paddle/book中 机器翻译demo报错 & 修改后的seq2seq 模型input type error
Created by: Akeepers
环境:
- PaddlePaddle 1.6.3
- Python 2.7
Q1: 直接运行book中的demo报错
- error提示在line 289,loss_val是一个numpy array,而不是float;在之前加入loss_val=np.mean(loss_val); 可以正常运行
Q2:基于上述代码修改的ernie-based seq2seq (其中的encoder被改为了ernie ,decoder的代码保持不动,仅修改:layers.rnn中的initial_states为None) 报错,Decoder部分 input type error
Traceback (most recent call last):
File "run_seq2seq.py", line 136, in <module>
main(args)
File "run_seq2seq.py", line 128, in main
train(args)
File "run_seq2seq.py", line 61, in train
logits = model_func(args, inputs, ernie_config, is_train=True)
File "/home/yangpan/projects/paper_recurrence/PLMEE/ERNIE/ernie/finetune/seq2seq.py", line 212, in model_func
is_train=is_train)
File "/home/yangpan/projects/paper_recurrence/PLMEE/ERNIE/ernie/finetune/seq2seq.py", line 158, in decoder
encoder_padding_mask=encoder_padding_mask)
File "/home/yangpan/anaconda3/envs/paddle-py2.7/lib/python2.7/site-packages/paddle/fluid/layers/rnn.py", line 451, in rnn
outputs, new_states = cell.call(inputs, copy_states, **kwargs)
File "/home/yangpan/projects/paper_recurrence/PLMEE/ERNIE/ernie/finetune/seq2seq.py", line 88, in call
output, new_hidden = self.gru_cell(step_input, hidden)
File "/home/yangpan/anaconda3/envs/paddle-py2.7/lib/python2.7/site-packages/paddle/fluid/layers/rnn.py", line 66, in __call__
return self.call(inputs, states, **kwargs)
File "/home/yangpan/anaconda3/envs/paddle-py2.7/lib/python2.7/site-packages/paddle/fluid/layers/rnn.py", line 242, in call
new_hidden = self.gru_unit(inputs, states)
File "/home/yangpan/anaconda3/envs/paddle-py2.7/lib/python2.7/site-packages/paddle/fluid/dygraph/layers.py", line 178, in __call__
outputs = self.forward(*inputs, **kwargs)
File "/home/yangpan/anaconda3/envs/paddle-py2.7/lib/python2.7/site-packages/paddle/fluid/contrib/layers/rnn_impl.py", line 118, in forward
concat_input_hidden = layers.concat([input, pre_hidden], 1)
File "/home/yangpan/anaconda3/envs/paddle-py2.7/lib/python2.7/site-packages/paddle/fluid/layers/tensor.py", line 272, in concat
% (type(x)))
TypeError: The type of x in 'input' in concat must be Variable, but received <type 'list'>.尝试将对应代码output, new_hidden = self.gru_cell(step_input, hidden) 中的step_input, hidden都输出处理,type是LodTensor:
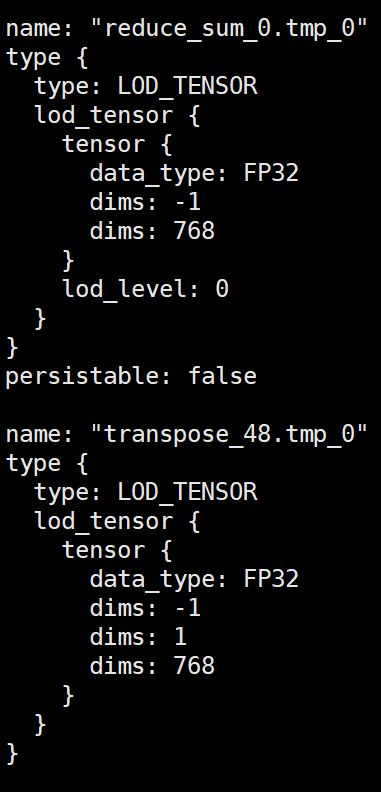
代码:
# Copyright (c) 2018 PaddlePaddle Authors. All Rights Reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
from __future__ import print_function
import os
import six
import sys
import numpy as np
import paddle
import paddle.fluid as fluid
import paddle.fluid.layers as layers
import logging
from model.ernie import ErnieModel
dict_size = 30522
source_dict_size = target_dict_size = dict_size
bos_id = 0
eos_id = 1
word_dim = 256
hidden_dim = 768
decoder_size = hidden_dim
max_length = 256
beam_size = 4
batch_size = 64
model_save_dir = "machine_translation.inference.model"
log = logging.getLogger()
class DecoderCell(layers.RNNCell):
"""Additive Attention followed by GRU"""
def __init__(self, hidden_size):
self.hidden_size = hidden_size
self.gru_cell = layers.GRUCell(hidden_size)
@property
def state_shape(self):
"""
The `state_shape` of LSTMCell is a list with two shapes: `[[hidden_size], [hidden_size]]`
(-1 for batch size would be automatically inserted into shape). These two
shapes correspond to :math:`h_{t-1}` and :math:`c_{t-1}` separately.
"""
return [[self.hidden_size], [self.hidden_size]]
def attention(self, hidden, encoder_output, encoder_output_proj,
encoder_padding_mask):
decoder_state_proj = layers.unsqueeze(
layers.fc(hidden, size=self.hidden_size, bias_attr=False), [1])
mixed_state = fluid.layers.elementwise_add(
encoder_output_proj,
layers.expand(decoder_state_proj,
[1, layers.shape(decoder_state_proj)[1], 1]))
# attn_scores: [batch_size, src_seq_len]
attn_scores = layers.squeeze(
layers.fc(
input=mixed_state, size=1, num_flatten_dims=2, bias_attr=False),
[2])
if encoder_padding_mask is not None:
attn_scores = layers.elementwise_add(attn_scores,
encoder_padding_mask)
attn_scores = layers.softmax(attn_scores)
context = layers.reduce_sum(
layers.elementwise_mul(encoder_output, attn_scores, axis=0), dim=1)
return context
def call(self,
step_input,
hidden,
encoder_output,
encoder_output_proj,
encoder_padding_mask=None):
context = self.attention(hidden, encoder_output, encoder_output_proj,
encoder_padding_mask)
step_input = layers.concat([step_input, context], axis=1)
output, new_hidden = self.gru_cell(step_input, hidden)
return output, new_hidden
def data_func(args, is_train=True):
"""data inputs and data loader"""
src_ids = fluid.layers.data(name='1', shape=[-1, args.max_seq_len, 1], dtype='int64')
sent_ids = fluid.layers.data(name='2', shape=[-1, args.max_seq_len, 1], dtype='int64')
pos_ids = fluid.layers.data(name='3', shape=[-1, args.max_seq_len, 1], dtype='int64')
task_ids = fluid.layers.data(name='4', shape=[-1, args.max_seq_len, 1], dtype='int64')
input_mask = fluid.layers.data(name='5', shape=[-1, args.max_seq_len, 1], dtype='float32')
seq_lens = fluid.layers.data(name='6', shape=[-1], dtype='int64')
inputs = [src_ids, sent_ids, pos_ids, task_ids, input_mask, seq_lens]
if is_train:
labels = fluid.layers.data(name='7', shape=[-1, args.max_seq_len, 1], dtype='int64')
inputs += [labels]
loader = fluid.io.DataLoader.from_generator(
feed_list=inputs, capacity=70, iterable=False)
return inputs, loader
def encoder(args, inputs, ernie_config):
src_ids = inputs[0]
sent_ids = inputs[1]
pos_ids = inputs[2]
task_ids = inputs[3]
input_mask = inputs[4]
# ernie encoder
ernie = ErnieModel(
src_ids=src_ids,
position_ids=pos_ids,
sentence_ids=sent_ids,
task_ids=task_ids,
input_mask=input_mask,
config=ernie_config,
use_fp16=args.use_fp16)
enc_out = ernie.get_sequence_output() # [batch_size, max_seq_len, hidden_size]
enc_out = fluid.layers.dropout(
x=enc_out, dropout_prob=0.1, dropout_implementation="upscale_in_train")
return enc_out
def decoder(encoder_output,
encoder_output_proj,
encoder_padding_mask,
trg=None,
is_train=True):
"""Decoder: GRU with Attention"""
decoder_cell = DecoderCell(hidden_size=decoder_size)
trg_embeder = lambda x: fluid.embedding(input=x,
size=[target_dict_size, hidden_dim],
dtype="float32",
param_attr=fluid.ParamAttr(
name="trg_emb_table"))
output_layer = lambda x: layers.fc(x,
size=target_dict_size,
num_flatten_dims=len(x.shape) - 1,
param_attr=fluid.ParamAttr(name=
"output_w"))
if is_train:
decoder_output, _ = layers.rnn(
cell=decoder_cell,
inputs=trg_embeder(trg),
initial_states=None,
time_major=False,
encoder_output=encoder_output,
encoder_output_proj=encoder_output_proj,
encoder_padding_mask=encoder_padding_mask)
decoder_output = output_layer(decoder_output)
else:
encoder_output = layers.BeamSearchDecoder.tile_beam_merge_with_batch(
encoder_output, beam_size)
encoder_output_proj = layers.BeamSearchDecoder.tile_beam_merge_with_batch(
encoder_output_proj, beam_size)
encoder_padding_mask = layers.BeamSearchDecoder.tile_beam_merge_with_batch(
encoder_padding_mask, beam_size)
beam_search_decoder = layers.BeamSearchDecoder(
cell=decoder_cell,
start_token=bos_id,
end_token=eos_id,
beam_size=beam_size,
embedding_fn=trg_embeder,
output_fn=output_layer)
decoder_output, _ = layers.dynamic_decode(
decoder=beam_search_decoder,
inits=None,
max_step_num=max_length,
output_time_major=False,
encoder_output=encoder_output,
encoder_output_proj=encoder_output_proj,
encoder_padding_mask=encoder_padding_mask)
return decoder_output
def model_func(args, inputs, ernie_config, is_train=True):
# ernie encoder
src = inputs[0]
encoder_output = encoder(args, inputs, ernie_config)
print(encoder_output)
encoder_output_proj = layers.fc(
input=encoder_output,
size=decoder_size,
num_flatten_dims=2,
bias_attr=False)
src_sequence_length = inputs[5]
src_mask = layers.sequence_mask(
src_sequence_length, maxlen=layers.shape(src)[1], dtype="float32")
encoder_padding_mask = (src_mask - 1.0) * 1e9
trg = inputs[6] if is_train else None
# decoder
output = decoder(
encoder_output=encoder_output,
encoder_output_proj=encoder_output_proj,
encoder_padding_mask=encoder_padding_mask,
trg=trg,
is_train=is_train)
return output
def loss_func(logits, label, trg_sequence_length):
probs = layers.softmax(logits)
loss = layers.cross_entropy(input=probs, label=label)
trg_mask = layers.sequence_mask(
trg_sequence_length, maxlen=layers.shape(logits)[1], dtype="float32")
avg_cost = layers.reduce_sum(loss * trg_mask) / layers.reduce_sum(trg_mask)
return avg_cost
def optimizer_func():
fluid.clip.set_gradient_clip(clip=fluid.clip.GradientClipByGlobalNorm(
clip_norm=5.0))
lr_decay = fluid.layers.learning_rate_scheduler.noam_decay(hidden_dim, 1000)
return fluid.optimizer.Adam(
learning_rate=lr_decay,
regularization=fluid.regularizer.L2DecayRegularizer(
regularization_coeff=1e-4))
if __name__ == '__main__':
pass
# prepare_logger(log)
# check_cuda(args.use_cuda)
# print_arguments(args)
# main(args.use_cuda)