设置sync_batch_norm=True,在训练中会无规律卡住,出现死机状态(Gpu 使用率0,进程还在)
Created by: Exception-star
因为国庆前提的问题,到现在也没有人解答,另起一个issue 相关问题链接:https://github.com/PaddlePaddle/Paddle/issues/19934
问题描述:
训练网络时程序会无规律的出现死机状态,就是程序不使用CPU和GPU了,但是保持原占用状态(比如显卡占用10G,但是利用率为0,没有其他程序抢资源)。这种情况碰到了好多次,一次发生在重复训练了5轮后的某一阶段,另一次发生在第7次重复训练的某一阶段,还有一次是在第一个epoch,这些情况都出现在epoch的最后一个step。
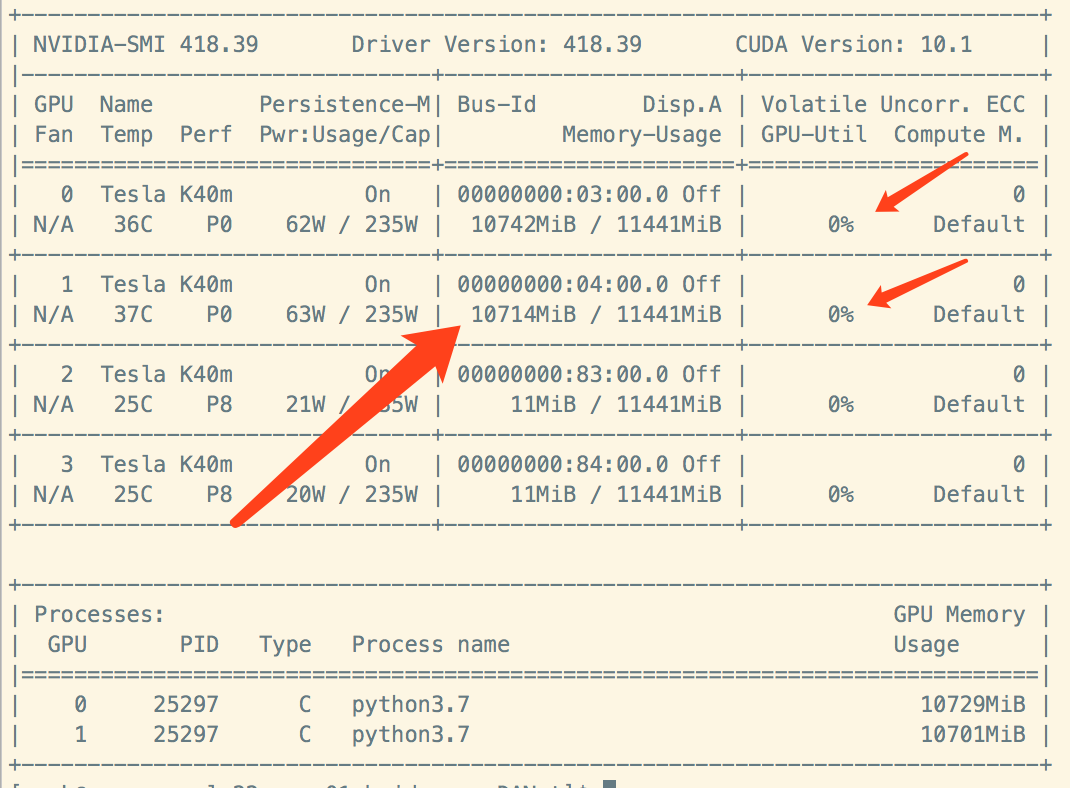
如果是这种情况,大概率是某个卡上没数据。
我的reader代码:
def mapper_train(sample):
image_path, label_path, city = sample
image = Image.open(image_path, mode='r').convert('RGB')
label = Image.open(label_path, mode='r')
image, label = city.sync_transform(image, label) # train_transform同步变换(含增强)
image_array = np.array(image) # HWC
label_array = np.array(label) # HW
image_array = image_array.transpose((2, 0, 1)) # CHW
image_array = image_array / 255.0 # 归一化
image_array = (image_array - data_mean) / data_std # 标准化
image_array = image_array.astype('float32')
label_array = label_array.astype('int64')
return image_array, label_arraydef cityscapes_train(data_root='./dataset', base_size=520, crop_size=480, scale=True, xmap=True):
city = CityScapes(root=data_root, split='train', base_size=base_size, crop_size=crop_size, scale=scale)
image_path, label_path = city.get_path_pairs()
def reader():
for i in range(len(image_path)):
if i == 0: # 遍历所有样本后同步打乱path_pairs,提高泛化能力
cc = list(zip(image_path, label_path))
random.shuffle(cc)
image_path[:], label_path[:] = zip(*cc)
yield image_path[i], label_path[i], city
if xmap:
return paddle.reader.xmap_readers(mapper_train, reader, 4, 32)
else:
return paddle.reader.map_readers(mapper_train, reader)
with fluid.program_guard(train_prog, start_prog):
with fluid.unique_name.guard():
# train_py_reader
train_py_reader = fluid.io.PyReader(feed_list=[image, label],
capacity=4,
use_double_buffer=True,
iterable=False)
train_data = cityscapes_train(data_root=data_root,
base_size=args.base_size,
crop_size=args.crop_size,
scale=args.scale,
xmap=False)
batch_train_data = paddle.batch(paddle.reader.shuffle(
train_data, buf_size=batch_size * 3),
batch_size=batch_size,
drop_last=True)
train_py_reader.decorate_sample_list_generator(batch_train_data)
model = get_model(args)
pred, pred2, pred3 = model(image)
# print(pred.shape)
train_loss = loss_fn(pred, pred2, pred3, label)
train_avg_loss = fluid.layers.mean(train_loss)
optimizer = optimizer_setting(args)
optimizer.minimize(train_avg_loss)如何解决这个问题???