Created by: Aurelius84
1. 背景
框架目前通过@declarative对动态图forward函数添加装饰,可以将网络转为静态图执行。但需要对train函数代码进行部分改写,放到fluid.program_guard语法下进行训练。
在动转静训练时,为了尽可能避免代码的修改,提升@declarative的易用性,将@declarative下的所有layers涉及的op转换为静态图模式执行。
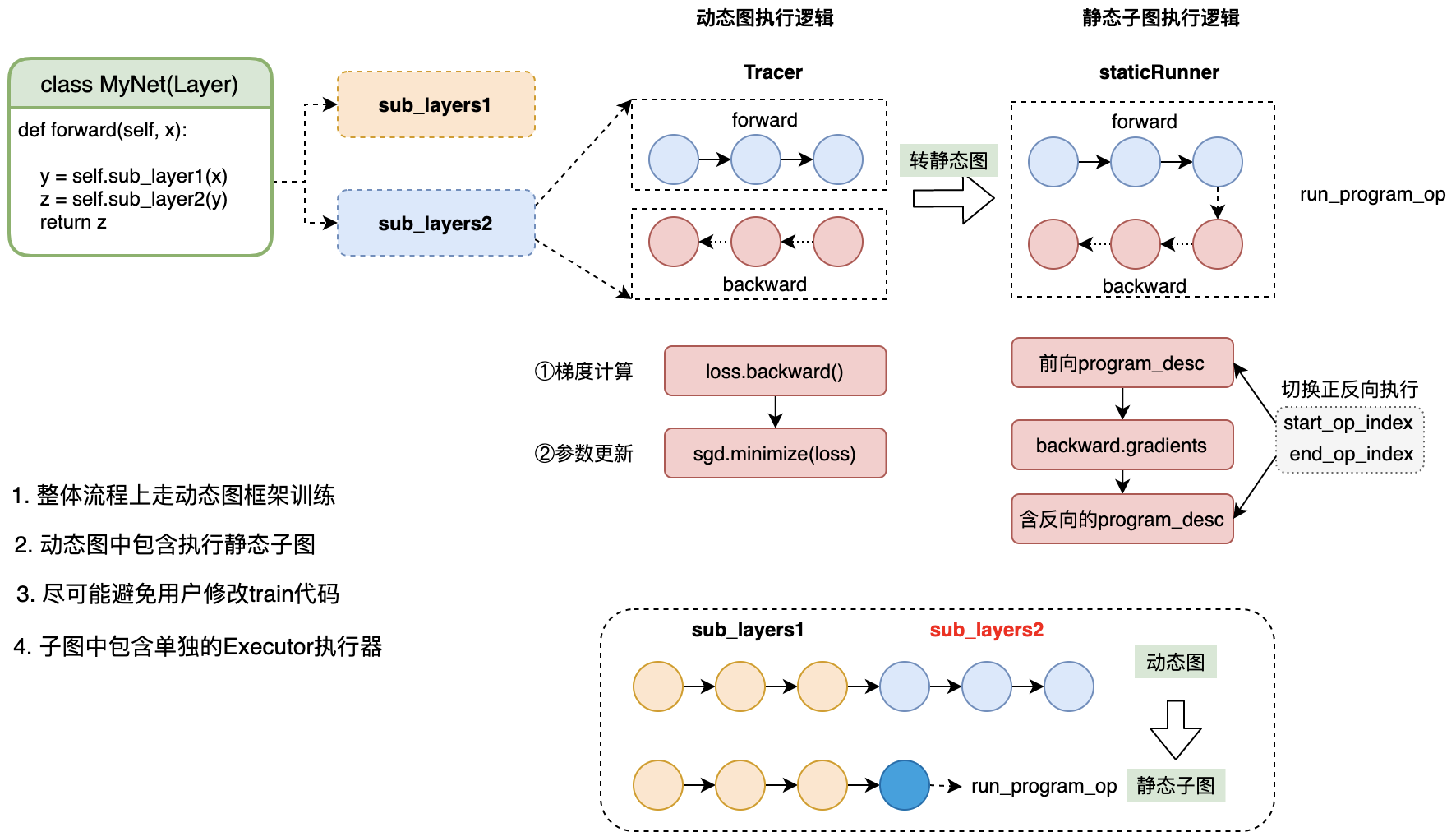
2. 基本原理
- 复用动态图的Trace执行流程,将被转为静态图的所有op,放到单独的子Program里
- 解析子Program中Ops,组网并放到
run_program_op进行trace,进行前向计算,并添加反向
如上图所示,sub_layers中的所有的ops计算都会放进run_program_op里。在执行sub_layers时,通过Trace run_program_op动态执行所有子Program前向ops。
在反向计算时,借助静态图的fluid.gradients接口,在子Program中添加反向grad_op。当执行loss.backward()时,会调用run_program_op的GradKernel,依次调用子Program中的grad_op Kernel计算grad。
Example:
class Linear(fluid.dygraph.Layer):
def __init__(self, input_dim=10, output_dim=5):
super(Linear, self).__init__()
self.fc = fluid.dygraph.Linear(input_dim, output_dim, act='relu')
@declarative # 添加装饰器
def forward(self, x):
pre = self.fc(x)
loss = fluid.layers.mean(pre)
return pre, loss
# 训练代码不需要做任何改动
def train(self, to_static=False):
batch_num = 10
with fluid.dygraph.guard(fluid.CPUPlace()):
net = Linear()
adam = fluid.optimizer.AdamOptimizer(learning_rate=0.1, parameter_list=net.parameters())
for batch_id in range(batch_num):
input = fluid.dygraph.to_variable(batch_data)
pred, avg_loss = net(input)
avg_loss.backward()
adam.minimize(avg_loss)
dygraph_net.clear_gradients()
# 保存训练好的模型参数
fluid.save_dygraph(net.state_dict(), "./test_dy2stat_save_load")
infer_net = Linear()
# 加载训练好的参数,进行预测
model_dict, _ = fluid.load_dygraph("./test_dy2stat_save_load")
infer_net.set_dict(model_dict)
pred, _ = infer_net(x)3. PR内容
新增
- 针对旧
declarative动转静训练,需手动改写train函数的问题,支持不需改写任何训练代码,只需在forward函数添加declarative即可转为静态图执行。 - 支持在模型入口和局部
forward函数添加declarative,转为静态子图执行。 - 支持模型
train/eval模式切换
优化
-
run_program_op的反向kernel计算后,将TensorCopy改为ShareDataWith,减少数据复制开销。 - 针对python2下
convert_call无法获取带装饰器的function原始code问题,进行修复,通过__wrapped__属性解析。 - 针对输入参数强依赖于
to_variable(x)语句来判断是否构建feed layers的问题,移除了对to_variable的依赖,可以通过VarBase/Variable/Numpy.ndarry进行解析创建。 - 替换单测文件中
dygraph_to_static_func为declarative,增加对declarative新逻辑的测试,逐步移除旧dygraph_to_static_func接口,包括MNIST、seResnet、ptb_lm动态图模型单测。 - 添加动转静后
fluid.save_dygraph和fluid.load_dygraph模型参数保存和加载后,预测结果的正确性。
移除
- 移除了
Program_translator内的部分旧接口- 移除了旧的
set_optimizer接口,支持训练代码不要用户修改,减少用户使用成本 - 移除了
save_inference_model接口,统一模型训练参数save/load与动态图使用方式一致,即可以直接使用fluid.save_dygraph和fluid.load_dygraph保存网络参数。
- 移除了旧的
- 移除了
convert_call中对Python2和Python3的不同分支逻辑判断,精简了递归转化逻辑
TODO:
- 暂不支持动静转换邻接layers传递LoDTensorArray类型的vars;
- 不支持被装饰函数内定义带参数layer,会显示提示用户不允许(需将此部分layer放到
__init__函数)