2.0Beta中自定义分类任务没有复现成功,效果比Fluid版本收敛慢
Created by: GT-ZhangAcer
PaddlePaddle环境:2.0Beta-CPU-pip清华源安装 系统以及Python环境:MAC+Python3.7
代码部分
case1 Fluid版本代码 AI Studio
import paddle.fluid as fluid
import numpy as np
import PIL.Image as Image
data_path = "/home/aistudio/work"
save_model_path = "./model"
# 构建Reader
def switch_reader(is_val: bool = False):
def reader():
# 读取标签数据
with open(data_path + "/OCR_100P.txt", 'r') as f:
labels = f.read()
# 判断是否是验证集
if is_val:
index_range = range(500, 800)
else:
index_range = range(1, 500)
# 抽取数据使用迭代器返回
for index in index_range:
im = Image.open(data_path + "/" + str(index) + ".jpg").convert('L') # 使用Pillow读取图片
im = np.array(im).reshape(1, 1, 30, 15).astype(np.float32) # NCHW格式
im /= 255 # 归一化以提升训练效果
lab = labels[index - 1] # 因为循环中i是从1开始迭代的,所有这里需要减去1
yield im, int(lab)
return reader # 注意!此处不需要带括号
# 划分mini_batch
batch_size = 128
train_reader = fluid.io.batch(reader=switch_reader(), batch_size=batch_size)
val_reader = fluid.io.batch(reader=switch_reader(is_val=True), batch_size=batch_size)
# 定义网络输入格式
img = fluid.data(name="img", shape=[-1, 1, 30, 15], dtype="float32")
label = fluid.data(name='label', shape=[-1, 1], dtype='int64')
# 定义网络
hidden = fluid.layers.fc(input=img, size=200, act='relu')
# 第二个全连接层,激活函数为ReLU
hidden = fluid.layers.fc(input=hidden, size=200, act='relu')
# 以softmax为激活函数的全连接输出层,输出层的大小必须为数字的个数10
net_out = fluid.layers.fc(input=hidden, size=10, act='softmax')
# 使用API来计算正确率
acc = fluid.layers.accuracy(input=net_out, label=label)
# 将上方的结构克隆出来给测试程序使用
eval_prog = fluid.default_main_program().clone(for_test=True)
# 定义损失函数
loss = fluid.layers.cross_entropy(input=net_out, label=label)
avg_loss = fluid.layers.mean(loss)
# 定义优化方法
sgd_optimizer = fluid.optimizer.SGD(learning_rate=0.01)
sgd_optimizer.minimize(avg_loss)
# 定义执行器
place = fluid.CPUPlace()
exe = fluid.Executor(place)
# 数据传入设置
feeder = fluid.DataFeeder(place=place, feed_list=[img, label])
prog = fluid.default_startup_program()
exe.run(prog)
# 开始训练
Epoch = 10
for i in range(Epoch):
batch_loss = None
batch_acc = None
# 训练集 只看loss来判断模型收敛情况
for batch_id, data in enumerate(train_reader()):
outs = exe.run(
feed=feeder.feed(data),
fetch_list=[loss])
batch_loss = np.average(outs[0])
# 验证集 只看准确率来判断收敛情况
for batch_id, data in enumerate(val_reader()):
outs = exe.run(program=eval_prog,
feed=feeder.feed(data),
fetch_list=[acc])
batch_acc = np.average(outs[0])
print("Epoch:", i, "\tLoss:{:3f}".format(batch_loss), "\tAcc:{:2f} %".format(batch_acc * 100))
# 保存模型
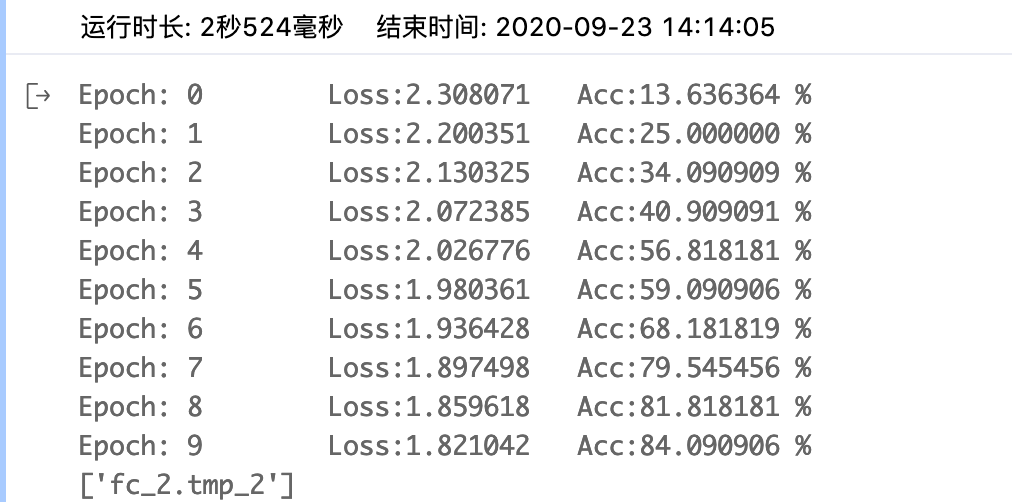
fluid.io.save_inference_model(save_model_path, ['img'], [net_out], exe)该版本在第10个EPOCH后就可以达到较高的准确率
case2 使用2.0Beta的Hapi进行搭建
import os
import paddle as pp
import PIL.Image as Image
import numpy as np
from paddle.io import Dataset
USE_GPU = False
DATA_PATH = "./data"
CLASSIFY_NUM = 10
IMAGE_SHAPE_C = 1
IMAGE_SHAPE_H = 30
IMAGE_SHAPE_W = 15
class Reader(Dataset):
def __init__(self, data_path, add_label: bool = True, is_val: bool = False):
"""
数据读取器
:param data_path: 数据集所在路径
:param add_label: 是否添加label
:param is_val: 是否为评估模式
"""
super().__init__()
self.add_label = add_label
self.img_list = [os.path.join(data_path, str(i) + ".jpg") for i in range(1, 800)]
with open(os.path.join(data_path, "OCR_100P.txt"), 'r') as f:
label_list = f.read()
self.img_list = self.img_list[:500] if not is_val \
else self.img_list[500:800]
self.label_list = label_list[:500] if not is_val \
else label_list[500:800]
print("正在打印", "训练" if not is_val else "验证", "的示例数据,请检查是否对应")
for sample_index in range(3):
self.print_sample(sample_index)
def __getitem__(self, index):
"""
获取一组数据
:param index: 文件索引号
:return:
"""
# 第一步打开图像文件并获取label值
img = Image.open(self.img_list[index]).convert('L')
label = self.label_list[index]
# 第二步做图像增强 - 因本次图片较小,不适合做增强所以跳过
# 第三步转换为Numpy的array格式,并且使用浮点型数据格式,shape转化为CHW(数量、通道数、高、宽)
img = np.array(img, dtype="float32").reshape(1 * 30 * 15)
label = np.array([label], dtype="int64")
# 第四步进行归一化操作方便收敛
img /= 255
return img, label if self.add_label else img
def print_sample(self, index: int = 0):
print("文件名", self.img_list[index], "\t标签值", self.label_list[index])
def __len__(self):
return len(self.img_list)
class Net(pp.nn.Layer):
def __init__(self):
super().__init__()
self.layer1 = pp.nn.Linear(in_features=IMAGE_SHAPE_C * IMAGE_SHAPE_H * IMAGE_SHAPE_W, out_features=200)
self.layer2 = pp.nn.Linear(in_features=200, out_features=200)
self.layer3 = pp.nn.Linear(in_features=200, out_features=CLASSIFY_NUM)
# 定义网络结构的前向计算过程
def forward(self, inputs):
layer1 = pp.nn.functional.relu(self.layer1(inputs))
layer2 = pp.nn.functional.relu(self.layer2(layer1))
layer3 = self.layer3(layer2)
out = pp.nn.functional.softmax(layer3)
return out
input_define = pp.static.InputSpec(shape=[-1, IMAGE_SHAPE_C * IMAGE_SHAPE_H * IMAGE_SHAPE_W],
dtype="float32",
name="img")
label_define = pp.static.InputSpec(shape=[-1, 1],
dtype="int64",
name="label")
model = pp.Model(Net(), inputs=input_define, labels=label_define)
optimizer = pp.optimizer.SGD(learning_rate=0.01, parameters=model.parameters())
model.prepare(optimizer=optimizer,
loss=pp.nn.loss.CrossEntropyLoss(),
metrics=pp.metric.Accuracy(topk=(1, 2)))
model.fit(train_data=Reader(data_path=DATA_PATH),
batch_size=16,
epochs=100,
save_dir="output/",
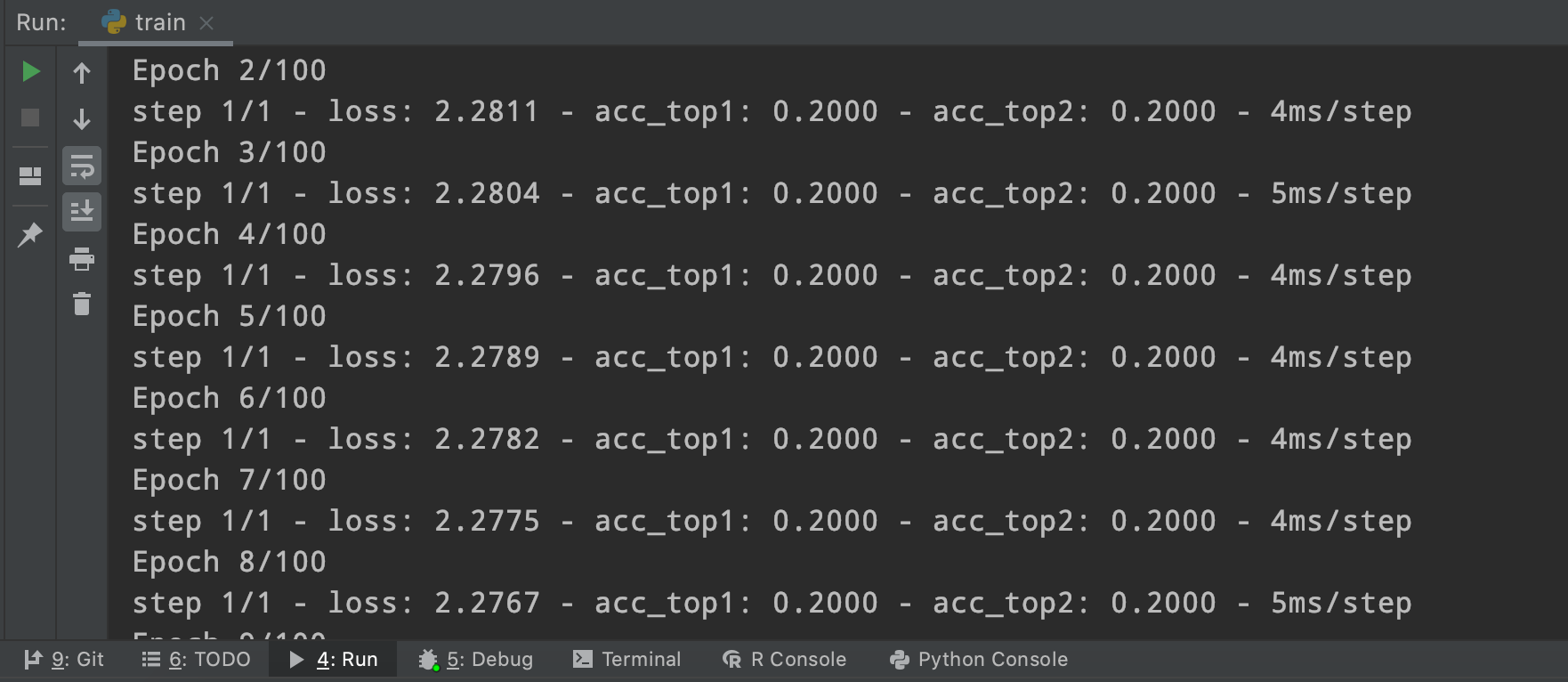
save_freq=10)该版本在Batch_size为128时效果为:
该版本在Batch_size为1时效果为:
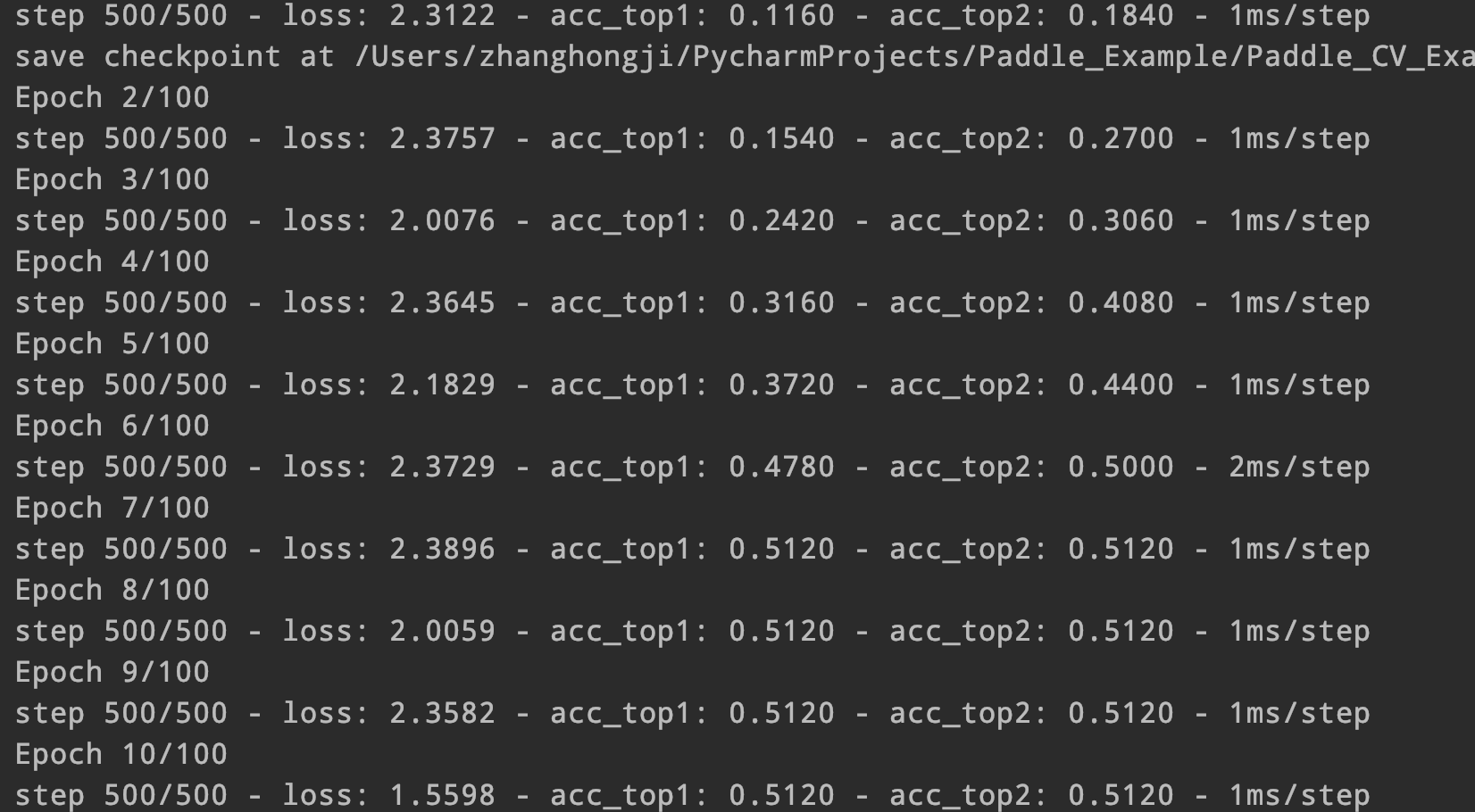
没能收敛好,感觉可能是自己代码某个地方漏掉了什么,希望可以得到大佬帮助~