Created by: zhiqiu
PR types
New features
PR changes
APIs
Describe
Introduce Auto-Mixed Precision(AMP) in imperative mode.
Backgroud
AMP uses both single-precision and half-precision representations of floating number automatically to achieve high performance training and inference.
As Nvidia says,
Benefits of Mixed precision training
- Speeds up math-intensive operations, such as linear and convolution layers, by using Tensor Cores.
- Speeds up memory-limited operations by accessing half the bytes compared to single-precision.
- Reduces memory requirements for training models, enabling larger models or larger minibatches.
Implementation
AMP mainly contains two phases.
- Auto-casting tensor data type
For each executed operator in the model, the AutoCast module will automatically decide which data type is better to use, i.e.,
float16 (half precision)orfloat32 (single precision). The decision is made with white_op_list (which contains the operators that can adopt float16 calculation to accelerate and are considered numerically-safe) and black_op_list (which contains the operators that are considered numerically-safe using float16). As the following figures show.
(a)A example of original execution
 (b) A example of execution with
(b) A example of execution with amp_guard(True)
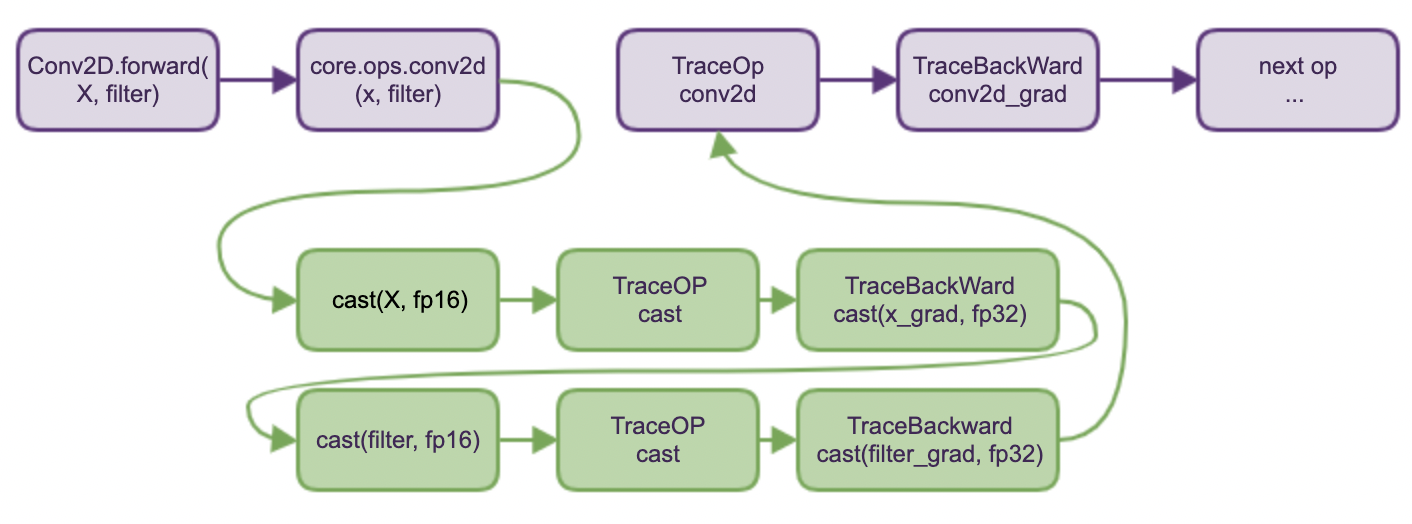
fluid.dygraph.amp_guard() is used to provide context that will enable auto-casting tensor.
Example,
with fluid.dygraph.amp_guard():
loss = model(inputs) # the operators in model will be casted automatically- Scaling loss
Float16 has narrower representation range than float32, as the figure (from Nvidia doc) below shows.

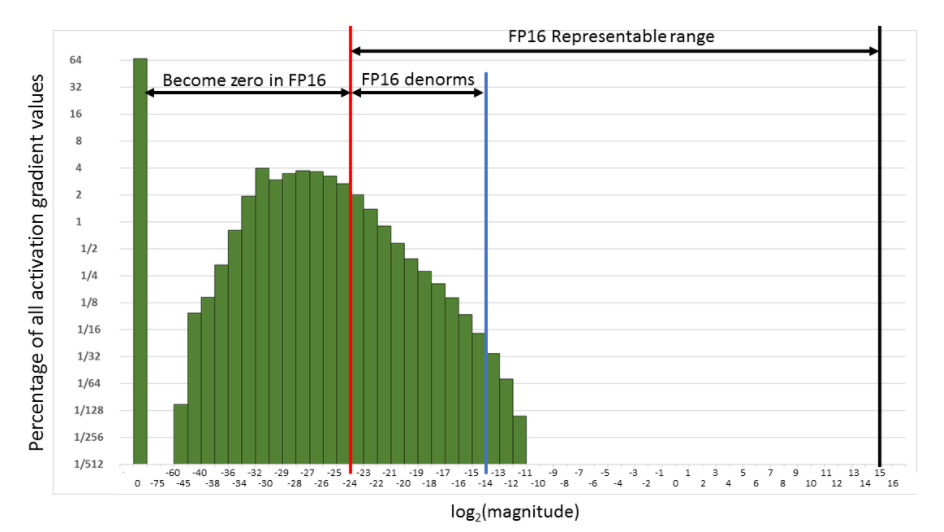
The small gradients may becomes zero (out of representation range) when using float16, so we need to 'shift' the gradients into representation range of float16, which means loss scaling.
The procedure of loss scaling is,
(1) firstly, scales the loss by a factor, for example, multiply 1024,
(2) then, performs backward propagation on scaled loss,
(3) after that, un-scale the gradients, which means, multiply 1/1024,
(4) finally, update parameters with un-scaled gradients.
fluid.dygraph.AmpScaler() is provided to manage the loss scaling.
Example,
scaler = fluid.dygraph.AmpScaler() # initialize a scaler
sgd = fluid.SGDOptimizer()
with fluid.dygraph.amp_guard(): # enable amp
loss = model(inputs)
scaled = scaler.scale(loss) # scale the loss
scaled.backward() # run backward on scaled loss
scaler.minimize(sgd, scaled) # update the parametersRelated #24875, #24823