SGD Op更新fuse之后的parameter和单独更新parameter存在diff
Created by: chenwhql
实验代码如下 (Test code)
- 对比的执行器:Executor和(ParallelExecutor + fuse_all_optimizer_ops = True)
- (Compare test:Executor & (ParallelExecutor + fuse_all_optimizer_ops = True))
- 该实验的diff仅在CPU下出现,GPU环境是正常的
- (The diff of this experiment only appears under the CPU, the GPU environment is normal)
import paddle.fluid as fluid
import numpy as np
import random
batch_size = 32
feed_dict = {
'image': np.random.random([batch_size, 784]).astype('float32'),
'label': np.random.random_integers(
low=0, high=9, size=[batch_size, 1]).astype('int64')
}
def simple_fc_net():
img = fluid.layers.data(name='image', shape=[784], dtype='float32')
label = fluid.layers.data(name='label', shape=[1], dtype='int64')
prediction = fluid.layers.fc(img, size=10, act='softmax')
loss = fluid.layers.cross_entropy(input=prediction, label=label)
loss = fluid.layers.mean(loss)
return loss
def build_program_and_scope():
startup_program = fluid.Program()
main_program = fluid.Program()
startup_program.random_seed = 1
main_program.random_seed = 1
scope = fluid.Scope()
with fluid.program_guard(main_program, startup_program):
with fluid.unique_name.guard():
loss = simple_fc_net()
adam = fluid.optimizer.SGD(learning_rate=1e-3)
adam.minimize(loss)
with fluid.scope_guard(scope):
exe = fluid.Executor(fluid.CPUPlace())
exe.run(startup_program)
return main_program, scope, exe, loss
# Program
prog1, scope1, exe, loss1 = build_program_and_scope()
# CompiledProgram
prog2, scope2, _, loss = build_program_and_scope()
build_strategy = fluid.BuildStrategy()
# if close this strategy, no diff
build_strategy.fuse_all_optimizer_ops = True
exec_strategy = fluid.ExecutionStrategy()
exec_strategy.num_threads = 1
compiled_prog = fluid.CompiledProgram(prog2).with_data_parallel(
loss_name=loss.name,
build_strategy=build_strategy,
exec_strategy=exec_strategy,
places=fluid.CPUPlace())
for i in range(4):
with fluid.scope_guard(scope1):
fetch_val1, = exe.run(prog1,
feed=feed_dict,
fetch_list=['fc_0.b_0'])
with fluid.scope_guard(scope2):
fetch_val2, = exe.run(compiled_prog,
feed=feed_dict,
fetch_list=['fc_0.b_0'])
if not np.array_equal(fetch_val1, fetch_val2):
print("Iter: %d" % i)
for i in range(len(fetch_val1)):
if(fetch_val1[i] != fetch_val2[i]):
print("index: %d, val1: %.12f, val2: %.12f" % (i, fetch_val1[i], fetch_val2[i]))build_strategy.fuse_all_optimizer_ops set to False, the experimental result is consistent build_strategy.fuse_all_optimizer_ops set to True, the flowowing diff appears:
λ yq01-gpu-255-137-12-00 /work/self python fuse_test_diff.py
grep: warning: GREP_OPTIONS is deprecated; please use an alias or script
I1120 13:06:00.144999 27199 parallel_executor.cc:423] The number of CPUPlace, which is used in ParallelExecutor, is 1. And the Program will be copied 1 copies
W1120 13:06:00.145452 27199 fuse_optimizer_op_pass.cc:191] Find sgd operators : 2, and 2 for dense gradients. To make the speed faster, those optimization are fused during training.
I1120 13:06:00.146219 27199 build_strategy.cc:364] SeqOnlyAllReduceOps:0, num_trainers:1
I1120 13:06:00.146730 27199 parallel_executor.cc:287] Inplace strategy is enabled, when build_strategy.enable_inplace = True
I1120 13:06:00.147424 27199 parallel_executor.cc:370] Garbage collection strategy is enabled, when FLAGS_eager_delete_tensor_gb = 0
Iter: 1
index: 6, val1: -0.000070472430, val2: -0.000070472437
Iter: 2
index: 0, val1: -0.000048413985, val2: -0.000048413989
index: 6, val1: -0.000105456667, val2: -0.000105456682Notice that the difference in diff is very small, and it is beyond the represent range of float.
The difference between setting fuse_all_optimizer_ops or not
build_strategy.fuse_all_optimizer_ops set to True
会将两个sgd将要计算的fc_0.b_0和fc_0.w_0连接到一块内存中,将这块内存整体作为SGD Op的输入和输出去计算,通过GLOG日志,可以看到这一过程: (The two SGD operators’ Input fc_0.b_0 and fc_0.w_0 will be connected to a continuous memory, and the whole memory is calculated as the input and output of SGD Op. Through the GLOG log, you can see this process:)
$GLOG_v=6 python fuse_test_diff.py
I1120 13:13:42.773070 27398 operator.cc:152] CPUPlace Op(coalesce_tensor), inputs:{Input[fc_0.b_0:float[10]({}), fc_0.w_0:float[784, 10]({})]}, outputs:{FusedOutput[@FUSEDVAR@_sgd_Param_fc_0.b_0:[0]({})], Output[fc_0.b_0:float[10]({}), fc_0.w_0:float[784, 10]({})]}.
I1120 13:13:42.773128 27398 operator.cc:986] expected_kernel_key:data_type[float]:data_layout[ANY_LAYOUT]:place[CPUPlace]:library_type[PLAIN]
I1120 13:13:42.773192 27398 tensor_util.cu:28] TensorCopy 10 from CPUPlace to CPUPlace
I1120 13:13:42.773275 27398 tensor_util.cu:28] TensorCopy 784, 10 from CPUPlace to CPUPlace
I1120 13:13:42.773368 27398 operator.cc:172] CPUPlace Op(coalesce_tensor), inputs:{Input[fc_0.b_0:float[10]({}), fc_0.w_0:float[784, 10]({})]}, outputs:{FusedOutput[@FUSEDVAR@_sgd_Param_fc_0.b_0:float[9216]({})], Output[fc_0.b_0:float[10]({}), fc_0.w_0:float[784, 10]({})]}.这里连接起来的内存长度是9216,进行了一些内存补齐操作,比如第一个变量fc_0.b_0 10个float会先补齐到1024个float,再连接后面的fc_0.w_0,所以这个9216计算过程是: (The memory length connected here is 9216, and some memory alignment operations are performed. For example, the first variable fc_0.b_0 has 10 float var will be first filled to 1024 float var, and then connected to the following fc_0.w_0, so this 9216 calculation process:)
1024(10 alignment)+8192(7840 alignment)=9216
build_strategy.fuse_all_optimizer_ops set toFalse
PE的graph没有变化,与Executor执行的结构一致 (The PE graph has no change and is consistent with the structure executed by the Executor.)
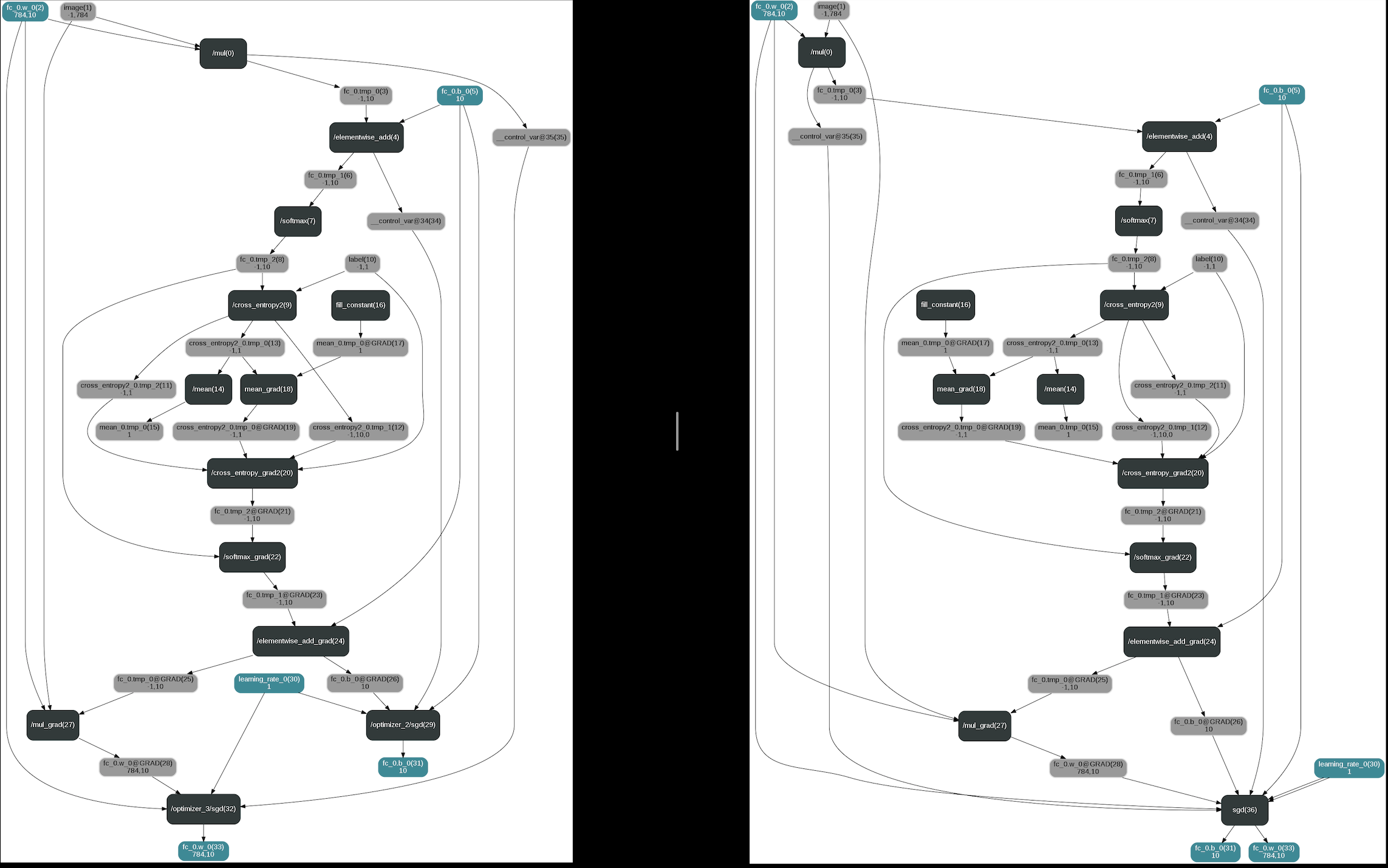
The difference between graphs
On the left is the graph with build_strategy.fuse_all_optimizer_ops set to False On the right is the graph with build_strategy.fuse_all_optimizer_ops set to True.
目前的一些实验
(Some current experiments)
目前做了一些实验和分析,但还是不明白问题的根源是什么,这些分析可能成为线索,列举如下:
- coalesce tensor op里面,fuse前后copy的数据一致,排除最开始fuse的时候就出错的可能
- sgd里面,找到fc_0.b_0的var,创建副本,计算,和总体计算结果切分后一致,排除由于连续内存的填充区域可能引入计算干扰
- fetch fc_0.w_0不出错,fc_0.b_0很容易就出错
- 更换w和b的内存顺序,w放到b前面,仍然出错
- 将fc_0.w_0缩短到[1, 10],和fc_0.b_0一样长,尝试多次也没有出错
- 手写实现sgd的运算,不使用现在的jit kernel,没有diff
- 单独输入数据验证sgd op jit kernel,数据长度从1-10000都没有diff,只是补齐内存的时候有diff
- fuse补齐的长度现在是1024,对于10个float长的fc_0.b_0,由10补齐为11-15计算正确,补齐为16或以上长度,计算出现diff
- sgd与adam kernel有diff,momentum kernel计算无diff
(I have try some experiments and analysis, but I still don't understand what the error is. These analyses may become clues, as listed below:
- coalesce_tensor_op, the data before and after the copy because of fuse is consistent, the possibility of error introduced by fuse is excluded
- In sgd, find the var of fc_0.b_0, create a copy and calculate it independently, and the result is consistent with the overall calculation result, excluding the calculation of interference due to the filled area of contiguous memory.
- fetch fc_0.w_0 does not go wrong, fc_0.b_0 is easy to make diff
- Replace the memory order of w and b, put w in front of b, still error
- Shorten fc_0.w_0 to [1, 10], make its length equal to fc_0.b_0, and try again, w has no diff
- Hand written sgd operation, do not use the current jit kernel, no diff
- Enter the data separately to verify the sgd op jit kernel. The data length is from 1 to 10000 without diff, but there is diff when the memory is aligned.
- The length of the fuse alignment is now 1024. For 10 float var, the length of fc_0.b_0 is calculated correct by 10 to 11-15, and diff is occured when align to 16 or more.
- sgd and adam kernel have diff, momentum kernel calculates no diff)