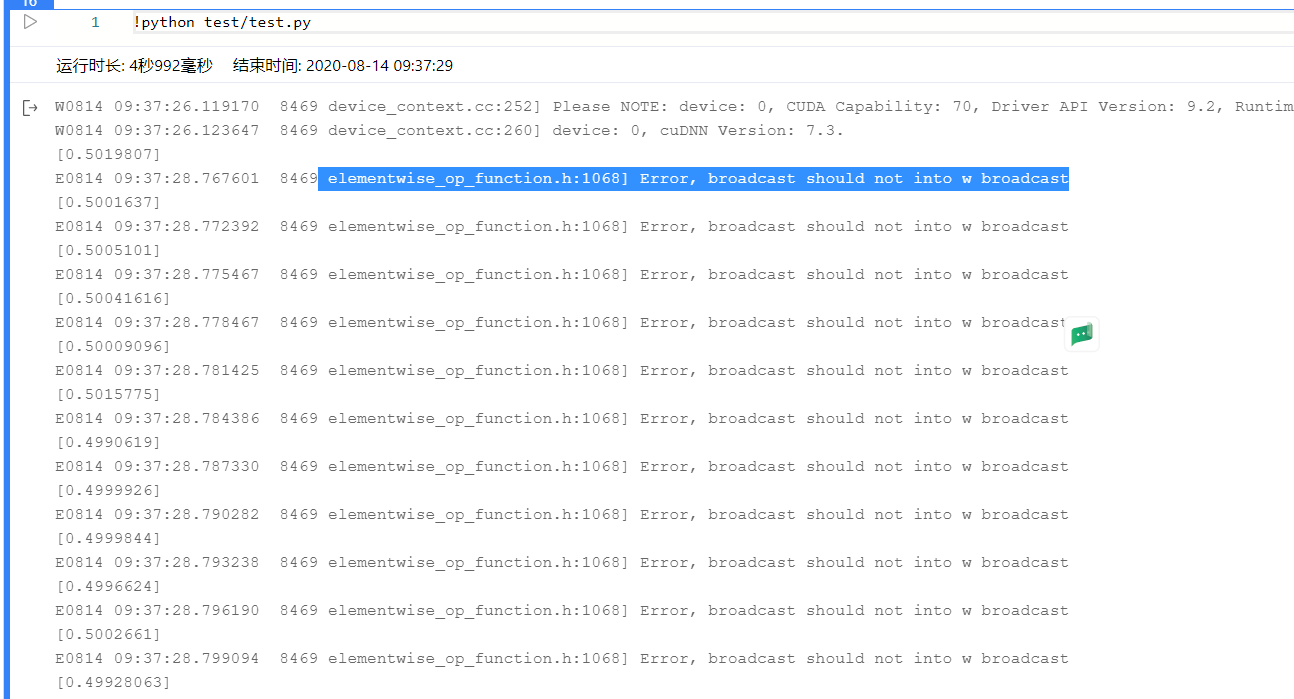
【论文复现】在命令行模式下,以下代码会报报错 broadcast should not into w broadcast,导致后向传播出现问题?求解答
Created by: liuxianyi
在命令行模式下,以下代码会报报错,导致后向传播出现问题?求解答
错误日志:
代码
import numpy as np
import paddle,itertools
import paddle.fluid as fluid
from paddle.fluid.dygraph import to_variable
import paddle.fluid.dygraph as nn
class adaILN(nn.Layer):
def __init__(self, num_features, eps=1e-5):
super(adaILN, self).__init__()
self.num_features = num_features
self.eps = eps
self.rho = fluid.layers.create_parameter(shape=[1,num_features,1,1], dtype='float32',is_bias=True,
default_initializer=fluid.initializer.Constant(0.9))
def forward(self, input):
ln_mean= fluid.layers.reduce_mean(input, dim=[1, 2, 3], keep_dim=True)
out_ln = input - ln_mean
out1 = (1-fluid.layers.expand(x=self.rho, expand_times=[input.shape[0], 1, 1, 1])) * out_ln
# 经过初步调试,确定发生错误位置在此处,将此处注释不会报错
return out1
#高层API的组网方式需要继承Model,Model类实现了模型执行所需的逻辑
class SimpleNet(paddle.fluid.dygraph.Layer):
def __init__(self):
super(SimpleNet, self).__init__()
self.conv = paddle.fluid.dygraph.Conv2D(1,1,filter_size=3,stride=1,padding=1)
self.iln = adaILN(1)
def forward(self, x):
x = self.conv(x)
x = self.iln(x)
return x
with paddle.fluid.dygraph.guard(paddle.fluid.CUDAPlace(0)):
model1 = SimpleNet()
Loss = nn.L1Loss()
optim = fluid.optimizer.Adam(learning_rate=0.001,
beta1=0.5,
beta2=0.999,
parameter_list=model1.parameters()
)
model1.train()
for i in range(20):
x1 = np.random.random((2, 1, 256, 256)).astype('float32')
x1 = to_variable(x1)
e1= model1(x1)
#print(e1)
# e2 = model1(e1)
loss2 = Loss(e1, x1)
#print('loss:',loss.numpy())
# loss = loss1+loss2
print(loss2.numpy())
loss2.backward()
optim.minimize(loss2)
optim.clear_gradients()Originally posted by @liuxianyi in https://github.com/PaddlePaddle/Paddle/issues/26192#issuecomment-673821904