把batch分开
Created by: 3wGTA
import numpy as np
import paddle.fluid as fluid
weight = np.random.randint(0,2,(32,5))
# weight = np.ones((32,5))
print(weight[:2])
def yield_data():
for i in range(100):
s_x = np.random.randint(2,5)
s_y = np.random.randint(2,8)
label = np.random.randint(2)
x = np.random.randint(0,10,(1,s_x)).tolist()
y = np.random.randint(0,10,(1,s_y)).tolist()
yield x[0],y[0] ,[label]
train_reader = fluid.io.batch(reader=yield_data,batch_size=2)
# for i,data in enumerate(train_reader()):
# print(data)
# break
V = 32
h = 3
emb_size=5
label = fluid.data(name='label', shape=[None,1], dtype='int64')
x = fluid.data(name='t', shape=[None], dtype='int64', lod_level=1)
y = fluid.data(name='h', shape=[None], dtype='int64', lod_level=1)
w = fluid.ParamAttr(name='emb_vec', initializer=fluid.initializer.NumpyArrayInitializer(weight), trainable=False)
emb_x = fluid.embedding(input=x, size=[32,5], param_attr=w)
emb_y = fluid.embedding(input=y, size=[32,5], param_attr=w)
fc_x = fluid.layers.fc(input=emb_x, size=4*3)
fc_y = fluid.layers.fc(input=emb_y, size=4*3)
fc_x_shape = fluid.layers.shape(fc_x)
lstm_x,cell_x = fluid.layers.dynamic_lstm(input=fc_x, size=4*3)
lstm_y,cell_y = fluid.layers.dynamic_lstm(input=fc_y, size=4*3)
ww = fluid.layers.create_parameter(
shape=[5,3],
dtype='float32',
name='w',
default_initializer=fluid.initializer.NumpyArrayInitializer(np.random.rand(5,3).astype('float32')))
fetch_var = [x, y , emb_x, emb_y, fc_x, fc_y, lstm_x, lstm_y]
place = fluid.CPUPlace()
exe = fluid.Executor(place)
main_program = fluid.default_main_program()
feeder = fluid.DataFeeder(feed_list=['t', 'h','label'], place=place)
exe.run(fluid.default_startup_program())
for i, data in enumerate(train_reader()):
print(data)
res = exe.run(
main_program,
feeder.feed(data),
fetch_list=fetch_var,
return_numpy=False
)
break输入数据 x,y,label
一个batch 中有两个 (x1,y1,label1),(x2,y2,label2) 两个数据
其中x1长为M1,y1长为M2,label1为1
x2长为N2,y2长为N2, label 长为1
经过lstm网络之后,lstm_x,和lstm_y变成的矩阵形状是
lstm-x (M1+M2, h) 带有lod信息 [0, M1, M1+M2]
lstm-y (N1+N2, h) 带有lod信息 [0, N1, N1+N2]
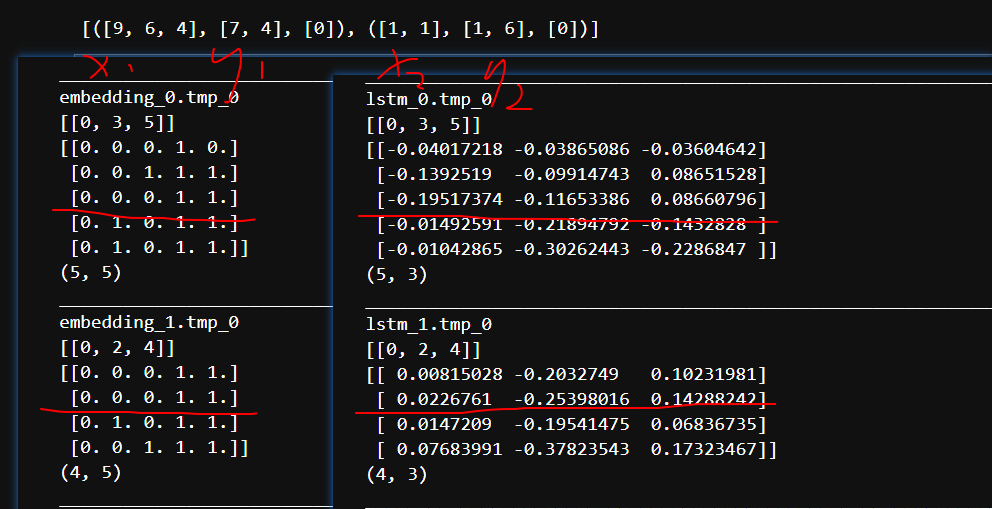
按照上面红线分开两个矩阵,把分别小矩阵进行计算 lstm_x 分成 (N1,h),(N2,h) lstm_y 分成(M1,h),(M2,h) 然后分开的对应序号进行其他操作 是的每条数据(x_i,y_i)的词嵌入相互运算