Created by: MrChengmo
PR types
New features
PR changes
OPs,Others
Describe
更新点
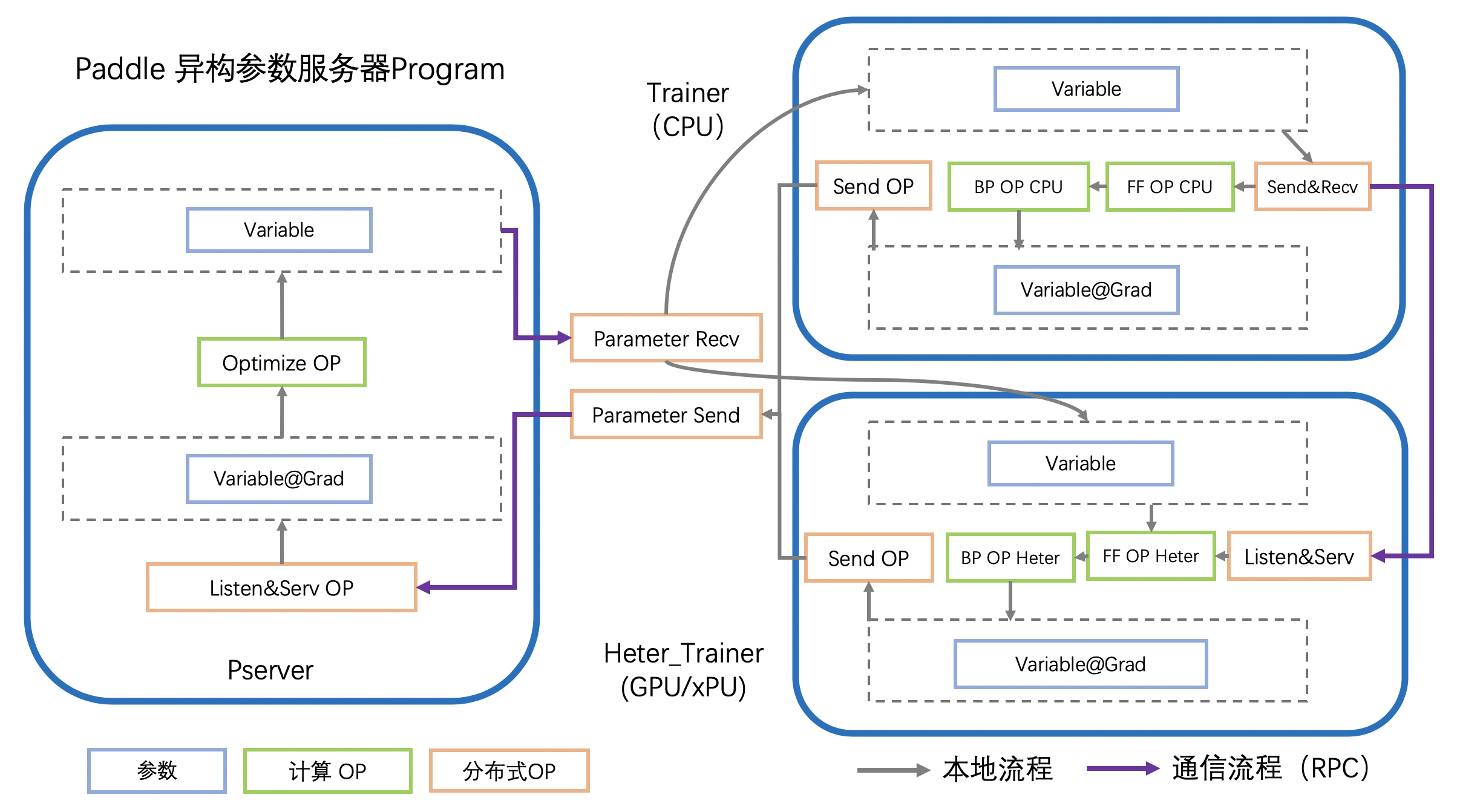
- 支持基于异构设备的参数服务器模式分布式训练
- 支持多模型多设备的异构计算图切分
- 支持异构设备间严格的batch级通信,加入
SendAndRecv op,在一个OP中完成发送与接收,确保上下文的Variable一致 - 在fleet.base中增加对异构的私有化方法支持
-
PaddleCloudRoleMaker支持HETER_TRAINER角色的 初始化 - 重命名
ParameterServerOptimizer、ParameterServerGraphOptimizer - 参数服务器配置
CompileTimeStrategy支持单例模式 - 增加HeterParameterServer一个端到端单测,一个Program单测
- 增加GRPC: SendAndRecv 单测
- 增加若干Debug所需VLOG
使用示例
- 组网示例,需求:将数据IO及查表放到CPU设备,计算部分放到GPU设备
def network():
dense_data = fluid.data(name="dense_input",
shape=[None, dense_data_dim],
dtype="float32")
sparse_input_ids = fluid.data(name="sparse_intput",
shape=[None, 1],
lod_level=1,
dtype="int64")
labels = fluid.data(name="label", shape=[None, 1], dtype="float32")
# 查表在CPU设备执行,可以手动添加device_guard("cpu"), 若不添加,默认放在CPU设备上
# with fluid.device_guard("cpu"):
emb = fluid.layers.embedding(input=sparse_input_ids,
is_sparse=True,
size=[emb_nums, emb_shape])
concated = fluid.layers.concat([dense_data, emb], axis=-1)
# 计算密集型OP放到GPU设备上执行
with fluid.device_guard("gpu"):
pred = fluid.layers.fc(
input=concated,
size=2,
act="relu"
)
cost = fluid.layers.cross_entropy(input=pred, label=labels)
return cost- 运行逻辑示例 run.py
import paddle.distributed.fleet.base.role_maker as role_maker
from paddle.distributed.fleet.base.util_factory import fleet_util
from paddle.distributed.fleet import fleet
# 根据环境变量确定当前机器/进程在分布式训练中扮演的角色
# 然后使用 fleet api的 init()方法初始化这个节点
role = role_maker.PaddleCloudRoleMaker()
fleet.init(role)
# 我们还可以进一步指定分布式的运行模式,通过 DistributeTranspilerConfig进行配置
# 如下,我们设置分布式运行模式为异步(async),同时将参数进行切分,以分配到不同的节点
strategy = paddle.distributed.fleet.DistributedStrategy()
strategy.a_sync = True
cost = network()
optimizer = fluid.optimizer.Adam(args.learning_rate)
optimizer = fleet.distributed_optimizer(optimizer, strategy)
optimizer.minimize(cost)
if fleet.is_server():
# 初始化及运行参数服务器节点
# 异构设备 Heter-Trainer 也被视为服务器,在远程开启监听
fleet.init_server()
fleet.run_server()
else:
# 初始化 CPU-Trainer 节点
fleet.init_worker()
exe = fluid.Executor(fluid.CPUPlace())
# 执行参数初始化
exe.run(fluid.default_startup_program())
# 开始训练
for epoch in range(epochs):
exe.run(fluid.default_main_program())
fleet.stop_worker()- 启动方式示例
以单机通过多进程模拟异构参数服务器为场景,给出异构参数服务器的启动示例
# server 的 endpoints 设置
export PADDLE_PSERVERS_IP_PORT_LIST="127.0.0.1:49011,127.0.0.1:49013"
export PADDLE_PSERVER_PORT_ARRAY=(49011 49013)
# heter-trainer 的 endpoints 及 设备设置
export PADDLE_HETER_TRAINER_IP_PORT_LIST="127.0.0.1:49012,127.0.0.1:49014"
export PADDLE_HETER_PORT_ARRAY=(49012 49014)
export PADDLE_HETER_TRAINER_DEVICE=gpu
# cpu-trainer 的endpoints 设置
export PADDLE_TRAINER_ENDPOINTS="127.0.0.1:49015,127.0.0.1:49016"
# 分别启动server、 cpu-trainer、heter-trianer的进程
export PADDLE_PSERVER_NUMS=2
export PADDLE_TRAINERS_NUM=2
export PADDLE_HETER_TRAINERS=2
# 启动Server,配置角色为PSERVER,同时配置端口和IP
export TRAINING_ROLE=PSERVER
for((i=0;i<$PADDLE_PSERVER_NUMS;i++))
do
cur_port=${PADDLE_PSERVER_PORT_ARRAY[$i]}
echo "PADDLE WILL START PSERVER "$cur_port
export PADDLE_PORT=${cur_port}
export POD_IP=127.0.0.1
python -u train.py 2 &> ./pserver.$i.log &
done
# 启动Cpu-Trainer,配置角色为TRAINER,同时配置 TRAINER_ID
export TRAINING_ROLE=TRAINER
for((i=0;i<$PADDLE_TRAINERS_NUM;i++))
do
echo "PADDLE WILL START Trainer "$i
export PADDLE_TRAINER_ID=$i
python -u train.py &> ./trainer.$i.log &
done
# 启动Heter-Trainer, 配置角色为HETER_TRAINER,同时配置端口、IP以及使用的GPU卡号
export TRAINING_ROLE=HETER_TRAINER
for((i=0;i<$PADDLE_HETER_TRAINERS;i++))
do
cur_port=${PADDLE_HETER_PORT_ARRAY[$i]}
echo "PADDLE WILL START HETER Trainer "$cur_port
export PADDLE_PORT=${cur_port}
export FLAGS_selected_gpus=$i
export POD_IP=127.0.0.1
python -u train.py &> ./heter_trainer.$i.log &
done异构参数服务器简介
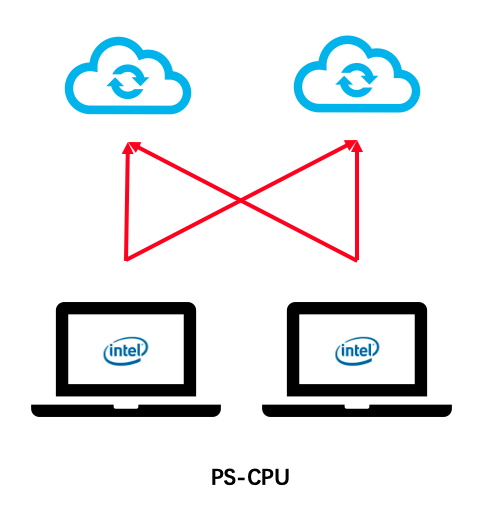
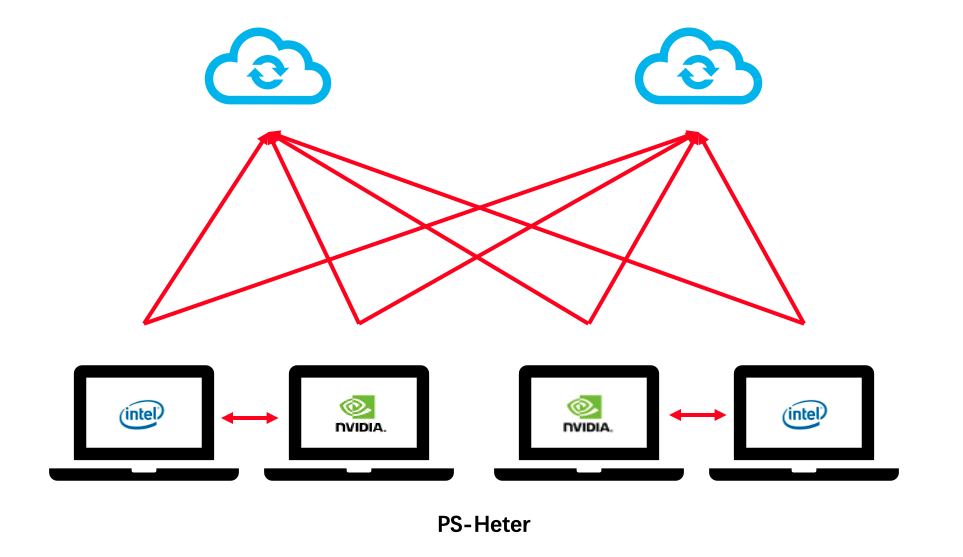
异构参数服务器拓扑图
- 基于CPU的参数服务器
- 异构参数服务器
异构参数服务器运行流程