paddle 1.6.3使用fluid.layers.batch_norm报错
Created by: yxfGrace
代码:
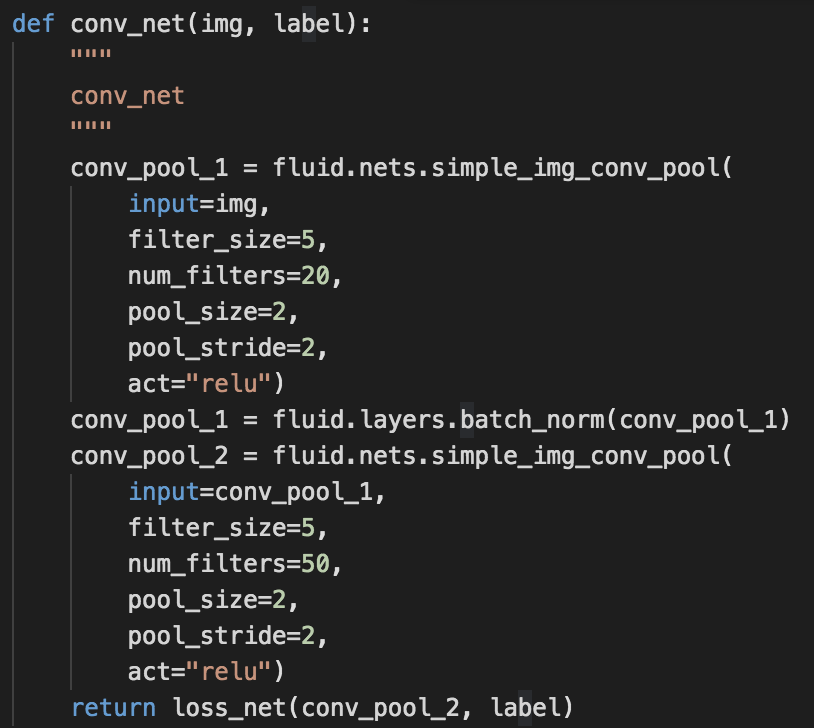 报错:
/home/slurm/job/tmp/job-121300/python27-gcc482/lib/python2.7/site-packages/paddle/fluid/executor.py:779: UserWarning: The following exception is not an EOF exception.
"The following exception is not an EOF exception.")
Traceback (most recent call last):
File "trainer.py", line 339, in
main(use_cuda, False, 'conv_net', is_local)
File "trainer.py", line 328, in main
is_local=is_local)
File "trainer.py", line 273, in train
train_loop()
File "trainer.py", line 204, in train_loop
train_acc, = exe.run(feed=feeder.feed(data), fetch_list=[acc])
File "/home/slurm/job/tmp/job-121300/python27-gcc482/lib/python2.7/site-packages/paddle/fluid/parallel_executor.py", line 311, in run
return_numpy=return_numpy)
File "/home/slurm/job/tmp/job-121300/python27-gcc482/lib/python2.7/site-packages/paddle/fluid/executor.py", line 780, in run
six.reraise(*sys.exc_info())
File "/home/slurm/job/tmp/job-121300/python27-gcc482/lib/python2.7/site-packages/paddle/fluid/executor.py", line 775, in run
use_program_cache=use_program_cache)
File "/home/slurm/job/tmp/job-121300/python27-gcc482/lib/python2.7/site-packages/paddle/fluid/executor.py", line 834, in _run_impl
return_numpy=return_numpy)
File "/home/slurm/job/tmp/job-121300/python27-gcc482/lib/python2.7/site-packages/paddle/fluid/executor.py", line 674, in _run_parallel
tensors = exe.run(fetch_var_names)._move_to_list()
paddle.fluid.core_avx.EnforceNotMet:
报错:
/home/slurm/job/tmp/job-121300/python27-gcc482/lib/python2.7/site-packages/paddle/fluid/executor.py:779: UserWarning: The following exception is not an EOF exception.
"The following exception is not an EOF exception.")
Traceback (most recent call last):
File "trainer.py", line 339, in
main(use_cuda, False, 'conv_net', is_local)
File "trainer.py", line 328, in main
is_local=is_local)
File "trainer.py", line 273, in train
train_loop()
File "trainer.py", line 204, in train_loop
train_acc, = exe.run(feed=feeder.feed(data), fetch_list=[acc])
File "/home/slurm/job/tmp/job-121300/python27-gcc482/lib/python2.7/site-packages/paddle/fluid/parallel_executor.py", line 311, in run
return_numpy=return_numpy)
File "/home/slurm/job/tmp/job-121300/python27-gcc482/lib/python2.7/site-packages/paddle/fluid/executor.py", line 780, in run
six.reraise(*sys.exc_info())
File "/home/slurm/job/tmp/job-121300/python27-gcc482/lib/python2.7/site-packages/paddle/fluid/executor.py", line 775, in run
use_program_cache=use_program_cache)
File "/home/slurm/job/tmp/job-121300/python27-gcc482/lib/python2.7/site-packages/paddle/fluid/executor.py", line 834, in _run_impl
return_numpy=return_numpy)
File "/home/slurm/job/tmp/job-121300/python27-gcc482/lib/python2.7/site-packages/paddle/fluid/executor.py", line 674, in _run_parallel
tensors = exe.run(fetch_var_names)._move_to_list()
paddle.fluid.core_avx.EnforceNotMet:
C++ Call Stacks (More useful to developers):
0 std::string paddle::platform::GetTraceBackStringstd::string(std::string&&, char const*, int) 1 paddle::platform::EnforceNotMet::EnforceNotMet(paddle::platform::ErrorSummary const&, char const*, int) 2 paddle::operators::BatchNormKernel<paddle::platform::CUDADeviceContext, float>::Compute(paddle::framework::ExecutionContext const&) const 3 std::_Function_handler<void (paddle::framework::ExecutionContext const&), paddle::framework::OpKernelRegistrarFunctor<paddle::platform::CUDAPlace, false, 0ul, paddle::operators::BatchNormKernel<paddle::platform::CUDADeviceContext, float>, paddle::operators::BatchNormKernel<paddle::platform::CUDADeviceContext, double>, paddle::operators::BatchNormKernel<paddle::platform::CUDADeviceContext, paddle::platform::float16> >::operator()(char const*, char const*, int) const::{lambda(paddle::framework::ExecutionContext const&)#1 (closed)}>::_M_invoke(std::_Any_data const&, paddle::framework::ExecutionContext const&) 4 paddle::framework::OperatorWithKernel::RunImpl(paddle::framework::Scope const&, paddle::platform::Place const&, paddle::framework::RuntimeContext*) const 5 paddle::framework::OperatorWithKernel::RunImpl(paddle::framework::Scope const&, paddle::platform::Place const&) const 6 paddle::framework::OperatorBase::Run(paddle::framework::Scope const&, paddle::platform::Place const&) 7 paddle::framework::details::OpHandleBase::RunAndRecordEvent(std::function<void ()> const&) 8 paddle::framework::details::ComputationOpHandle::RunImpl() 9 paddle::framework::details::FastThreadedSSAGraphExecutor::RunOpSync(paddle::framework::details::OpHandleBase*) 10 paddle::framework::details::FastThreadedSSAGraphExecutor::RunOp(paddle::framework::details::OpHandleBase*, std::shared_ptr<paddle::framework::BlockingQueue > const&, unsigned long*) 11 std::_Function_handler<std::unique_ptr<std::__future_base::_Result_base, std::__future_base::_Result_base::_Deleter> (), std::__future_base::_Task_setter<std::unique_ptr<std::__future_base::_Result, std::__future_base::_Result_base::_Deleter>, void> >::_M_invoke(std::_Any_data const&) 12 std::__future_base::_State_base::_M_do_set(std::function<std::unique_ptr<std::__future_base::_Result_base, std::__future_base::_Result_base::_Deleter> ()>&, bool&) 13 ThreadPool::ThreadPool(unsigned long)::{lambda()#1 (closed)}::operator()() const
Python Call Stacks (More useful to users):
File "/home/slurm/job/tmp/job-121300/python27-gcc482/lib/python2.7/site-packages/paddle/fluid/framework.py", line 2488, in append_op attrs=kwargs.get("attrs", None)) File "/home/slurm/job/tmp/job-121300/python27-gcc482/lib/python2.7/site-packages/paddle/fluid/layer_helper.py", line 43, in append_op return self.main_program.current_block().append_op(*args, **kwargs) File "/home/slurm/job/tmp/job-121300/python27-gcc482/lib/python2.7/site-packages/paddle/fluid/layers/nn.py", line 4363, in batch_norm attrs=attrs) File "trainer.py", line 150, in conv_net conv_pool_1 = fluid.layers.batch_norm(conv_pool_1) File "trainer.py", line 177, in train prediction, avg_loss, acc = net_conf(img, label) File "trainer.py", line 328, in main is_local=is_local) File "trainer.py", line 339, in main(use_cuda, False, 'conv_net', is_local)
Error Message Summary:
Error: CUDNN_STATUS_BAD_PARAM at (/paddle/paddle/fluid/operators/batch_norm_op.cu:183) [operator < batch_norm > error]
1.6.1可以跑通,1.6.3会报错,请问是batch_norm在1.6.3中有改动吗?