多GPU all_reduce_deps_pass.cc 报错
Created by: parap1uie-s
Paddle版本:1.5.2 - GPU 运行环境:单GPU / 多GPU
BUG描述:
-
同一份未做任何改动的代码,可正常在单GPU环境下运行;但多GPU环境下报错,errorlog文末
-
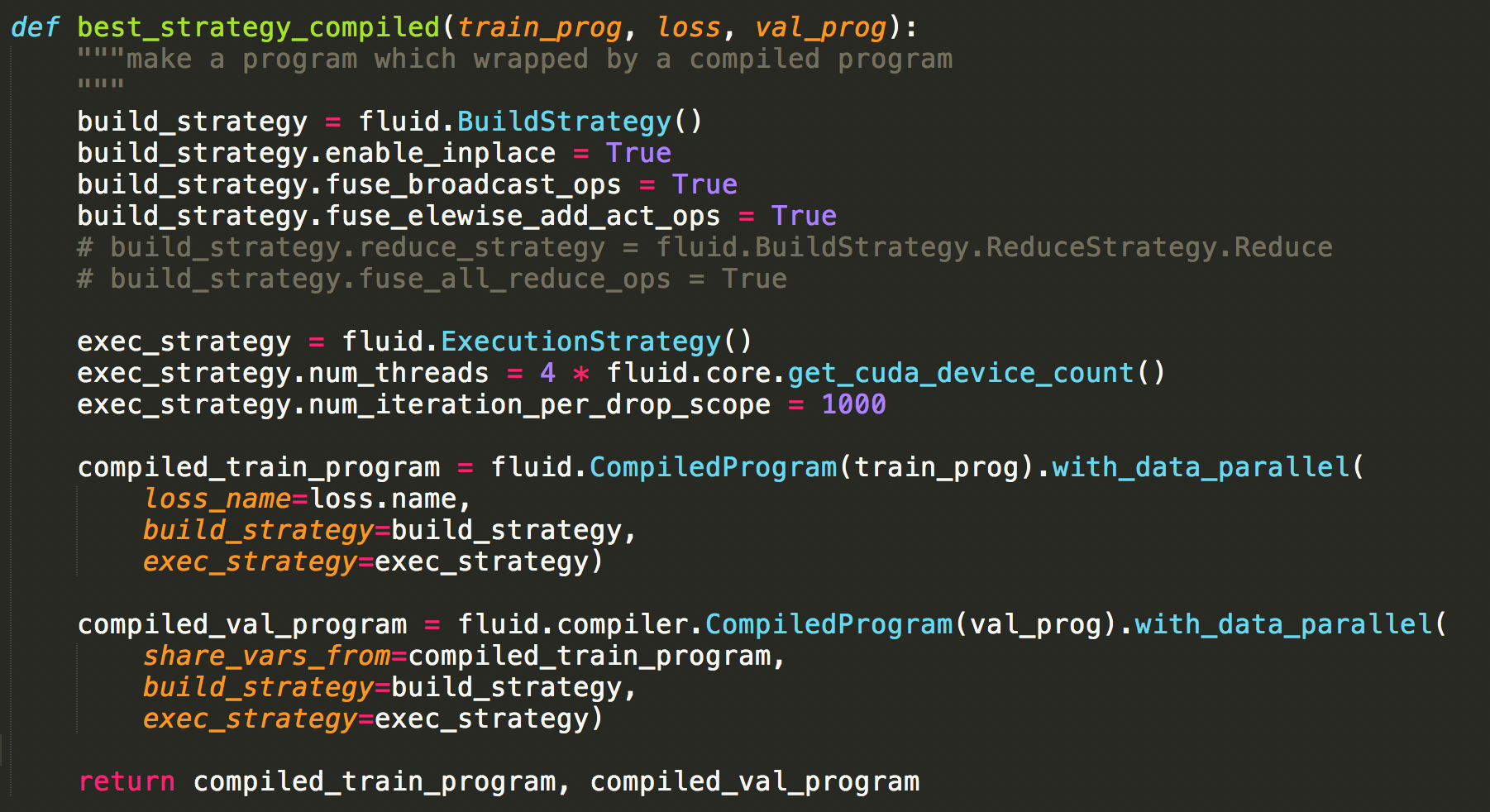
train_prog使用CompiledProgram编译,并在with_data_parallel中设置了build_strategy和exec_strategy。相关设置如图:

-
经阅读errorlog,怀疑是
build_strategy.fuse_all_reduce_ops = True的问题,注释后多GPU下可正常运行,无报错。 -
查阅文档发现,fuse_all_reduce_ops并未被列入
fluid.BuildStrategy()的属性中,但在文档的进阶使用-优秀实践-单机训练优秀实践中出现。 -
先前使用官方实现的DenseNet121训练模型,开启fuse_all_reduce_ops也无报错。报错代码使用了自定义的模型结构,具体由哪一个op导致fuse_all_reduce_ops报错,仍需进一步定位。
paddle.fluid.core_avx.EnforceNotMet: Enforce failed. Expected left_in_vars.size() == right_in_vars.size(), but received left_in_vars.size():2 != right_in_vars.size():4. at [/paddle/paddle/fluid/framework/ir/multi_devices_graph_pass/all_reduce_deps_pass.cc:134] PaddlePaddle Call Stacks: 0 0x7fbce2f03278p void paddle::platform::EnforceNotMet::Initstd::string(std::string, char const*, int) + 360 1 0x7fbce2f035c7p paddle::platform::EnforceNotMet::EnforceNotMet(std::string const&, char const*, int) + 87 2 0x7fbce4d7294dp paddle::framework::ir::AllReduceDepsPass::GetSortedAllReduceOps(std::unordered_set<paddle::framework::details::OpHandleBase*, std::hashpaddle::framework::details::OpHandleBase*, std::equal_topaddle::framework::details::OpHandleBase*, std::allocatorpaddle::framework::details::OpHandleBase* > const&, std::vector<paddle::framework::details::OpHandleBase*, std::allocatorpaddle::framework::details::OpHandleBase* >) const::{lambda(paddle::framework::details::OpHandleBase const, paddle::framework::details::OpHandleBase const*)#1 (closed)}::operator()(paddle::framework::details::OpHandleBase const*, paddle::framework::details::OpHandleBase const*) const + 749 3 0x7fbce4d72bbcp void std::insertion_sort<gnu_cxx::normal_iterator<paddle::framework::details::OpHandleBase**, std::vector<paddle::framework::details::OpHandleBase*, std::allocatorpaddle::framework::details::OpHandleBase* > >, paddle::framework::ir::AllReduceDepsPass::GetSortedAllReduceOps(std::unordered_set<paddle::framework::details::OpHandleBase*, std::hashpaddle::framework::details::OpHandleBase*, std::equal_topaddle::framework::details::OpHandleBase*, std::allocatorpaddle::framework::details::OpHandleBase* > const&, std::vector<paddle::framework::details::OpHandleBase*, std::allocatorpaddle::framework::details::OpHandleBase* >) const::{lambda(paddle::framework::details::OpHandleBase const, paddle::framework::details::OpHandleBase const*)#1 (closed)}>(gnu_cxx::normal_iterator<paddle::framework::details::OpHandleBase**, std::vector<paddle::framework::details::OpHandleBase*, std::allocatorpaddle::framework::details::OpHandleBase* > >, paddle::framework::ir::AllReduceDepsPass::GetSortedAllReduceOps(std::unordered_set<paddle::framework::details::OpHandleBase*, std::hashpaddle::framework::details::OpHandleBase*, std::equal_topaddle::framework::details::OpHandleBase*, std::allocatorpaddle::framework::details::OpHandleBase* > const&, std::vector<paddle::framework::details::OpHandleBase*, std::allocatorpaddle::framework::details::OpHandleBase* >) const::{lambda(paddle::framework::details::OpHandleBase const, paddle::framework::details::OpHandleBase const*)#1 (closed)}, paddle::framework::ir::AllReduceDepsPass::GetSortedAllReduceOps(std::unordered_set<paddle::framework::details::OpHandleBase*, std::hashpaddle::framework::details::OpHandleBase*, std::equal_topaddle::framework::details::OpHandleBase*, std::allocatorpaddle::framework::details::OpHandleBase* > const&, std::vector<paddle::framework::details::OpHandleBase*, std::allocatorpaddle::framework::details::OpHandleBase* >) const::{lambda(paddle::framework::details::OpHandleBase const, paddle::framework::details::OpHandleBase const*)#1 (closed)}) + 140 4 0x7fbce4d75d6fp paddle::framework::ir::AllReduceDepsPass::GetSortedAllReduceOps(std::unordered_set<paddle::framework::details::OpHandleBase*, std::hashpaddle::framework::details::OpHandleBase*, std::equal_topaddle::framework::details::OpHandleBase*, std::allocatorpaddle::framework::details::OpHandleBase* > const&, std::vector<paddle::framework::details::OpHandleBase*, std::allocatorpaddle::framework::details::OpHandleBase* >) const + 511 5 0x7fbce4d76341p paddle::framework::ir::AllReduceDepsPass::GetSortedAllReduceOps(paddle::framework::ir::Graph const&) const + 1409 6 0x7fbce4d76893p paddle::framework::ir::AllReduceDepsPass::ApplyImpl(paddle::framework::ir::Graph) const + 67 7 0x7fbce4f8dba1p paddle::framework::ir::Pass::Apply(paddle::framework::ir::Graph*) const + 209 8 0x7fbce4ce5d29p paddle::framework::details::BuildStrategy::Apply(paddle::framework::ir::Graph*, std::vector<boost::variant<paddle::platform::CUDAPlace, paddle::platform::CPUPlace, paddle::platform::CUDAPinnedPlace, boost::detail::variant::void, boost::detail::variant::void, boost::detail::variant::void, boost::detail::variant::void, boost::detail::variant::void, boost::detail::variant::void, boost::detail::variant::void, boost::detail::variant::void, boost::detail::variant::void, boost::detail::variant::void, boost::detail::variant::void_, boost::detail::variant::void_, boost::detail::variant::void_, boost::detail::variant::void_, boost::detail::variant::void_, boost::detail::variant::void_, boost::detail::variant::void_>, std::allocator<boost::variant<paddle::platform::CUDAPlace, paddle::platform::CPUPlace, paddle::platform::CUDAPinnedPlace, boost::detail::variant::void_, boost::detail::variant::void_, boost::detail::variant::void_, boost::detail::variant::void_, boost::detail::variant::void_, boost::detail::variant::void_, boost::detail::variant::void_, boost::detail::variant::void_, boost::detail::variant::void_, boost::detail::variant::void_, boost::detail::variant::void_, boost::detail::variant::void_, boost::detail::variant::void_, boost::detail::variant::void_, boost::detail::variant::void_, boost::detail::variant::void_, boost::detail::variant::void_> > > const&, std::string const&, std::vector<paddle::framework::Scope*, std::allocatorpaddle::framework::Scope* > const&, unsigned long const&, bool, paddle::platform::NCCLCommunicator*) const + 1849 9 0x7fbce30ddf7ap paddle::framework::ParallelExecutor::ParallelExecutor(std::vector<boost::variant<paddle::platform::CUDAPlace, paddle::platform::CPUPlace, paddle::platform::CUDAPinnedPlace, boost::detail::variant::void_, boost::detail::variant::void_, boost::detail::variant::void_, boost::detail::variant::void_, boost::detail::variant::void_, boost::detail::variant::void_, boost::detail::variant::void_, boost::detail::variant::void_, boost::detail::variant::void_, boost::detail::variant::void_, boost::detail::variant::void_, boost::detail::variant::void_, boost::detail::variant::void_, boost::detail::variant::void_, boost::detail::variant::void_, boost::detail::variant::void_, boost::detail::variant::void_>, std::allocator<boost::variant<paddle::platform::CUDAPlace, paddle::platform::CPUPlace, paddle::platform::CUDAPinnedPlace, boost::detail::variant::void_, boost::detail::variant::void_, boost::detail::variant::void_, boost::detail::variant::void_, boost::detail::variant::void_, boost::detail::variant::void_, boost::detail::variant::void_, boost::detail::variant::void_, boost::detail::variant::void_, boost::detail::variant::void_, boost::detail::variant::void_, boost::detail::variant::void_, boost::detail::variant::void_, boost::detail::variant::void_, boost::detail::variant::void_, boost::detail::variant::void_, boost::detail::variant::void_> > > const&, std::vector<std::string, std::allocatorstd::string > const&, std::string const&, paddle::framework::Scope*, std::vector<paddle::framework::Scope*, std::allocatorpaddle::framework::Scope* > const&, paddle::framework::details::ExecutionStrategy const&, paddle::framework::details::BuildStrategy const&, paddle::framework::ir::Graph*) + 6330 10 0x7fbce2f95f08p 11 0x7fbce2f35d56p 12 0x7fbd27693b94p _PyCFunction_FastCallDict + 340 13 0x7fbd27693fafp _PyObject_FastCallDict + 703 14 0x7fbd27698a70p _PyObject_Call_Prepend + 208 15 0x7fbd2769399ep PyObject_Call + 62 16 0x7fbd276f002bp 17 0x7fbd277239b7p 18 0x7fbd27693d7bp _PyObject_FastCallDict + 139 19 0x7fbd277237cep 20 0x7fbd27745cbap _PyEval_EvalFrameDefault + 762 21 0x7fbd2771ca94p 22 0x7fbd2771d941p 23 0x7fbd27723755p 24 0x7fbd27746a7ap _PyEval_EvalFrameDefault + 4282 25 0x7fbd2771d70bp 26 0x7fbd27723755p 27 0x7fbd27745cbap _PyEval_EvalFrameDefault + 762 28 0x7fbd2771ca94p 29 0x7fbd2771d941p 30 0x7fbd27723755p 31 0x7fbd27746a7ap _PyEval_EvalFrameDefault + 4282 32 0x7fbd2771cdaep 33 0x7fbd2771d941p 34 0x7fbd27723755p 35 0x7fbd27746a7ap _PyEval_EvalFrameDefault + 4282 36 0x7fbd2771cdaep 37 0x7fbd2771d941p 38 0x7fbd27723755p 39 0x7fbd27745cbap _PyEval_EvalFrameDefault + 762 40 0x7fbd2771e459p PyEval_EvalCodeEx + 809 41 0x7fbd2771f1ecp PyEval_EvalCode + 28 42 0x7fbd277999a4p 43 0x7fbd27799da1p PyRun_FileExFlags + 161 44 0x7fbd27799fa4p PyRun_SimpleFileExFlags + 452 45 0x7fbd2779da9ep Py_Main + 1598 46 0x7fbd276654bep main + 238 47 0x7fbd26da6b45p __libc_start_main + 245 48 0x7fbd2774c773p