Created by: Shixiaowei02
本提交增加用户接口,使预测线程可绑定单独的 GPU 流。
【注意】
目前的 Paddle 实现中,GPU 流绑定线程的动作是在构造新的 PaddlePredictor 对象,即调用 CreatePaddlePredictor() 或 PaddlePredictor::Clone() 时完成的。所以使用多流,需同时满足下列条件:
- 调用
AnalysisConfig::EnableGpuMultiStream()生效配置; - 生成(或克隆生成)
PaddlePredictor对象时,所在线程与执行PaddlePredictor::Run()或PaddlePredictor::ZeroCopyRun()预测时所在的线程一致。
若未满足上述约定,多流配置将失效:线程不再绑定 GPU 流,但预测结果不受影响。 目前 Paddle 底层已支持 GPU 流优先级,但用户接口还未确定。
配置示例:
#include <glog/logging.h>
#include "paddle_inference_api.h"
namespace paddle {
std::unique_ptr<PaddlePredictor> create_predictor(const std::string& dir,
bool use_gpu,
bool thread_stream) {
AnalysisConfig config;
config.SetModel(dir);
if (use_gpu) {
config.EnableUseGpu(100 /* 缓存大小 */, 0 /* 设备号 */);
}
if (thread_stream) {
// 各线程 AnalysisPredictor::Run() 使用独立 GPU 流,不再共用。
// 缓存大小从“进程独占值”变成“线程独占值”。
config.EnableGpuMultiStream();
CHECK_EQ(use_gpu, true);
}
return CreatePaddlePredictor<AnalysisConfig>(config);
}
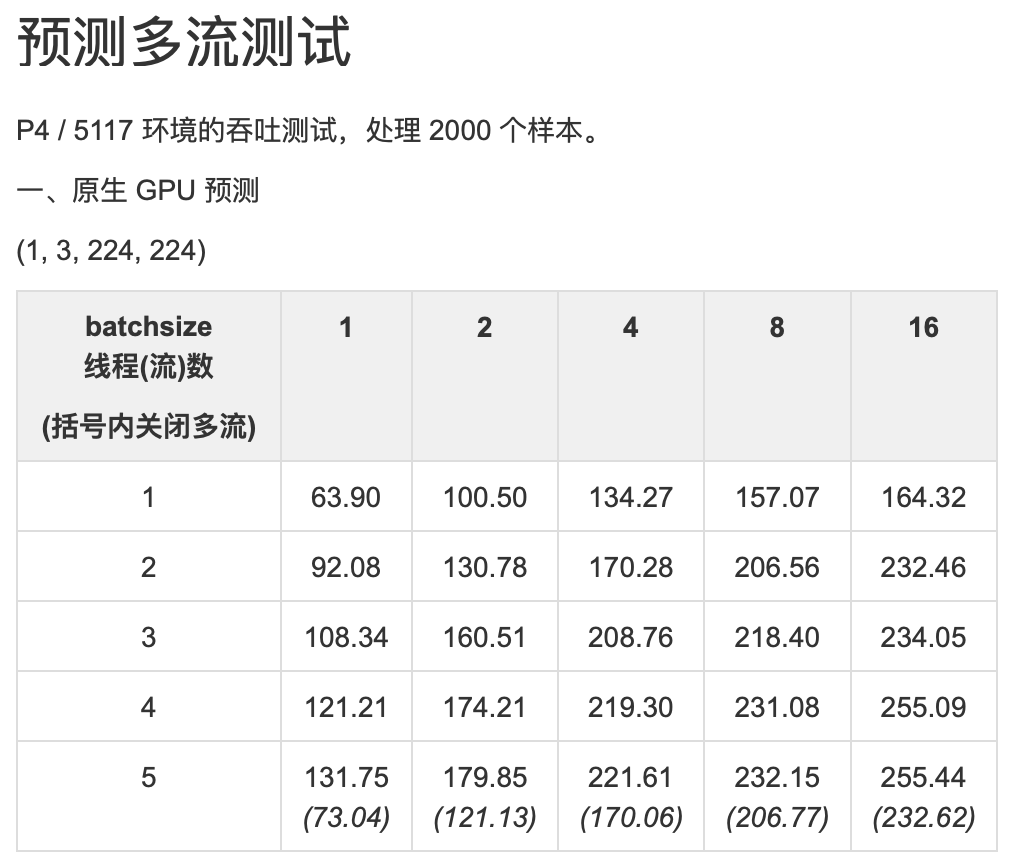
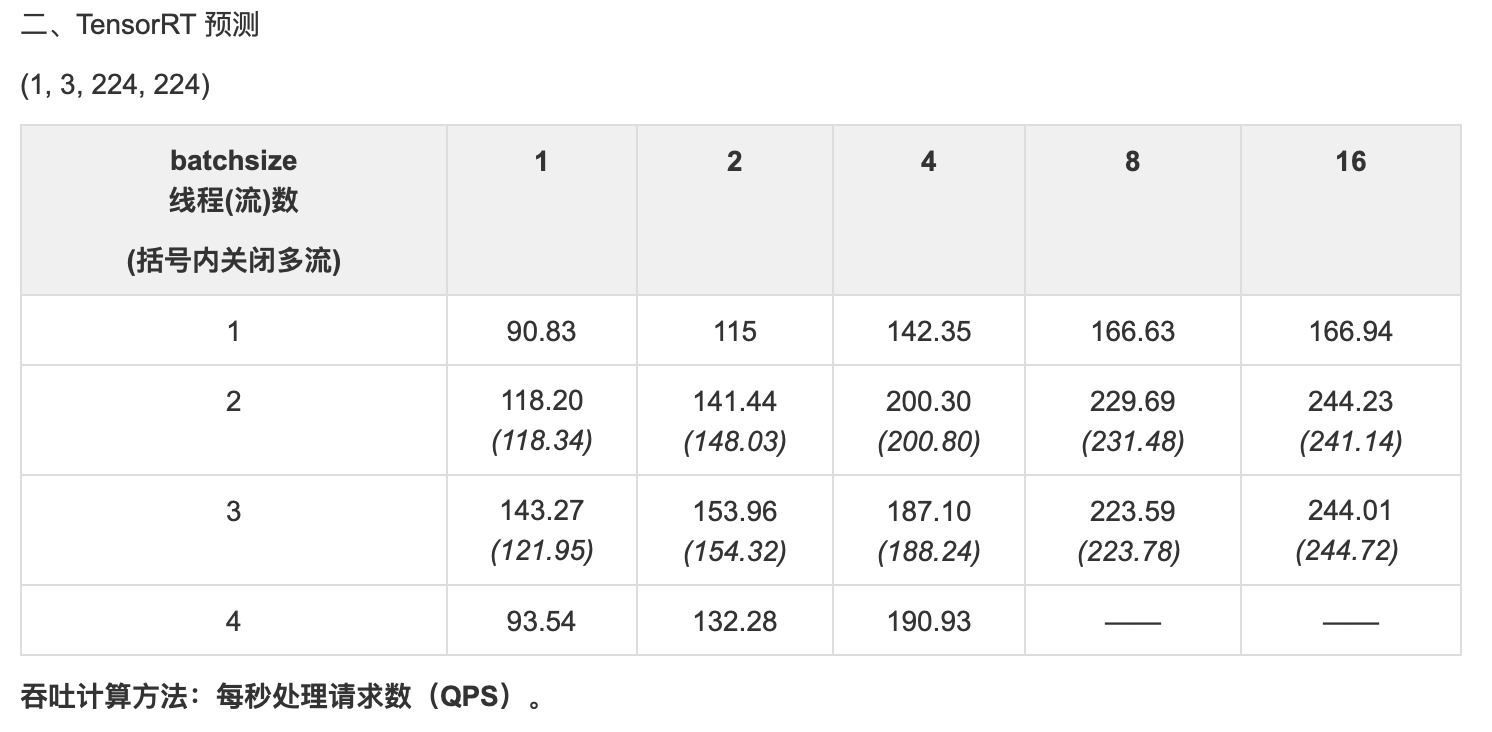
} // namespace paddleResNet 测试: