保存后模型可视化比模型定义最后输出多了一层scale
Created by: Overtown
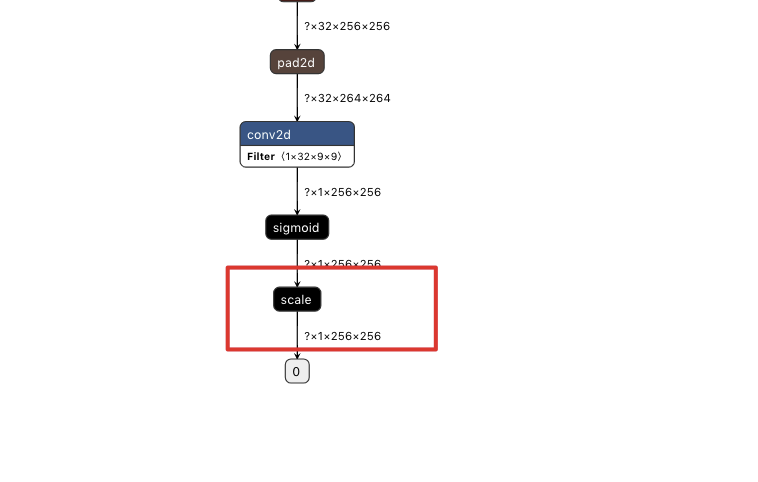 网络模型最后一层是sigmoid,但是保存下来的模型用netron可视化之后,发现多了scale层,请问是什么问题。网络定义的脚本如下:Net 函数是主体网络结构。
网络模型最后一层是sigmoid,但是保存下来的模型用netron可视化之后,发现多了scale层,请问是什么问题。网络定义的脚本如下:Net 函数是主体网络结构。
import paddle.fluid as fluid
import cv2, numpy
import os
class Canny():
def __init__(self, output_channels, base_channels):
self.out_c = output_channels
self.base_channels = base_channels
def ConvLayer(self, input_data, out_c, kernel_size, stride):
# only conv not include relu
padding_size = kernel_size // 2
x = fluid.layers.pad2d(input=input_data, paddings=[padding_size, padding_size, padding_size, padding_size], mode='reflect')
x = fluid.layers.conv2d(
input=x,
num_filters=out_c,
filter_size=kernel_size,
stride=stride,
padding=0,
groups=1,
act=None,
bias_attr=False,
name=None)
return x
def ResidualBlock(self, input_data, channels, kernel_size, stride):
norm = 'instance_norm'
x_conv1 = self.ConvLayer(input_data, channels, kernel_size, stride)
x_in1 = norm_layer(x_conv1, norm)
x_relu = fluid.layers.relu(x_in1)
x_conv2 = self.ConvLayer(x_relu, channels, kernel_size, stride)
x_in2 = norm_layer(x_conv2, norm)
x_out = x_in2 + input_data
return x_out
def ConvInReluLayer(self, input_data, channels, kernel_size, stride):
norm = 'instance_norm'
x_conv = self.ConvLayer(input_data, channels, kernel_size, stride)
x_in = norm_layer(x_conv, norm)
x_relu = fluid.layers.relu(x_in)
return x_relu
def Net(self, input_data):
# Encoder network
x = self.ConvInReluLayer(input_data, self.base_channels, kernel_size=9, stride=1)
x = self.ConvInReluLayer(x, 2*self.base_channels, kernel_size=3, stride=2)
x = self.ConvInReluLayer(x, 2*2*self.base_channels, kernel_size=3, stride=2)
# Residual Network
for i in range(5):
x = self.ResidualBlock(x, 2*2*self.base_channels, kernel_size=3, stride=1)
# Decoder Network
x = fluid.layers.resize_bilinear(x, scale=2.0)
x = self.ConvLayer(x, 2*self.base_channels, kernel_size=3, stride=1)
x = fluid.layers.relu(x)
x = fluid.layers.resize_bilinear(x, scale=2.0)
x = self.ConvLayer(x, self.base_channels, kernel_size=3, stride=1)
x = fluid.layers.relu(x)
x = self.ConvLayer(x, self.out_c, kernel_size=9, stride=1)
x = fluid.layers.sigmoid(x)
return x
def norm_layer(input, norm_type='batch_norm', name=None, is_test=False):
#print 'norm:', norm_type
if norm_type == 'batch_norm':
param_attr = fluid.ParamAttr(
name = None if name is None else name + '_w', initializer=fluid.initializer.Constant(1.0))
bias_attr = fluid.ParamAttr(
name = None if name is None else name + '_b', initializer=fluid.initializer.Constant(value=0.0))
return fluid.layers.batch_norm(
input,
param_attr=param_attr,
bias_attr=bias_attr,
is_test=is_test,
moving_mean_name=None if name is None else name + '_mean',
moving_variance_name=None if name is None else name + '_var')
elif norm_type == 'instance_norm':
helper = fluid.layer_helper.LayerHelper("instance_norm", **locals())
dtype = helper.input_dtype()
epsilon = 1e-5
mean = fluid.layers.reduce_mean(input, dim=[2, 3], keep_dim=True)
var = fluid.layers.reduce_mean(
fluid.layers.square(input - mean), dim=[2, 3], keep_dim=True)
if name is not None:
scale_name = name + "_scale"
offset_name = name + "_offset"
else:
scale_name = None
offset_name = None
scale_param = fluid.ParamAttr(
name=scale_name,
initializer=fluid.initializer.Constant(1.0),
trainable=True)
offset_param = fluid.ParamAttr(
name=offset_name,
initializer=fluid.initializer.Constant(0.0),
trainable=True)
scale = helper.create_parameter(
attr=scale_param, shape=input.shape[1:2], dtype=dtype)
offset = helper.create_parameter(
attr=offset_param, shape=input.shape[1:2], dtype=dtype)
tmp = fluid.layers.elementwise_mul(x=(input - mean), y=scale, axis=1)
tmp = tmp / fluid.layers.sqrt(var + epsilon)
tmp = fluid.layers.elementwise_add(tmp, offset, axis=1)
return tmp
else:
raise NotImplementedError("norm tyoe: [%s] is not support" % norm_type)