mse cost的大小与模型输出维度是否有关?error clipping 输出日志该如何理解?
Created by: dockiHan
最近使用栈式LSTM做回归模型,遇到了一些棘手的问题,还请帮忙解答一下:
-
paddlepaddle 0.10.0版本中mse_cost对于多维度的输入输出是如何计算的? 假如output dim = M, 每个batch 有N个sample。

batch cost的计算是左边的公式还是右边的?
-
error clipping的输出日志中的max error 和avg error该如何理解? error 指的是不是当前层的梯度?那么最大和平均该如何理解呢,是指一个batch size中的最大梯度和平均梯度吗?
-
对于输入输出维度都很大的任务(比如100维输入,100维输出的回归任务),batch cost相应也很大(mse batch cost 在500-1000范围),请问error clipping的threshold是否应当相应的设高一些?有没有其他比较好的办法提高训练效率?(我使用error clipping之后几乎一直在做clip)
-
请问像下面这种查看每层梯度的日志,是怎么打印出来的呢?paddlepaddle中有相应的接口吗?
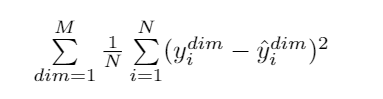
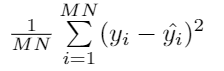
I9070 14:16:39.139219 14922 TrainerInternal.cpp:206] _target_language_word avg_abs_val=0.0770059 max_val=1.16759 avg_abs_grad=295463 max_grad=2.64328e+09
I9070 14:16:39.140857 14922 TrainerInternal.cpp:206] _hidden-q-c1-1.w0 avg_abs_val=0.0247217 max_val=0.148856 avg_abs_grad=8.24642e+06 max_grad=2.97277e+08
I9070 14:16:39.140946 14922 TrainerInternal.cpp:206] _hidden-q-c1-1.wbias avg_abs_val=0.0134427 max_val=0.0558094 avg_abs_grad=2.8694e+08 max_grad=3.4266e+09
I9070 14:16:39.146185 14922 TrainerInternal.cpp:206] _lstm-q-c1-1.w0 avg_abs_val=0.0233535 max_val=0.070686 avg_abs_grad=2.97016e+06 max_grad=1.92164e+08
I9070 14:16:39.146267 14922 TrainerInternal.cpp:206] _lstm-q-c1-1.wbias avg_abs_val=0.0242056 max_val=0.0673774 avg_abs_grad=1.02841e+08 max_grad=2.80652e+09
I9070 14:16:39.156641 14922 TrainerInternal.cpp:206] _hidden-q-c1-2.w0 avg_abs_val=0.0176564 max_val=0.111266 avg_abs_grad=1.52075e+07 max_grad=6.61996e+08
I9070 14:16:39.161865 14922 TrainerInternal.cpp:206] _hidden-q-c1-2.w1 avg_abs_val=0.0137717 max_val=0.068213 avg_abs_grad=3.8464e+06 max_grad=2.14835e+08
I9070 14:16:39.161944 14922 TrainerInternal.cpp:206] _hidden-q-c1-2.wbias avg_abs_val=0.000861888 max_val=0.00452402 avg_abs_grad=1.56843e+08 max_grad=1.63732e+09
I9070 14:16:39.167181 14922 TrainerInternal.cpp:206] _lstm-q-c1-2.w0 avg_abs_val=0.0118875 max_val=0.0641921 avg_abs_grad=4.98832e+06 max_grad=4.02445e+08
I9070 14:16:39.167268 14922 TrainerInternal.cpp:206] _lstm-q-c1-2.wbias avg_abs_val=0.0135908 max_val=0.0565502 avg_abs_grad=3.32067e+07 max_grad=1.26415e+09
I9070 14:16:39.170172 14922 TrainerInternal.cpp:206] _lstmRA-q-seq-proj.w0 avg_abs_val=0.0208607 max_val=0.121019 avg_abs_grad=3.57133e+06 max_grad=1.61502e+08
I9070 14:16:39.171003 14922 TrainerInternal.cpp:206] _decoder_state_projected@decoding_layer_group.w0 avg_abs_val=0.0181545 max_val=0.113313 avg_abs_grad=3.72381e+07 max_grad=4.94205e+08
I9070 14:16:39.171075 14922 TrainerInternal.cpp:206] _attention_weight@decoding_layer_group.w0 avg_abs_val=0.0182074 max_val=0.0841638 avg_abs_grad=3.48112e+10 max_grad=4.07161e+10
I9070 14:16:39.186594 14922 TrainerInternal.cpp:206] _decoder_input_recurrent01@decoding_layer_group.w0 avg_abs_val=0.0225219 max_val=0.203654 avg_abs_grad=1.7084e+06 max_grad=4.21574e+08
I9070 14:16:39.188189 14922 TrainerInternal.cpp:206] _decoder_input_recurrent01@decoding_layer_group.w1 avg_abs_val=0.0275065 max_val=1.44036 avg_abs_grad=408947 max_grad=3.82036e+07
I9070 14:16:39.193428 14922 TrainerInternal.cpp:206] decoder_unit01_input_recurrent.w avg_abs_val=0.0223694 max_val=0.199234 avg_abs_grad=847175 max_grad=5.24993e+07
I9070 14:16:39.193506 14922 TrainerInternal.cpp:206] decoder_unit01_input_recurrent.b avg_abs_val=0.011857 max_val=0.0528973 avg_abs_grad=9.09628e+06 max_grad=4.0061e+08
I9070 14:16:39.193576 14922 TrainerInternal.cpp:206] decoder_unit01_check.b avg_abs_val=0.0238234 max_val=0.118872 avg_abs_grad=2.65984e+06 max_grad=5.55707e+07
I9070 14:16:39.214248 14922 TrainerInternal.cpp:206] _decoder_input_recurrent02@decoding_layer_group.w0 avg_abs_val=0.0234653 max_val=1.23594 avg_abs_grad=0.789756 max_grad=377.925
I9070 14:16:39.219485 14922 TrainerInternal.cpp:206] _decoder_input_recurrent02@decoding_layer_group.w1 avg_abs_val=0.0728412 max_val=1.79231 avg_abs_grad=0.220619 max_grad=43.2564
I9070 14:16:39.224725 14922 TrainerInternal.cpp:206] decoder_unit02_input_recurrent.w avg_abs_val=0.145413 max_val=4.16184 avg_abs_grad=0.193137 max_grad=44.0683
I9070 14:16:39.224800 14922 TrainerInternal.cpp:206] decoder_unit02_input_recurrent.b avg_abs_val=0.180045 max_val=1.68827 avg_abs_grad=1.1645 max_grad=48.7926
I9070 14:16:39.224876 14922 TrainerInternal.cpp:206] decoder_unit02_check.b avg_abs_val=0.177369 max_val=2.48436 avg_abs_grad=2.49318 max_grad=73.1276
I9070 14:16:39.275351 14922 TrainerInternal.cpp:206] _output@decoding_layer_group.w0 avg_abs_val=0.552655 max_val=16.9875 avg_abs_grad=0.0133146 max_grad=82.6964
I9070 14:16:39.275485 14922 TrainerInternal.cpp:206] _output.wbias avg_abs_val=0.0456539 max_val=1.12327 avg_abs_grad=0.0684144 max_grad=69.7974