Paddle-TRT实际测试数据与官网数据差距较大
Created by: hexiaoting
环境
操作系统centos Intel(R) Xeon(R) CPU E5-2640 v4 @ 2.40GHz NVIDIA Corporation GK210GL [Tesla K80] (rev a1) 测试模型 ResNet50,MobileNet,ResNet101
Paddle环境
- fluid_inference 直接下载的安装包 GIT COMMIT ID: fa7ace7c WITH_MKL: ON WITH_MKLDNN: OFF WITH_GPU: ON CUDA version: 10.0 CUDNN version: v7
- 下载了PaddlePaddle model github repo
测试说明
- 按照Paddle-TRT性能测试 进行本次测试工作。
- 所有的inputsize都是3 * 224 * 224
- 模型出处:
python infer.py \
--model=ResNet50和ResNet101 \
--pretrained_model=${path_to_pretrain_model} \
--save_inference=True测试结果
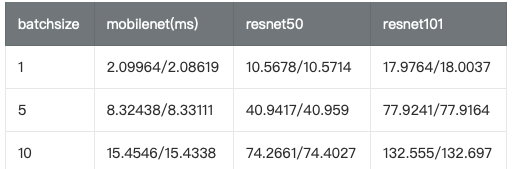
结果和官网的测试结果差异较大:
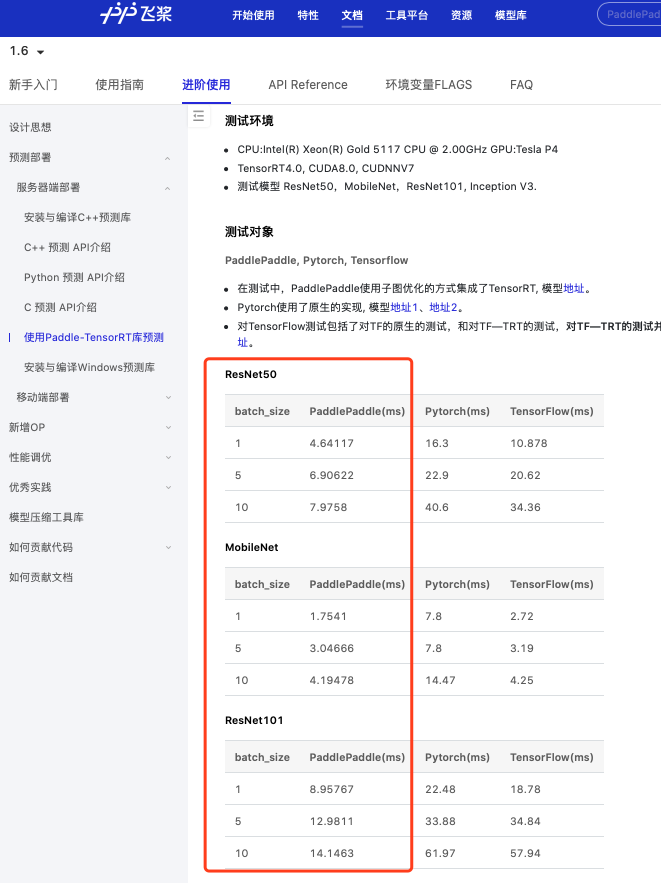
Q1: inputsize是多少如何定的呀? Q2:我处理resnet50和resnet101和官方的paddle-TRT测试对比中的resnet50和resnet101是一样的吗? Q3:为什么batchsize越大,测试结果和paddle官网的差距越大? Q4: 已发布模型里面没有inceptionv3呢,那官方的paddle-TRT测试对比的inceptionv3是哪来的? Q5: Paddle-TRT库是依赖于C++库的是吗?C++库和TRT库是什么关系?TRT库和fluid两种推断方法我可以理解为TRT是在fluid推断的基础上利用nvidia tensorrt做了加速吗?