strategy.sync_batch_norm=True训练报错, 不使用这个策略可以运行
Created by: Exception-star
- 版本、环境信息: 1)PaddlePaddle版本:1.5.2 2)GPU:4 个k40m 4)系统环境:linux、Python3.7 cuda:8.0 cudnn:7.2
模型名称 :DANet(Dual Attention Network for Scene Segmentation)
使用数据集名称 :Cityscapes
模型链接
- 训练信息
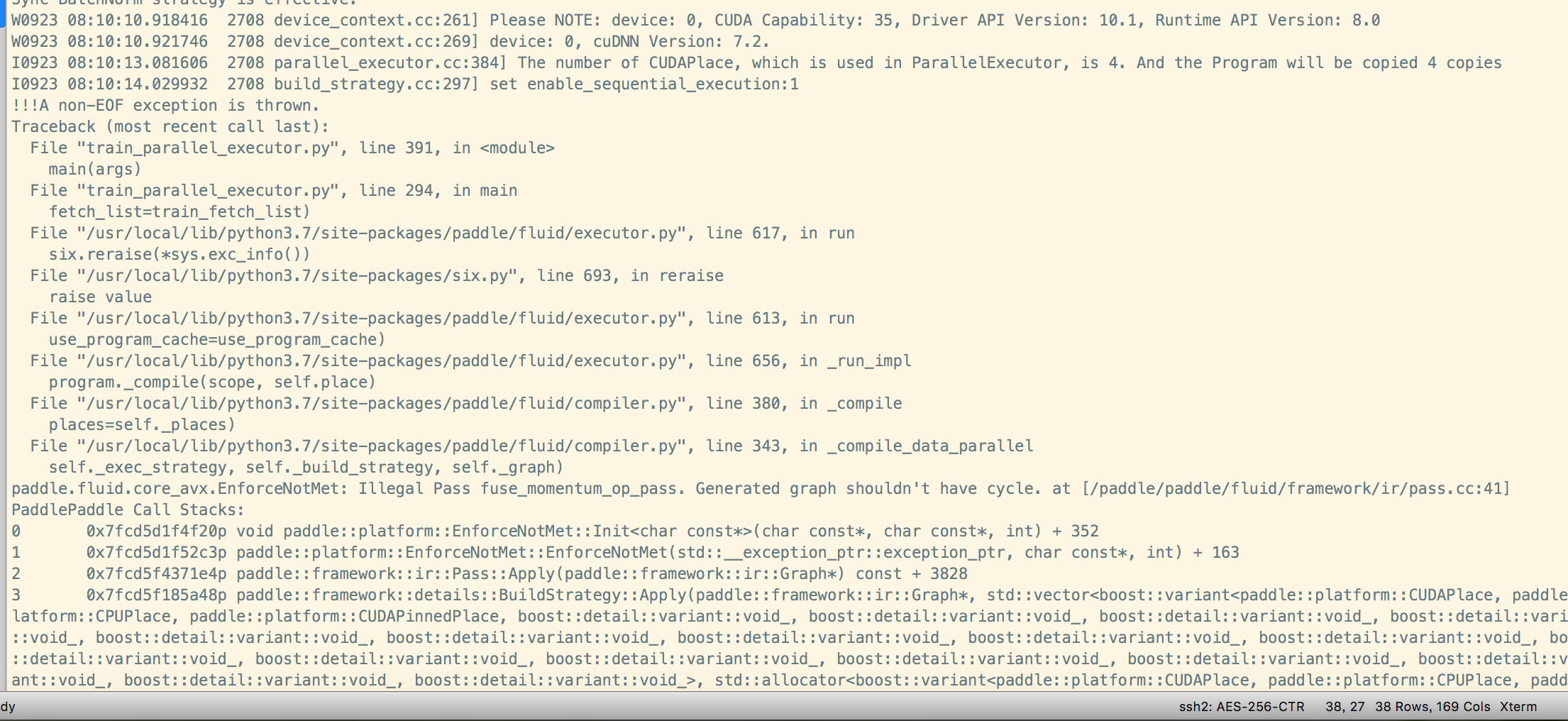
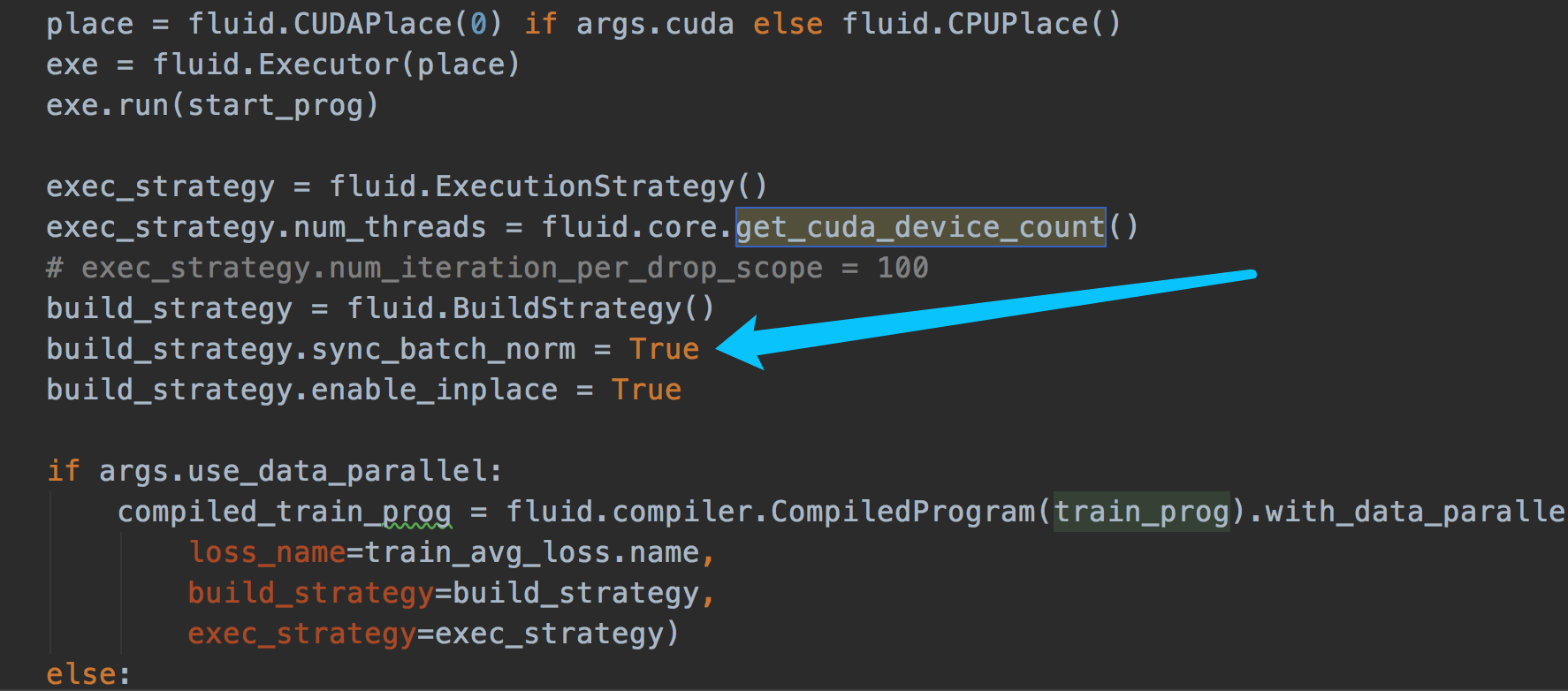
- 问题描述:加了strategy.sync_batch_norm=True报错。不加不会报错
代码片段:
def main(args):
image_shape = args.crop_size
image = fluid.layers.data(name='image', shape=[3, image_shape, image_shape], dtype='float32')
label = fluid.layers.data(name='label', shape=[image_shape, image_shape], dtype='int64')
batch_size = args.batch_size
epoch_num = args.epoch_num
num_classes = args.num_classes
data_root = args.data_folder
# program
start_prog = fluid.default_startup_program()
train_prog = fluid.default_main_program()
# clone 必须在优化器之前
test_prog = train_prog.clone(for_test=True)
logging.basicConfig(level=logging.INFO, filename='{}/DANet_train_parallel_executor.log'.format(args.log_root),
format='%(asctime)s - %(name)s - %(levelname)s - %(message)s')
logging.info('DANet')
logging.info(args)
with fluid.program_guard(train_prog, start_prog):
with fluid.unique_name.guard():
# train_py_reader
train_py_reader = fluid.io.PyReader(feed_list=[image, label],
capacity=4,
use_double_buffer=True,
iterable=False)
train_data = cityscapes_train(data_root=data_root,
base_size=args.base_size,
crop_size=args.crop_size,
scale=args.scale,
xmap=False)
batch_train_data = paddle.batch(paddle.reader.shuffle(
train_data, buf_size=batch_size * 3),
batch_size=batch_size,
drop_last=True)
train_py_reader.decorate_sample_list_generator(batch_train_data)
model = get_model(args)
pred, pred2, pred3 = model(image)
# print(pred.shape)
train_loss = loss_fn(pred, pred2, pred3, label)
train_avg_loss = fluid.layers.mean(train_loss)
optimizer = optimizer_setting(args)
optimizer.minimize(train_avg_loss)
miou, wrong, correct = mean_iou(pred, label, num_classes=num_classes)
with fluid.program_guard(test_prog, start_prog):
with fluid.unique_name.guard():
test_py_reader = fluid.io.PyReader(feed_list=[image, label],
capacity=4,
iterable=False,
use_double_buffer=True)
val_data = cityscapes_val(data_root=data_root,
base_size=args.base_size,
crop_size=args.crop_size,
scale=args.scale,
xmap=False)
batch_test_data = paddle.batch(val_data,
batch_size=batch_size,
drop_last=True)
test_py_reader.decorate_sample_list_generator(batch_test_data)
model = get_model(args)
pred, pred2, pred3 = model(image)
test_loss = loss_fn(pred, pred2, pred3, label)
test_avg_loss = fluid.layers.mean(test_loss)
miou, wrong, correct = mean_iou(pred, label, num_classes=19)
place = fluid.CUDAPlace(0) if args.cuda else fluid.CPUPlace()
exe = fluid.Executor(place)
exe.run(start_prog)
exec_strategy = fluid.ExecutionStrategy()
exec_strategy.num_threads = fluid.core.get_cuda_device_count()
# exec_strategy.num_iteration_per_drop_scope = 100
build_strategy = fluid.BuildStrategy()
build_strategy.sync_batch_norm = True
build_strategy.enable_inplace = True
if args.use_data_parallel:
compiled_train_prog = fluid.compiler.CompiledProgram(train_prog).with_data_parallel(
loss_name=train_avg_loss.name,
build_strategy=build_strategy,
exec_strategy=exec_strategy)
else:
compiled_train_prog = train_prog
# 加载模型
save_dir = 'checkpoint_parallel_executor/DAnet_better_train_0.1829'
if os.path.exists(save_dir):
load_model(save_dir, exe, program=train_prog)
train_iou_manager = fluid.metrics.Accuracy()
train_avg_loss_manager = fluid.metrics.Accuracy()
test_iou_manager = fluid.metrics.Accuracy()
test_avg_loss_manager = fluid.metrics.Accuracy()
better_miou_train = 0
better_miou_test = 0
# train_loss_title = 'Train_loss'
# test_loss_title = 'Test_loss'
#
# train_iou_title = 'Train_mIOU'
# test_iou_title = 'Test_mIOU'
# plot_loss = Ploter(train_loss_title, test_loss_title)
# plot_iou = Ploter(train_iou_title, test_iou_title)
for epoch in range(epoch_num):
prev_time = datetime.now()
train_avg_loss_manager.reset()
train_iou_manager.reset()
logging.info('training, epoch = {}'.format(epoch + 1))
train_py_reader.start()
batch_id = 0
while True:
try:
train_fetch_list = [train_avg_loss, miou, wrong, correct]
train_avg_loss_value, train_iou_value, _, _ = exe.run(program=compiled_train_prog,
fetch_list=train_fetch_list)
# print(pred_s.shape)
train_iou_manager.update(train_iou_value, weight=batch_size)
train_avg_loss_manager.update(train_avg_loss_value, weight=batch_size)
batch_train_str = "epoch: {}, batch: {}, train_avg_loss: {:.6f}, " \
"train_miou: {:.6f}.".format(epoch + 1,
batch_id + 1,
train_avg_loss_value[0],
train_iou_value[0])
batch_id += 1
# if batch_id % 30 == 0:
logging.info(batch_train_str)
print(batch_train_str)
except fluid.core.EOFException:
train_py_reader.reset()
break
cur_time = datetime.now()
h, remainder = divmod((cur_time - prev_time).seconds, 3600)
m, s = divmod(remainder, 60)
time_str = " Time %02d:%02d:%02d" % (h, m, s)
train_str = "epoch: {}, train_avg_loss: {:.6f}, " \
"train_miou: {:.6f}.".format(epoch + 1,
train_avg_loss_manager.eval()[0],
train_iou_manager.eval()[0])
print(train_str + time_str + '\n')
logging.info(train_str + time_str)
# plot_loss.append(train_loss_title, epoch, train_avg_loss_manager.eval()[0])
# plot_loss.plot('./DANet_loss.jpg')
# plot_iou.append(train_iou_title, epoch, train_iou_manager.eval()[0])
# plot_iou.plot('./DANet_miou.jpg')
# save_model
if better_miou_train < train_iou_manager.eval()[0]:
shutil.rmtree('./checkpoint_parallel_executor/DAnet_better_train_{:.4f}'.format(better_miou_train),
ignore_errors=True)
better_miou_train = train_iou_manager.eval()[0]
logging.warning('better_train: {:.6f}, epoch: {}, successful save train model!\n'.format(better_miou_train, epoch + 1))
save_dir = './checkpoint_parallel_executor/DAnet_better_train_{:.4f}'.format(better_miou_train)
save_model(save_dir, exe, program=train_prog)