float32")
loss = paddle.nn.SmoothL1Loss()
result = loss(x,label)
place = fluid.CPUPlace()
exe = fluid.Executor(place)
exe.run(fluid.default_startup_program())
input_data = np.random.rand(3,3).astype("float32")
label_data = np.random.rand(3,3).astype("float32")
output= exe.run(feed={"input": input_data, "label": label_data},
fetch_list=[result])
print(output)
# imperative mode
import paddle.fluid.dygraph as dg
with dg.guard(place) as g:
input = dg.to_variable(input_data)
label = dg.to_variable(label_data)
weight = dg.to_variable(weight_data)
loss = paddle.nn.SmoothL1Loss()
output = loss(input, label)
print(output.numpy())