Created by: Shixiaowei02
[cherry-pick from #22444 ]
本提交包含两部分:
1、Python 接口支持从内存存取预测模型,以满足加解密需求。
load_inference_model(dirname, executor, model_filename=None, params_filename=None, pserver_endpoints=None)
当 dirname 为 None 时,可向 model_filename 和 params_filename 分别传递包含模型和参数的字符串,实现模型内存读取。
save_persistables(executor, dirname, main_program=None, filename=None)
当 dirname 和 filename 为 None 时,save_persistables 将返回参数字符串,而不再将模型文件存盘。
上述改动涉及到 save_vars、save_params 的返回值变化,和 load_vars 的参数含义的增加。本改动是向后兼容的。
2、不再向预测模型添加 Scale 层。
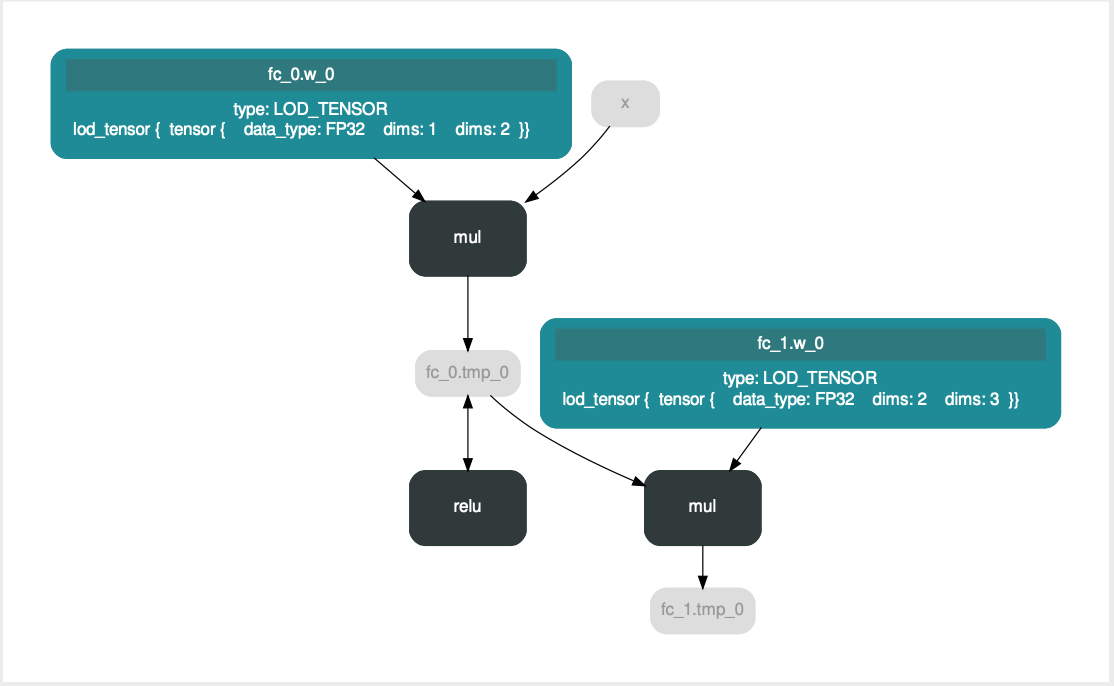
较旧的 Fluid 版本中 activation helper 会添加 inplace 算子,裁剪时可能会错误地将模型最后的 activation 舍弃(https://github.com/PaddlePaddle/Paddle/pull/9740 https://github.com/PaddlePaddle/Paddle/issues/12609 );如上图最后一层 mul 之后原应存在的 relu 层。为规避此问题,保存预测模型时添加了一个 scale 层(https://github.com/PaddlePaddle/Paddle/pull/15365 ),但这改变了原有的模型结构。
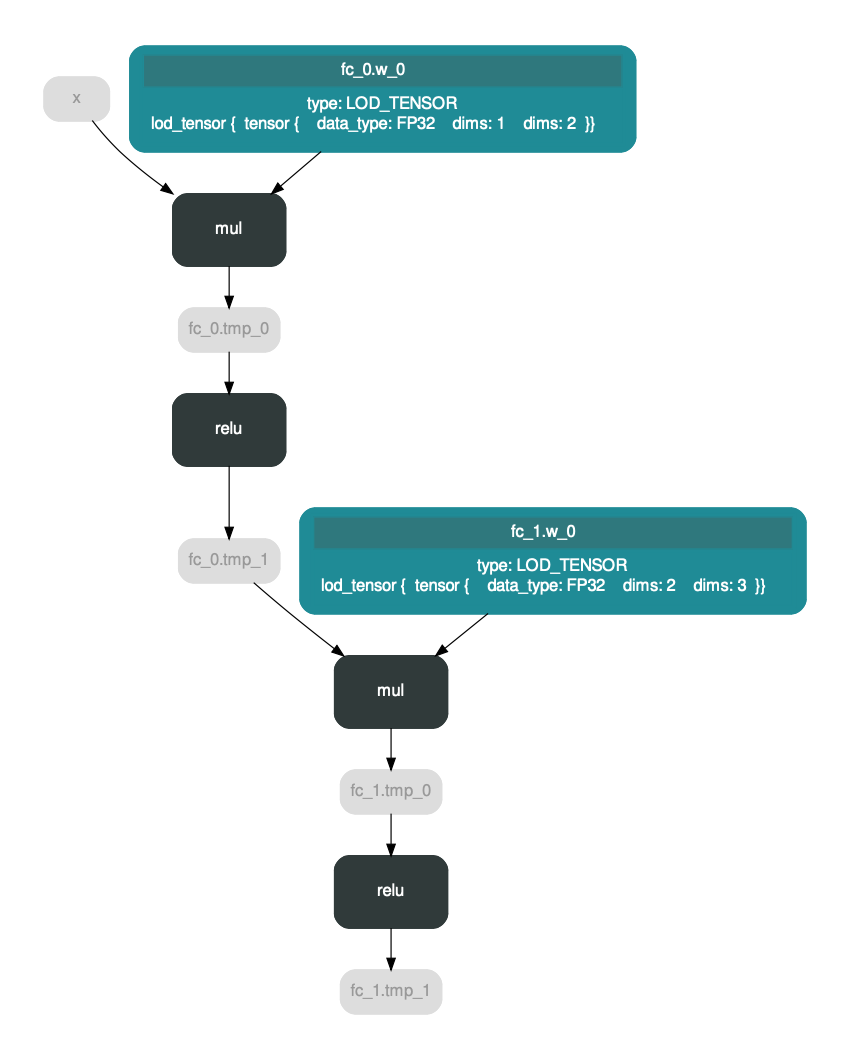
如上图,现在 https://github.com/PaddlePaddle/Paddle/pull/16410 禁用了原地激活,此问题不再存在;所以删除这部分临时代码。
在修改过程中,在 develop 分支发现了一个 mkldnn_conv_relu_fuse_pass 的原有 bug,@FrostML 排查修复中。