设置 FLAGS_fraction_of_gpu_memory_to_use=0.0 报错 cudaMemcpyAsync failed in GpuMemcpyAsync
Created by: OliverLPH
- 标题:设置 FLAGS_fraction_of_gpu_memory_to_use=0.0 预测报错 cudaMemcpyAsync failed in GpuMemcpyAsync
- 版本、环境信息: 1)PaddlePaddle版本:PaddlePaddle 1.5 3)GPU:P4, CUDA 8.0, cuDNN 7.2 4)系统环境:Ubuntu1604,Python 2.7 -预测信息 1)Python预测:TensorRT-4.0.1.6 2)CMake包含路径的完整命令
cmake .. \
-DWITH_FLUID_ONLY=ON \
-DWITH_SWIG_PY=OFF \
-DWITH_PYTHON=ON \
-DWITH_MKL=ON \
-DWITH_GPU=ON \
-DWITH_MKLDNN=OFF \
-DON_INFER=ON \
-DCMAKE_BUILD_TYPE=Release \
-DWITH_INFERENCE_API_TEST=ON \
-DWITH_TESTING=ON \
-DINFERENCE_DEMO_INSTALL_DIR=/root/.cache/inference_demo \
-DTENSORRT_ROOT=/TensorRT-4.0.1.6编译的时候,编入了TRT,但是验证了一下有无TRT问题是一致的。
3)API信息(如调用请提供) 4)预测库来源:ubuntu1604 gcc5.4 compile
- 复现信息:
理论上设置 export FLAGS_fraction_of_gpu_memory_to_use=0.0 是会在预测过程中动态分配内存,但是目前发现 face_box, Demark, life_feature, live1208这几个模型python预测会出这个问题。其他模型比如 resnet50,mobilenet,rnn2等均正常。
然后如果 export FLAGS_fraction_of_gpu_memory_to_use=0.01 或者 0.1, 预测过程是正常的。
使用C++ API预测时,export FLAGS_fraction_of_gpu_memory_to_use=0.0 也是正常预测。
export FLAGS_fraction_of_gpu_memory_to_use=0.0
python main.py# Inference Config
model_dir = "/Benchmark_paddle/python_infer_TRT/live1208/models"
prog_file = "{}/model".format(model_dir)
params_file = "{}/params".format(model_dir)
config = fluid.core.AnalysisConfig(prog_file, params_file)
config.enable_use_gpu(200, 0)
# config.enable_tensorrt_engine(1 << 20, 1,use_static=False, use_calib_mode=True, precision_mode=fluid.core.AnalysisConfig.Precision.Int8)
predict = fluid.core.create_paddle_predictor(config)
outputs = predict.run(input_slots)
results = outputs[0].data.float_data()- 问题描述:报错信息如下
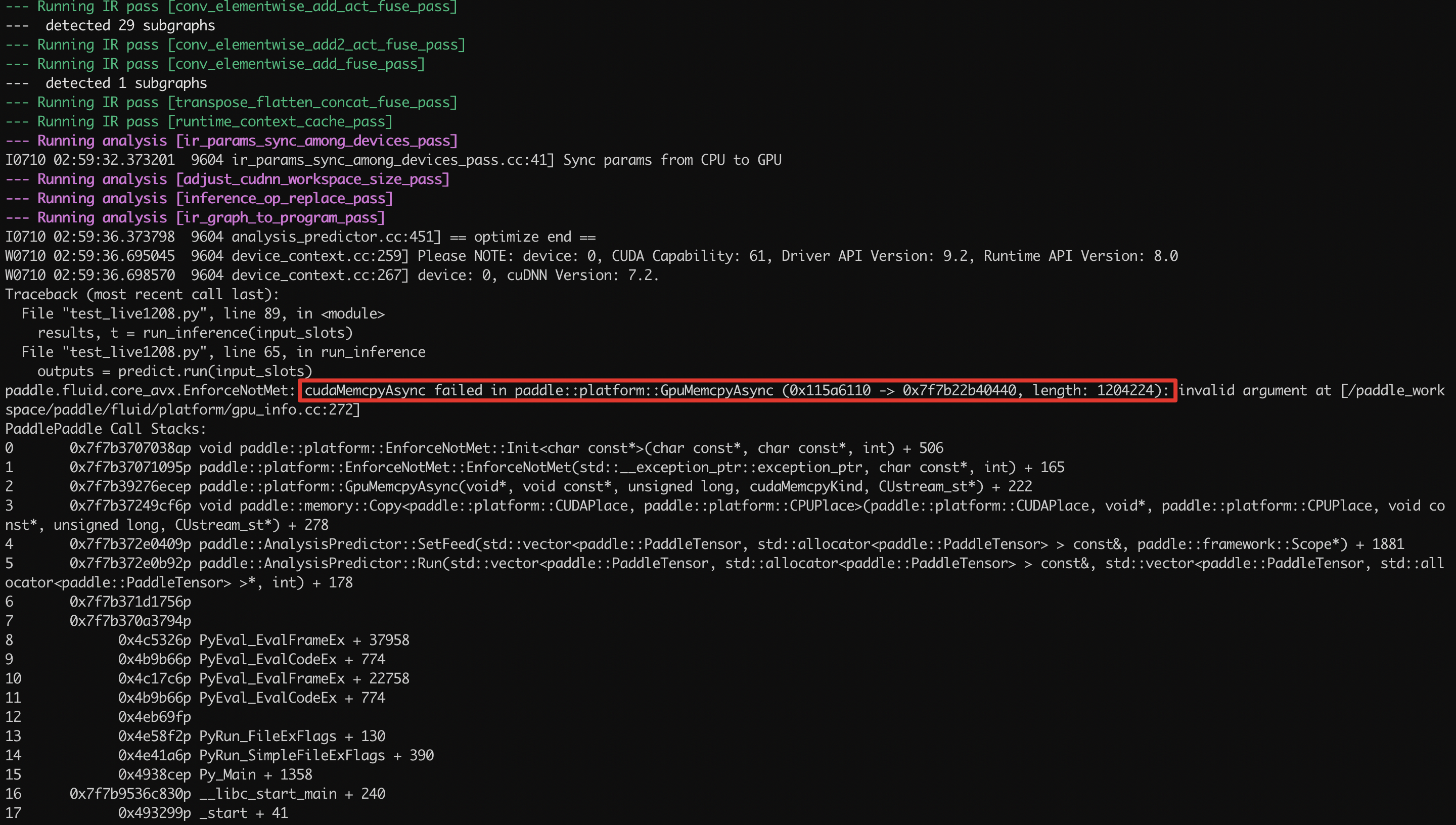
--- Running analysis [ir_graph_build_pass]
--- Running analysis [ir_analysis_pass]
--- Running IR pass [infer_clean_graph_pass]
--- Running IR pass [conv_affine_channel_fuse_pass]
--- Running IR pass [conv_eltwiseadd_affine_channel_fuse_pass]
--- Running IR pass [conv_bn_fuse_pass]
--- Running IR pass [conv_eltwiseadd_bn_fuse_pass]
--- detected 14 subgraphs
--- Running IR pass [conv_elementwise_add_act_fuse_pass]
--- detected 29 subgraphs
--- Running IR pass [conv_elementwise_add2_act_fuse_pass]
--- Running IR pass [conv_elementwise_add_fuse_pass]
--- detected 1 subgraphs
--- Running IR pass [transpose_flatten_concat_fuse_pass]
--- Running IR pass [runtime_context_cache_pass]
--- Running analysis [ir_params_sync_among_devices_pass]
I0710 02:59:32.373201 9604 ir_params_sync_among_devices_pass.cc:41] Sync params from CPU to GPU
--- Running analysis [adjust_cudnn_workspace_size_pass]
--- Running analysis [inference_op_replace_pass]
--- Running analysis [ir_graph_to_program_pass]
I0710 02:59:36.373798 9604 analysis_predictor.cc:451] == optimize end ==
W0710 02:59:36.695045 9604 device_context.cc:259] Please NOTE: device: 0, CUDA Capability: 61, Driver API Version: 9.2, Runtime API Version: 8.0
W0710 02:59:36.698570 9604 device_context.cc:267] device: 0, cuDNN Version: 7.2.
Traceback (most recent call last):
File "test_live1208.py", line 89, in <module>
results, t = run_inference(input_slots)
File "test_live1208.py", line 65, in run_inference
outputs = predict.run(input_slots)
paddle.fluid.core_avx.EnforceNotMet: cudaMemcpyAsync failed in paddle::platform::GpuMemcpyAsync (0x115a6110 -> 0x7f7b22b40440, length: 1204224): invalid argument at [/paddle_workspace/paddle/fluid/platform/gpu_info.cc:272]
PaddlePaddle Call Stacks:
0 0x7f7b3707038ap void paddle::platform::EnforceNotMet::Init<char const*>(char const*, char const*, int) + 506
1 0x7f7b37071095p paddle::platform::EnforceNotMet::EnforceNotMet(std::__exception_ptr::exception_ptr, char const*, int) + 165
2 0x7f7b39276ecep paddle::platform::GpuMemcpyAsync(void*, void const*, unsigned long, cudaMemcpyKind, CUstream_st*) + 222
3 0x7f7b37249cf6p void paddle::memory::Copy<paddle::platform::CUDAPlace, paddle::platform::CPUPlace>(paddle::platform::CUDAPlace, void*, paddle::platform::CPUPlace, void const*, unsigned long, CUstream_st*) + 278
4 0x7f7b372e0409p paddle::AnalysisPredictor::SetFeed(std::vector<paddle::PaddleTensor, std::allocator<paddle::PaddleTensor> > const&, paddle::framework::Scope*) + 1881
5 0x7f7b372e0b92p paddle::AnalysisPredictor::Run(std::vector<paddle::PaddleTensor, std::allocator<paddle::PaddleTensor> > const&, std::vector<paddle::PaddleTensor, std::allocator<paddle::PaddleTensor> >*, int) + 178
6 0x7f7b371d1756p
7 0x7f7b370a3794p
8 0x4c5326p PyEval_EvalFrameEx + 37958
9 0x4b9b66p PyEval_EvalCodeEx + 774
10 0x4c17c6p PyEval_EvalFrameEx + 22758
11 0x4b9b66p PyEval_EvalCodeEx + 774
12 0x4eb69fp
13 0x4e58f2p PyRun_FileExFlags + 130
14 0x4e41a6p PyRun_SimpleFileExFlags + 390
15 0x4938cep Py_Main + 1358
16 0x7f7b9536c830p __libc_start_main + 240
17 0x493299p _start + 41