fluid1.8.2 GPU+CPU联合训练
Created by: HsiaChubby
在使用fluid.1.8.2版本进行GPU与CPU混合训练模型:
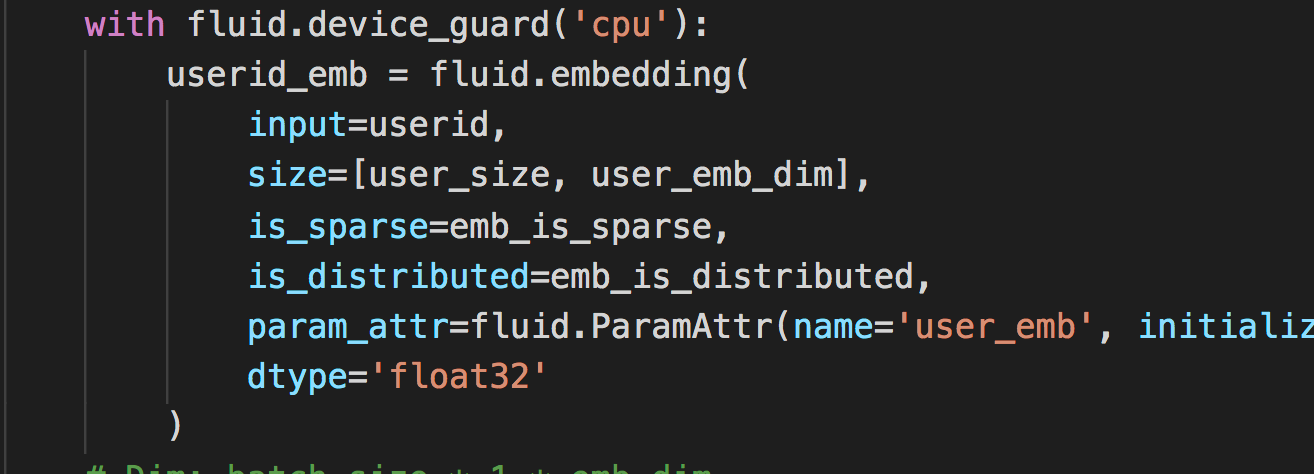
训练过程如下:
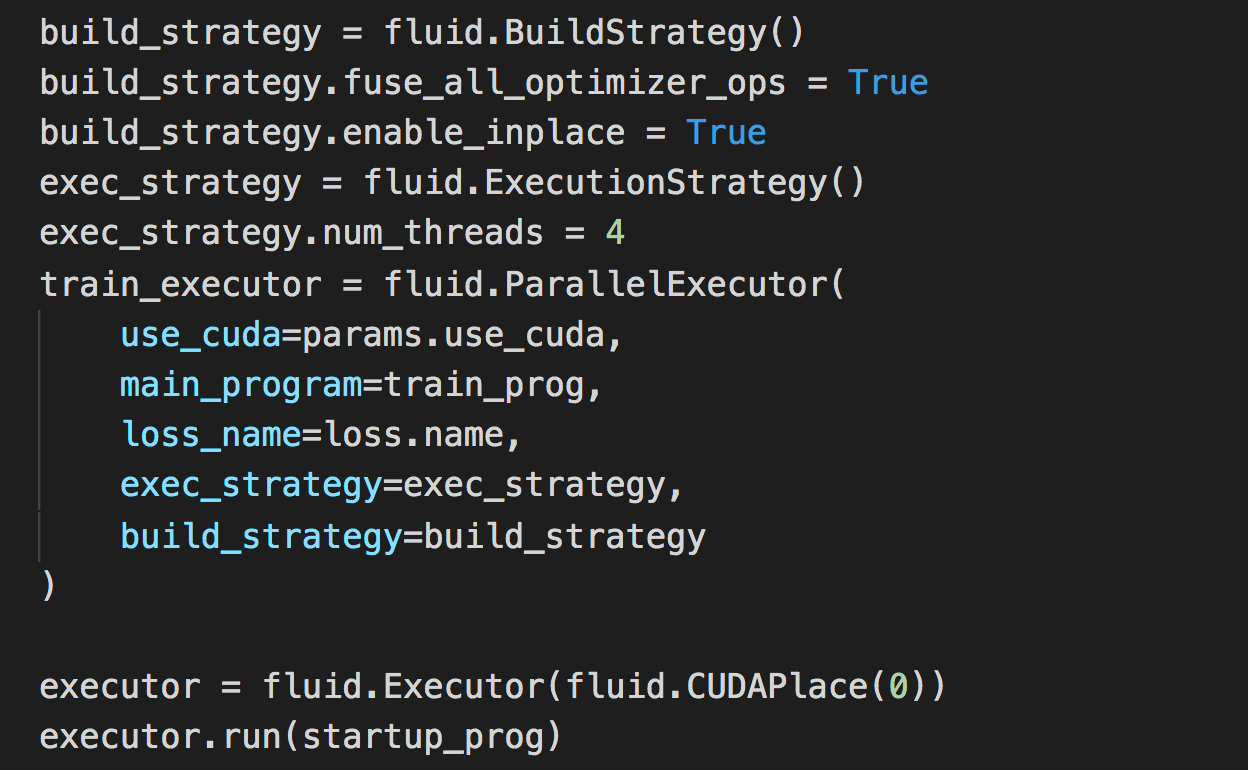
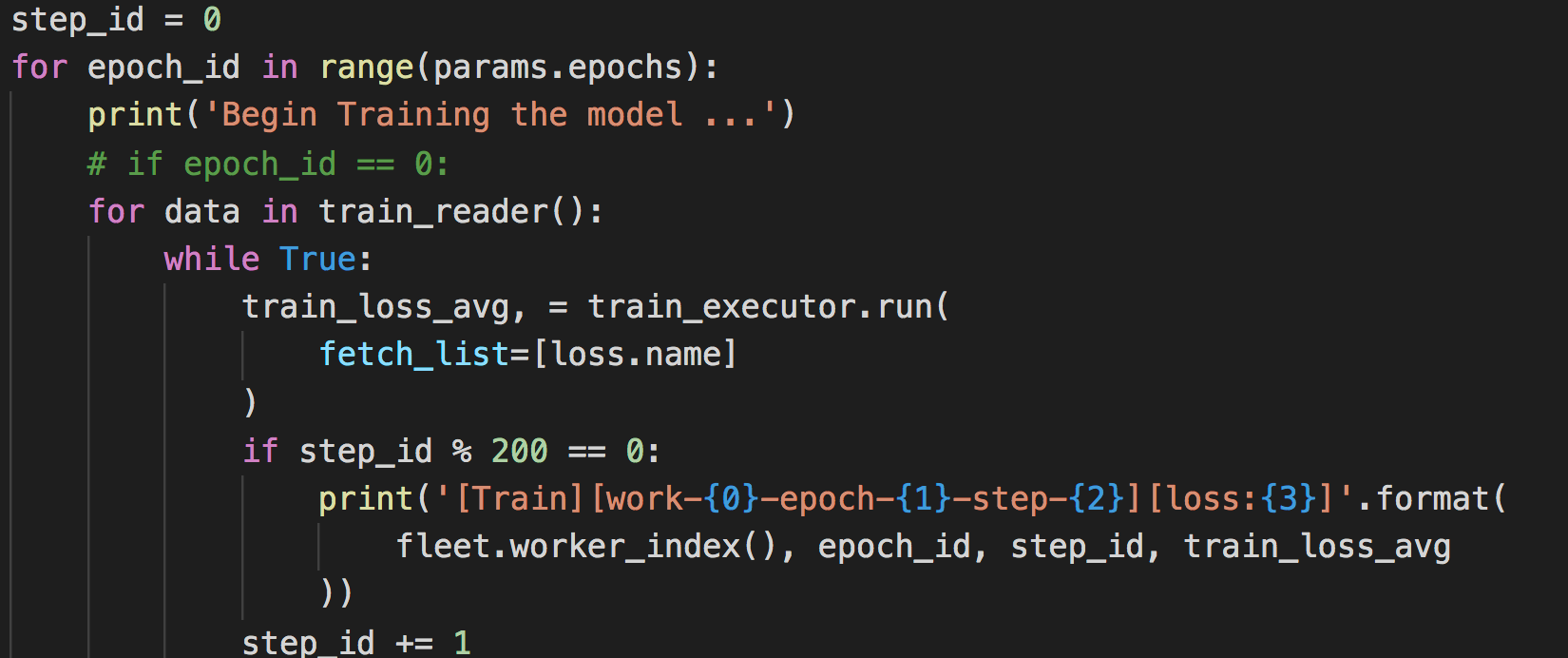
问题描述: /opt/_internal/cpython-3.7.0/lib/python3.7/site-packages/paddle/fluid/executor.py:1070: UserWarning: The following exception is not an EOF exception. "The following exception is not an EOF exception.") I0824 20:38:44.973078 17551 mmap_allocator.cc:124] PID: 17551, MemoryMapFdSet: set size - 0 Traceback (most recent call last): File "trainer_gpu.py", line 94, in main(params) File "trainer_gpu.py", line 77, in main fetch_list=[loss.name] File "/opt/_internal/cpython-3.7.0/lib/python3.7/site-packages/paddle/fluid/parallel_executor.py", line 303, in run return_numpy=return_numpy) File "/opt/_internal/cpython-3.7.0/lib/python3.7/site-packages/paddle/fluid/executor.py", line 1071, in run six.reraise(*sys.exc_info()) File "/opt/_internal/cpython-3.7.0/lib/python3.7/site-packages/six.py", line 703, in reraise raise value File "/opt/_internal/cpython-3.7.0/lib/python3.7/site-packages/paddle/fluid/executor.py", line 1066, in run return_merged=return_merged) File "/opt/_internal/cpython-3.7.0/lib/python3.7/site-packages/paddle/fluid/executor.py", line 1167, in _run_impl return_merged=return_merged) File "/opt/_internal/cpython-3.7.0/lib/python3.7/site-packages/paddle/fluid/executor.py", line 879, in _run_parallel tensors = exe.run(fetch_var_names, return_merged)._move_to_list() paddle.fluid.core_avx.EnforceNotMet:
C++ Call Stacks (More useful to developers):
0 std::string paddle::platform::GetTraceBackString<std::string const&>(std::string const&, char const*, int) 1 paddle::platform::EnforceNotMet::EnforceNotMet(std::string const&, char const*, int) 2 paddle::framework::OperatorWithKernel::ParseInputDataType(paddle::framework::ExecutionContext const&, std::string const&, paddle::framework::proto::VarType_Type*) const 3 paddle::framework::OperatorWithKernel::IndicateVarDataType(paddle::framework::ExecutionContext const&, std::string const&) const 4 paddle::operators::SequenceMaskOp::GetExpectedKernelType(paddle::framework::ExecutionContext const&) const 5 paddle::framework::OperatorWithKernel::ChooseKernel(paddle::framework::RuntimeContext const&, paddle::framework::Scope const&, paddle::platform::Place const&) const 6 paddle::framework::OperatorWithKernel::RunImpl(paddle::framework::Scope const&, paddle::platform::Place const&, paddle::framework::RuntimeContext*) const 7 paddle::framework::OperatorWithKernel::RunImpl(paddle::framework::Scope const&, paddle::platform::Place const&) const 8 paddle::framework::OperatorBase::Run(paddle::framework::Scope const&, paddle::platform::Place const&) 9 paddle::framework::details::ComputationOpHandle::RunImpl() 10 paddle::framework::details::FastThreadedSSAGraphExecutor::RunOpSync(paddle::framework::details::OpHandleBase*) 11 paddle::framework::details::FastThreadedSSAGraphExecutor::RunOp(paddle::framework::details::OpHandleBase*, std::shared_ptr<paddle::framework::BlockingQueue > const&, unsigned long*) 12 std::_Function_handler<std::unique_ptr<std::__future_base::_Result_base, std::__future_base::_Result_base::_Deleter> (), std::__future_base::_Task_setter<std::unique_ptr<std::__future_base::_Result, std::__future_base::_Result_base::_Deleter>, void> >::_M_invoke(std::_Any_data const&) 13 std::__future_base::_State_base::_M_do_set(std::function<std::unique_ptr<std::__future_base::_Result_base, std::__future_base::_Result_base::_Deleter> ()>&, bool&) 14 ThreadPool::ThreadPool(unsigned long)::{lambda()#1 (closed)}::operator()() const
Python Call Stacks (More useful to users):
File "/opt/_internal/cpython-3.7.0/lib/python3.7/site-packages/paddle/fluid/framework.py", line 2610, in append_op attrs=kwargs.get("attrs", None)) File "/opt/_internal/cpython-3.7.0/lib/python3.7/site-packages/paddle/fluid/layer_helper.py", line 43, in append_op return self.main_program.current_block().append_op(*args, **kwargs) File "/opt/_internal/cpython-3.7.0/lib/python3.7/site-packages/paddle/fluid/layers/sequence_lod.py", line 1342, in sequence_mask type='sequence_mask', inputs=inputs, outputs={'Y': out}, attrs=attrs) File "/root/paddlejob/workspace/env_run/model/bic_user2vec_v2.py", line 152, in bic_user2vec mask_sequence = fluid.layers.sequence_mask(x=feature_seq_length, maxlen=maxlen, dtype='float32') File "trainer_gpu.py", line 42, in main loss, predicts, labels = bic_user2vec.bic_user2vec(inputs, params) File "trainer_gpu.py", line 94, in main(params)
Error Message Summary:
InvalidArgumentError: The Tensor in the sequence_mask Op's Input Variable X(wordid_seq_length) is not initialized. [Hint: Expected t->IsInitialized() == true, but received t->IsInitialized():0 != true:1.] at (/paddle/paddle/fluid/framework/operator.cc:1289) [operator < sequence_mask > error]