Created by: guoshengCS
Add cholesky_op
预览暂时放在了paddle.fluid.layers下
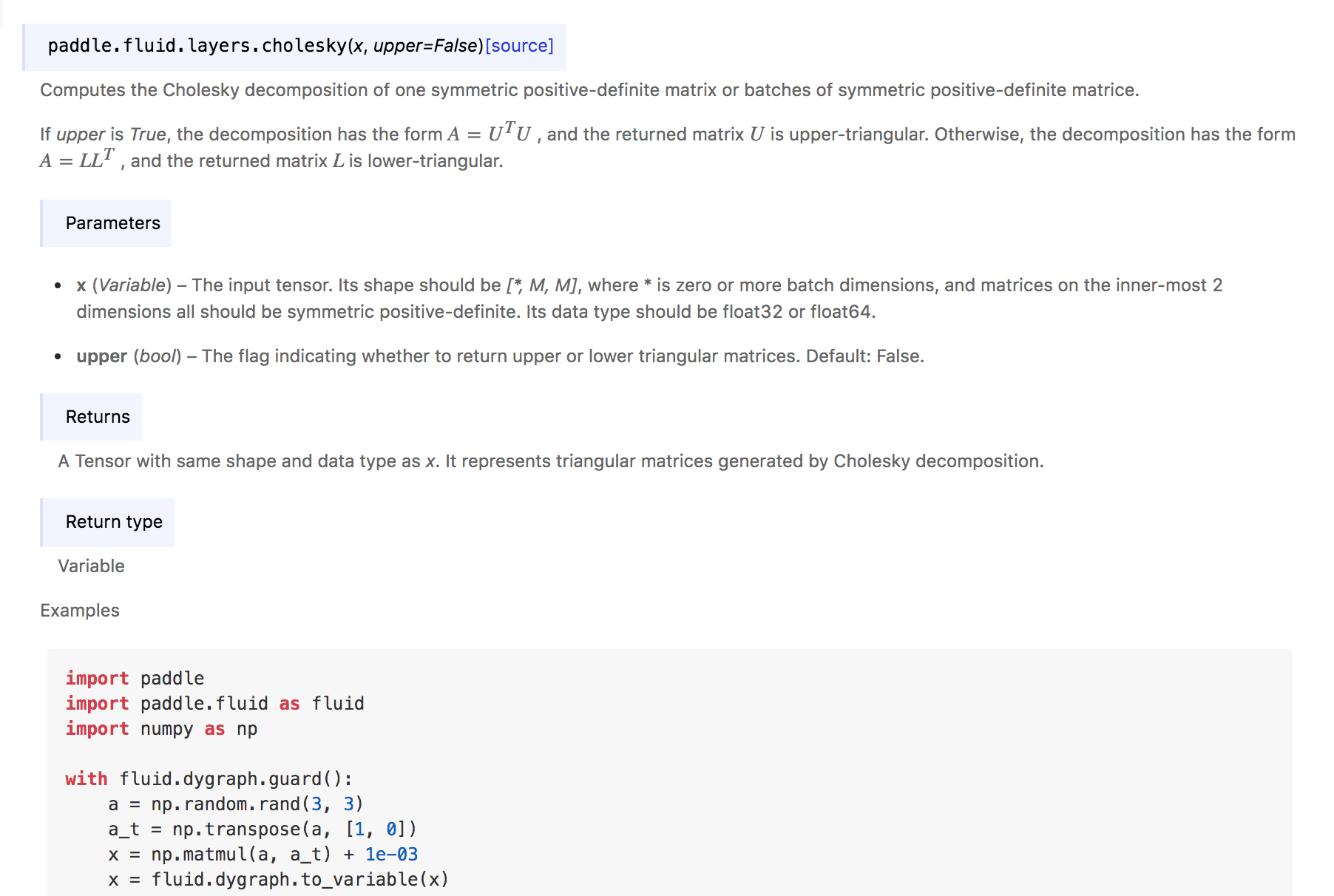
由于无法使用OpTest来进行梯度检查,换用gradient_checker.grad_check进行了梯度检查。另外进行了对比测试,测试脚本如下
import numpy as np
use_gpu = True
np.random.seed(1000)
a = np.random.rand(2, 1, 3, 3).astype("float64")
rank = len(a.shape)
a_t = a.transpose(list(range(rank-2)) + [rank-1, rank-2])
a = np.matmul(a, a_t) + 1e-03
inp = a
import paddle
import paddle.fluid as fluid
from paddle.fluid.dygraph.base import to_variable
place = fluid.CUDAPlace(0) if use_gpu else fluid.CPUPlace()
fluid.enable_dygraph(place)
x = to_variable(inp)
x.stop_gradient = False
l = paddle.cholesky(x, upper=False)
loss = fluid.layers.reduce_sum(l, dim=list(range(rank)))
loss.backward()
pd_values = (l.numpy(), x._grad_ivar().numpy())
import tensorflow as tf
gpus = tf.config.experimental.list_physical_devices('GPU')
if gpus:
try:
# Currently, memory growth needs to be the same across GPUs
for gpu in gpus:
tf.config.experimental.set_memory_growth(gpu, True)
except RuntimeError as e:
# Memory growth must be set before GPUs have been initialized
print(e)
with tf.device('/GPU:0' if use_gpu else '/CPU:0'):
with tf.GradientTape() as tape:
x = tf.Variable(inp)
l = tf.linalg.cholesky(x)
loss = tf.math.reduce_sum(l)
grad = tape.gradient(loss, x)
tf_values = (l.numpy(), grad.numpy())
assert np.allclose(pd_values[0], tf_values[0], rtol=1e-07, atol=1e-08)
assert np.allclose(pd_values[1], tf_values[1], rtol=1e-07, atol=1e-08)
import torch
x = torch.Tensor(inp).cuda() if use_gpu else torch.Tensor(inp)
x.requires_grad=True
l = torch.cholesky(x, upper=False)
loss = l.sum()
loss.backward()
torch_values = (l.cpu().detach().numpy(), x.grad.cpu().numpy())
assert np.allclose(pd_values[0], torch_values[0], rtol=1e-07, atol=1e-08)
assert np.allclose(pd_values[1], torch_values[1], rtol=1e-05, atol=1e-08)
print(torch_values[1])
print(pd_values[1])