paddle 计算double grad 报错
Created by: LDOUBLEV
本地环境:
cuda 9, cudnn7, python3.6
问题描述,希望实现的功能是:
y = f(x) dydx = fluid.gradient(y, x) dydxdy = fluid.gradient(dydx*x, y)
代码:
import paddle.fluid as fluid
import numpy as np
def test_grad_grad():
"""validation the validation of mul double grad"""
train_program = fluid.Program()
start_program = fluid.Program()
place = fluid.CUDAPlace(0)
#place = fluid.CPUPlace()
with fluid.program_guard(train_program, start_program):
rng = np.random.RandomState(0)
rng = np.random
inp_ = rng.uniform(-1, 1, [32, 24]).astype('float32')
w1_ = rng.uniform(-1, 1, [24, 50]).astype('float32')
w2_ = rng.uniform(-1, 1, [50, 14]).astype('float32')
yg_ = rng.uniform(-1, 1, [2, ]).astype('float32')
inp = fluid.layers.data('inp', [32, 24], append_batch_size=False)
w1 = fluid.layers.data('w1', [24, 50], append_batch_size=False)
w2 = fluid.layers.data('w2', [50, 14], append_batch_size=False)
yg = fluid.layers.data('yg', [2, ], append_batch_size=False)
inp.stop_gradient = False
w1.stop_gradient = False
w2.stop_gradient = False
yg.stop_gradient = False
y = fluid.layers.mul(fluid.layers.mul(inp, w1), w2)
f = fluid.layers.reshape(y, [-1])
x = [w1, w2]
dfdx_f1 = fluid.gradients(f, x, f)
# double gradient
dfdx_x_ = fluid.gradients([dfdx_f1[0]*x[0], dfdx_f1[1]*x[1]], f)
print(dfdx_x_)
print( train_program, file=open("program.txt", 'wt'))
exe = fluid.Executor(place)
exe.run(program=fluid.default_startup_program())
compiled_prog = fluid.compiler.CompiledProgram(train_program)
res = exe.run(compiled_prog, feed={'inp':inp_, 'w1':w1_, 'w2':w2_, 'yg':yg_},
fetch_list=[dfdx_f1[0].name, dfdx_f1[1].name,
dfdx_x_[0].name])
print(res)
test_grad_grad()
报错截图
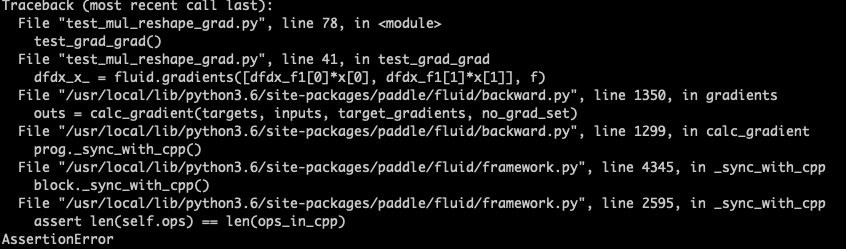
计算第二次梯度的时候len(self.ops)和 len(ops_in_cpp)不相等;这段代码十月之前在paddle上还可以正常运行