【MKL】Different output with different version of libmklml_intel.so
Created by: Aurelius84
I'm training a model on CPU machine with paddle, but the precision (PNR) can not converge up to the baseline with same train dataset.
I found that the result trained by paddle whl with 2014MKL is better than the 2019MKL.
-
2019MKLmeans to compile paddle with 2019libmklml_intel.so, which is used by default in Paddle. -
2014MKLmeans to compile paddle with 2014libmklml_intel.so - The result of
Baselineis trained by other framework tools based on 2014MKL.
There are many Matrix multiplication in my model, such as blas.MatMul or blas.GEMM. I found the output of Matrix multiplication has different result while using different version libmklml_intel.so to compile paddle whl.
I'm not sure how the difference output of MatMul or GEMM influence the precision. I would appreciate it very much if relevant developers can help to follow this problem.
See details as follows:
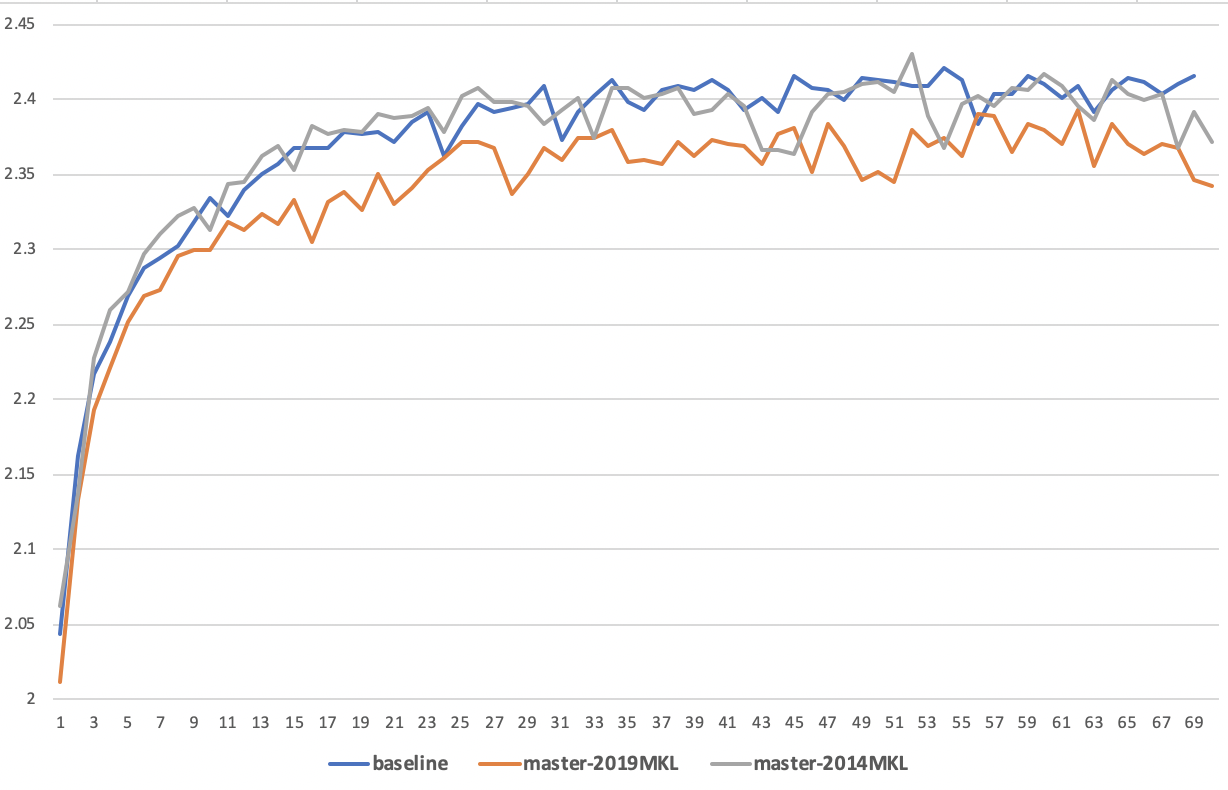
| result | Baseline | 2019MKL | 2014MKL |
|---|---|---|---|
| max(PNR) | 2.4207 | 2.3924 | 2.4303 |
How to reproduce with Docker:
1. Enviroment & Version
- CentOS release 6.3 (Final)
- docker image:
docker.paddlepaddlehub.com/paddle_manylinux_devel:cuda8.0_cudnn7 - python:
2.7.15
2. build paddle
- Compile with 2019 MKL
1. git clone https://github.com/PaddlePaddle/Paddle.git
2. cd Paddle & make build
3. comopile
export LD_LIBRARY_PATH=/opt/_internal/cpython-2.7.11-ucs4/lib:${LD_LIBRARY_PATH#/opt/_internal/cpython-2.7.11-ucs2/lib:}
cmake .. ${PYTHON_FLAGS} -DWITH_DISTRIBUTE=ON -DWITH_GRPC=ON -DWITH_BRPC=OFF -DWITH_FAST_BUNDLE_TEST=OFF -DWITH_PROFILER=OFF -DPY_VERSION=2.7 -DWITH_FLUID_ONLY=ON -DWITH_GPU=OFF -DWITH_TESTING=OFF -DCMAKE_BUILD_TYPE=Release -DWITH_MKL=ON -DWITH_MKLDNN=OFF
make -j$(nproc)- Compile with 2014 MKL
1. git clone https://github.com/PaddlePaddle/Paddle.git
2. cd Paddle & make build
3. comopile
export LD_LIBRARY_PATH=/opt/_internal/cpython-2.7.11-ucs4/lib:${LD_LIBRARY_PATH#/opt/_internal/cpython-2.7.11-ucs2/lib:}
cmake .. ${PYTHON_FLAGS} -DWITH_DISTRIBUTE=ON -DWITH_GRPC=ON -DWITH_BRPC=OFF -DWITH_FAST_BUNDLE_TEST=OFF -DWITH_PROFILER=OFF -DPY_VERSION=2.7 -DWITH_FLUID_ONLY=ON -DWITH_GPU=OFF -DWITH_TESTING=OFF -DCMAKE_BUILD_TYPE=Release -DWITH_MKL=ON -DWITH_MKLDNN=OFF
# here you should put 2014 verison libmklml_intel.so into build/2014_libmklml_intel.so
cp 2014_libmklml_intel.so third_party/install/mklml/lib/libmklml_intel.so
cp 2014_libmklml_intel.so third_party/mklml/src/extern_mklml/lib/libmklml_intel.so
make -j$(nproc)3. check diff
You can compare the output of fluid.layers.fc by feeding the same data and weight. Here is my scripts. Firstly, you should save x、y into .bin file to keep feed data same.
import paddle.fluid as fluid
import numpy as np
shape = [16, 384]
x = fluid.data(shape=shape, dtype='float32', name='x')
#y = fluid.data(shape=shape, dtype='float32', name='y')
#z = fluid.layers.matmul(x, y, transpose_y=True)
##### run me only once ###
x_data = np.random.random(shape).astype('float32')
y_data = np.random.random([shape[1], 128]).astype('float32')
x_data.tofile('x.bin')
y_data.tofile('y.bin')
#### end #######
x_data = np.fromfile('x.bin', dtype=np.float32)
x_data = x_data.reshape(shape)
y_data = np.fromfile('y.bin', dtype=np.float32)
y_data = y_data.reshape([shape[1], 128])
z = fluid.layers.fc(x, size=128, param_attr=fluid.initializer.NumpyArrayInitializer(y_data))
place = fluid.CPUPlace()
exe = fluid.Executor(place)
exe.run(fluid.default_startup_program())
res = exe.run(feed = {'x': x_data}, fetch_list=[z])
np.savetxt('res.txt', res[0].reshape(16, -1))You should install paddle whl with different version libmklml_intel.so and run above script to save result into res.txt. And reinstall another version paddle whl to generate new res.txt.
Then just run followed code to check the difference:
import numpy as np
res_2014 = np.loadtxt("res.txt_fc_2014")
res_2019 = np.loadtxt("res.txt_fc_2019")
print res_2014-res_2019Ouput may be like:
[[ 2.28881836e-05 -2.28881836e-05 1.52587891e-05 ... 3.05175781e-05
3.05175781e-05 3.81469727e-05]
[ 0.00000000e+00 1.52587891e-05 2.28881836e-05 ... 9.15527344e-05
-7.62939453e-06 7.62939453e-06]
[ 6.10351562e-05 -3.05175781e-05 1.52587891e-05 ... -7.62939453e-06
1.52587891e-05 7.62939453e-06]
...
[ 1.52587891e-05 0.00000000e+00 5.34057617e-05 ... -4.57763672e-05
0.00000000e+00 -1.52587891e-05]
[-3.05175781e-05 2.28881836e-05 6.86645508e-05 ... -1.52587891e-05
7.62939453e-06 3.81469727e-05]
[-6.10351562e-05 -3.81469727e-05 4.57763672e-05 ... 7.62939453e-06
-3.05175781e-05 0.00000000e+00]]