Int8模型 用tensorrt推断提示硬件不支持native int8
Created by: hexiaoting
1. 系统环境:
centos7 GPU: 04:00.0 3D controller: NVIDIA Corporation GK210GL [Tesla K80] (rev a1) 05:00.0 3D controller: NVIDIA Corporation GK210GL [Tesla K80] (rev a1) 08:00.0 3D controller: NVIDIA Corporation GK210GL [Tesla K80] (rev a1) 09:00.0 3D controller: NVIDIA Corporation GK210GL [Tesla K80] (rev a1)
2. 执行步骤
按照https://www.paddlepaddle.org.cn/documentation/docs/zh/advanced_usage/deploy/inference/paddle_tensorrt_infer.html来执行环境:
S1. 下载的推断库:
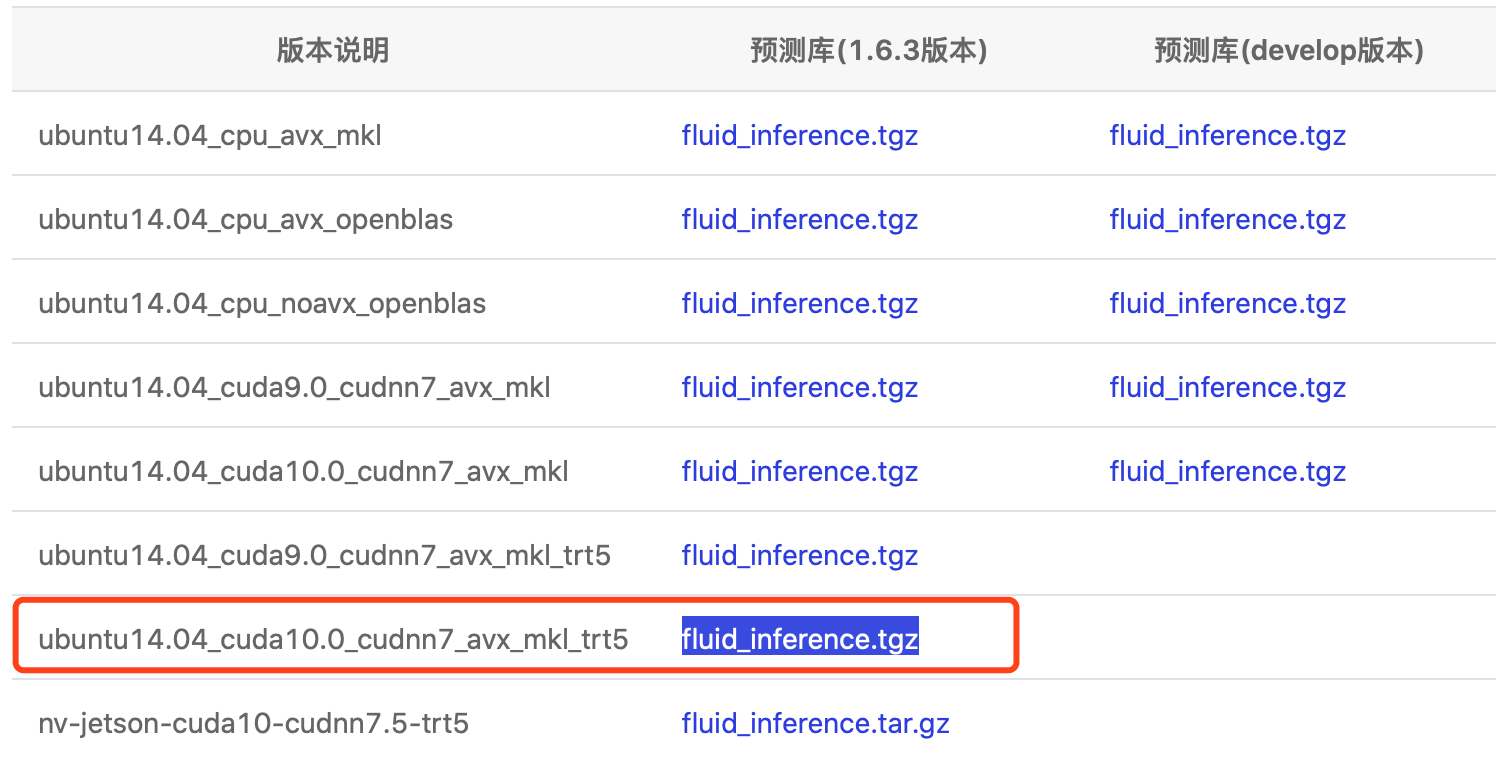
GIT COMMIT ID: fa7ace7cf2859f927c26f1970bbc2f5551532df1
WITH_MKL: ON
WITH_MKLDNN: OFF
WITH_GPU: ON
CUDA version: 10.0
CUDNN version: v7S2. 使用Paddle-TRT int8的说明来执行
S3.修改run.sh并执行出现以下信息:
W0210 18:22:45.509356 1829 helper.h:61] Int8 support requested on hardware without native Int8 support, performance will be negatively affected不明白是指什么硬件不支持int8,那不支持的话性能就和float32一样了是吗?
3. 最后附上执行sh run.sh完整的log:
[zhibin@gpu80 paddle-TRT]$ sh run.sh
-- The CXX compiler identification is GNU 4.8.5
-- The C compiler identification is GNU 4.8.5
-- Check for working CXX compiler: /usr/bin/c++
-- Check for working CXX compiler: /usr/bin/c++ -- works
-- Detecting CXX compiler ABI info
-- Detecting CXX compiler ABI info - done
-- Detecting CXX compile features
-- Detecting CXX compile features - done
-- Check for working C compiler: /usr/bin/cc
-- Check for working C compiler: /usr/bin/cc -- works
-- Detecting C compiler ABI info
-- Detecting C compiler ABI info - done
-- Detecting C compile features
-- Detecting C compile features - done
flags -std=c++11 -g
CMake Warning (dev) in CMakeLists.txt:
No cmake_minimum_required command is present. A line of code such as
cmake_minimum_required(VERSION 3.12)
should be added at the top of the file. The version specified may be lower
if you wish to support older CMake versions for this project. For more
information run "cmake --help-policy CMP0000".
This warning is for project developers. Use -Wno-dev to suppress it.
-- Configuring done
CMake Warning (dev) at CMakeLists.txt:52 (add_executable):
Policy CMP0003 should be set before this line. Add code such as
if(COMMAND cmake_policy)
cmake_policy(SET CMP0003 NEW)
endif(COMMAND cmake_policy)
as early as possible but after the most recent call to
cmake_minimum_required or cmake_policy(VERSION). This warning appears
because target "fluid_int8_test" links to some libraries for which the
linker must search:
glog, gflags, protobuf, z, xxhash, -lrt -ldl -lpthread
and other libraries with known full path:
/home/zhibin/hwt/workspace/fluid_inference/third_party/install/mklml/lib/libiomp5.so
/home/zhibin/qzhong/thirdparty/cuda-10.0/lib64/libcudart.so
CMake is adding directories in the second list to the linker search path in
case they are needed to find libraries from the first list (for backwards
compatibility with CMake 2.4). Set policy CMP0003 to OLD or NEW to enable
or disable this behavior explicitly. Run "cmake --help-policy CMP0003" for
more information.
This warning is for project developers. Use -Wno-dev to suppress it.
-- Generating done
-- Build files have been written to: /home/zhibin/hwt/workspace/sample/paddle-TRT/build
Scanning dependencies of target fluid_int8_test
[ 50%] Building CXX object CMakeFiles/fluid_int8_test.dir/fluid_int8_test.o
[100%] Linking CXX executable fluid_int8_test
[100%] Built target fluid_int8_test
WARNING: Logging before InitGoogleLogging() is written to STDERR
I0210 18:22:45.197010 1829 analysis_predictor.cc:88] Profiler is deactivated, and no profiling report will be generated.
I0210 18:22:45.203107 1829 op_compatible_info.cc:201] The default operator required version is missing. Please update the model version.
I0210 18:22:45.203142 1829 analysis_predictor.cc:841] MODEL VERSION: 0.0.0
I0210 18:22:45.203161 1829 analysis_predictor.cc:843] PREDICTOR VERSION: 1.6.3
I0210 18:22:45.203359 1829 analysis_predictor.cc:409] TensorRT subgraph engine is enabled
--- Running analysis [ir_graph_build_pass]
--- Running analysis [ir_graph_clean_pass]
--- Running analysis [ir_analysis_pass]
--- Running IR pass [conv_affine_channel_fuse_pass]
--- Running IR pass [conv_eltwiseadd_affine_channel_fuse_pass]
--- Running IR pass [shuffle_channel_detect_pass]
--- Running IR pass [quant_conv2d_dequant_fuse_pass]
--- Running IR pass [delete_quant_dequant_op_pass]
--- Running IR pass [tensorrt_subgraph_pass]
I0210 18:22:45.268889 1829 tensorrt_subgraph_pass.cc:111] --- detect a sub-graph with 85 nodes
I0210 18:22:45.274417 1829 tensorrt_subgraph_pass.cc:248] RUN Paddle TRT int8 calibration mode...
I0210 18:22:45.274458 1829 tensorrt_subgraph_pass.cc:285] Prepare TRT engine (Optimize model structure, Select OP kernel etc). This process may cost a lot of time.
W0210 18:22:45.509356 1829 helper.h:61] Int8 support requested on hardware without native Int8 support, performance will be negatively affected.
--- Running IR pass [conv_bn_fuse_pass]
--- Running IR pass [conv_elementwise_add_act_fuse_pass]
--- Running IR pass [conv_elementwise_add2_act_fuse_pass]
--- Running IR pass [conv_elementwise_add_fuse_pass]
--- Running IR pass [transpose_flatten_concat_fuse_pass]
--- Running analysis [ir_params_sync_among_devices_pass]
I0210 18:22:56.596802 1829 ir_params_sync_among_devices_pass.cc:41] Sync params from CPU to GPU
--- Running analysis [adjust_cudnn_workspace_size_pass]
--- Running analysis [inference_op_replace_pass]
--- Running analysis [ir_graph_to_program_pass]
I0210 18:22:56.614691 1829 analysis_predictor.cc:470] ======= optimize end =======
I0210 18:22:56.614792 1829 naive_executor.cc:105] --- skip [feed], feed -> image
I0210 18:22:56.614984 1829 naive_executor.cc:105] --- skip [save_infer_model/scale_0], fetch -> fetch
W0210 18:22:56.623540 1829 device_context.cc:236] Please NOTE: device: 0, CUDA Capability: 37, Driver API Version: 10.0, Runtime API Version: 10.0
W0210 18:22:56.623649 1829 device_context.cc:244] device: 0, cuDNN Version: 7.6.
batch: 4 predict cost: 6.98011ms