apply_graident之后再用fluid.gradients受影响,报错xx_grad_op没有grad
Created by: baiyfbupt
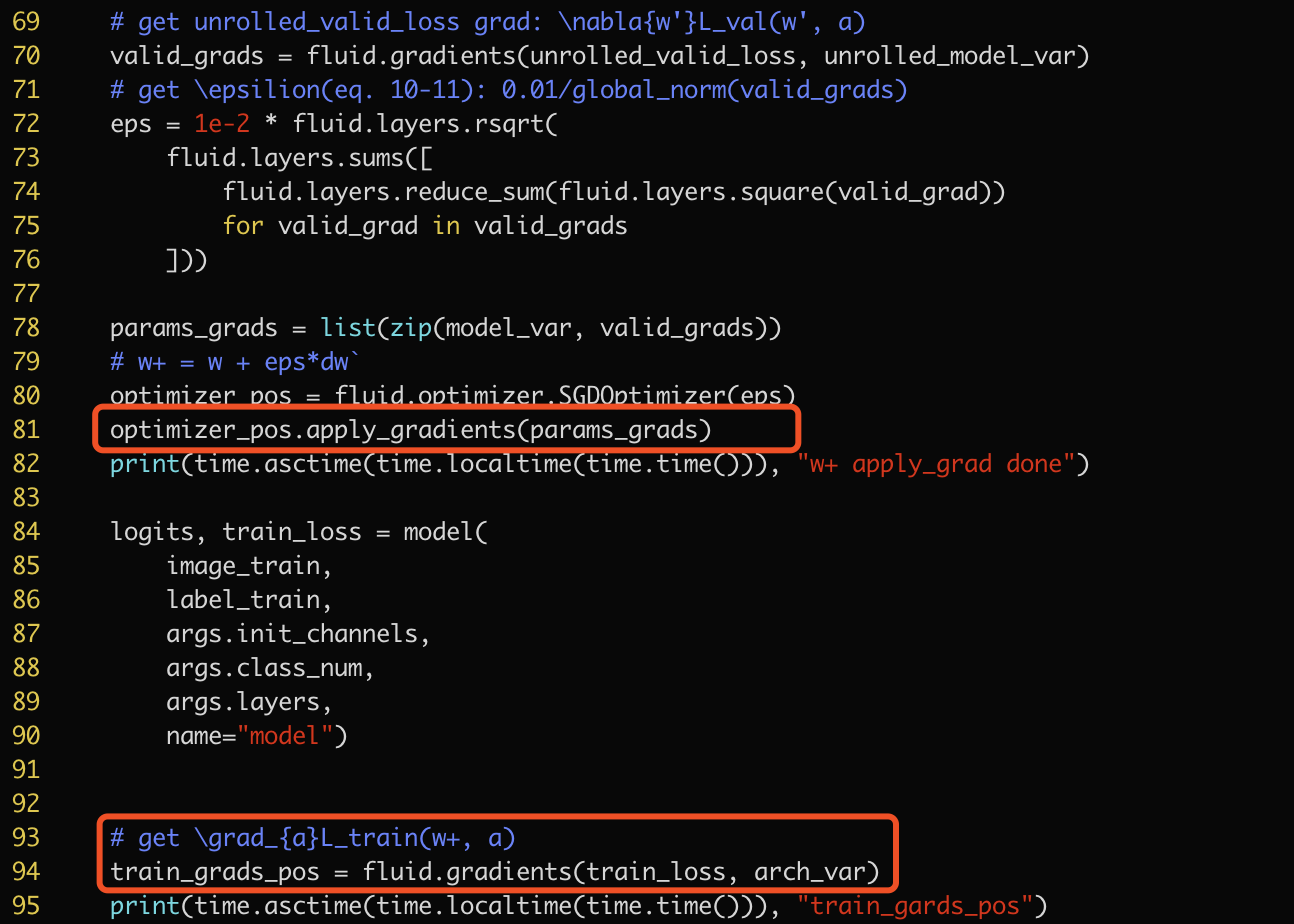 在用apply_gradient对模型中的一部分参数
在用apply_gradient对模型中的一部分参数model_var做更新之后,再求该模型loss对另一部分参数arch_var的导数会报错
 查了一下,是因为求导时,前面apply_gradient append进来的某个xx_grad_op也被backward.py用来求导引起的错误,但期望实现的是只对前向op求导
https://github.com/PaddlePaddle/Paddle/blob/21440b4d69d1a8b390ae62611b2ea0e90261e14c/python/paddle/fluid/backward.py#L431-L432
这一模型在tf用了同样的实现逻辑没有报错,请教下是因为paddle暂不支持这样的功能还是需要其他的操作?
查了一下,是因为求导时,前面apply_gradient append进来的某个xx_grad_op也被backward.py用来求导引起的错误,但期望实现的是只对前向op求导
https://github.com/PaddlePaddle/Paddle/blob/21440b4d69d1a8b390ae62611b2ea0e90261e14c/python/paddle/fluid/backward.py#L431-L432
这一模型在tf用了同样的实现逻辑没有报错,请教下是因为paddle暂不支持这样的功能还是需要其他的操作?