使用fluid1.3 nce 训练skip-gram词向量效果不符合预期,完全不如tf训练出的效果
Created by: PengheLiu
paddle新手,这两天我用fluid1.3实现了一版skip-gram模型,用了一个小规模数据集做测试,对比了tf上的实现,发现效果差别很大,tf上的基本符合预期,而fluid的看起来没有收敛,不知道是否是我实现的问题,在训练过程中每一轮迭代loss也有变化,但感觉词向量并没有怎么更新,实在不知道是哪里出了问题,辛苦大佬帮分析下代码。
train.py
import sys
import os
import random
import math
import time
import argparse
import numpy as np
import six
import paddle
import paddle.fluid as fluid
import dataset
def parse_args():
parser = argparse.ArgumentParser("metapath2vec")
parser.add_argument(
'--train_dir', type=str, default='train_data', help='train file address')
parser.add_argument(
'--vocab_path', type=str, default='vocab.txt', help='vocab file address')
parser.add_argument(
'--is_local', type=int, default=1, help='whether local')
parser.add_argument(
'--model_dir', type=str, default='./output/model', help='model dir')
parser.add_argument(
'--batch_size', type=int, default=10, help='num of batch size')
parser.add_argument(
'--pass_num', type=int, default=1, help='num of epoch')
parser.add_argument(
'--use_cuda', type=int, default=0, help='whether use gpu')
parser.add_argument(
'--parallel', type=int, default=0, help='whether parallel')
parser.add_argument(
'--base_lr', type=float, default=0.001, help='learning rate')
parser.add_argument(
'--num_devices', type=int, default=1, help='Number of GPU devices')
parser.add_argument(
'--embed_size', type=int, default=16, help='embedding size')
parser.add_argument(
'--window_size', type=int, default=5, help='slip window size')
parser.add_argument(
'--num_neg_samples', type=int, default=5, help='Number of negtive samples')
args = parser.parse_args()
return args
def to_lodtensor(data, place):
""" convert to LODtensor """
seq_lens = [len(seq) for seq in data]
cur_len = 0
lod = [cur_len]
for l in seq_lens:
cur_len += l
lod.append(cur_len)
flattened_data = np.concatenate(data, axis=0).astype("int64")
flattened_data = flattened_data.reshape([len(flattened_data), 1])
res = fluid.LoDTensor()
res.set(flattened_data, place)
res.set_lod([lod])
return res
def train():
""" do training """
args = parse_args()
train_dir = args.train_dir
vocab_path = args.vocab_path
use_cuda = True if args.use_cuda else False
parallel = True if args.parallel else False
print("use_cuda: %s, parallel: %s" % (str(use_cuda), str(parallel)))
batch_size = args.batch_size
window_size = args.window_size
embed_size = args.embed_size
num_neg_samples = args.num_neg_samples
# step 0: load words and convert word to id
word_data_set = dataset.Dateset(vocab_path, window_size)
dict_size = len(word_data_set.nodeid2index)
print("define network")
# step 1: define the data for input and output
center_words = fluid.layers.data(
name="center_words", shape=[1], dtype='int64')
context_words = fluid.layers.data(
name="context_words", shape=[1], dtype='int64')
# step 2: define embedding
emb = fluid.layers.embedding(
input=center_words,
size=[dict_size, embed_size],
param_attr='emb.w',
is_sparse=True)
print("define loss")
# step 3: define loss
loss = fluid.layers.nce(input=emb,
label=context_words,
num_total_classes=dict_size,
param_attr='nce.w',
bias_attr='nce.b',
num_neg_samples=num_neg_samples,
sampler='custom_dist',
custom_dist=word_data_set.sampling_prob
)
avg_loss = fluid.layers.mean(loss)
print("define optimizer")
# step 4: define optimizer
sgd_optimizer = fluid.optimizer.SGDOptimizer(learning_rate=args.base_lr)
sgd_optimizer.minimize(avg_loss)
# step 5: initialize executor
# use cpu or gpu
place = fluid.CUDAPlace(0) if use_cuda else fluid.CPUPlace()
# use pserver for distributed leanning
training_role = os.getenv("TRAINING_ROLE", "TRAINER")
if training_role == "PSERVER":
place = fluid.CPUPlace()
exe = fluid.Executor(place)
# distributed learning or not
if parallel:
train_exe = fluid.ParallelExecutor(
use_cuda=use_cuda, loss_name=avg_loss.name)
else:
train_exe = exe
# step 6: run training with data
def train_loop(main_program):
""" train network """
pass_num = args.pass_num
model_dir = args.model_dir
fetch_list = [avg_loss.name]
exe.run(fluid.default_startup_program())
total_time = 0.0
for pass_idx in six.moves.xrange(pass_num):
epoch_idx = pass_idx + 1
print("epoch_%d start" % epoch_idx)
t0 = time.time()
i = 0
train_reader = paddle.batch(
paddle.reader.shuffle(
word_data_set.reader_creator(train_dir), buf_size = 1000),
batch_size = batch_size)
for data in train_reader():
i += 1
feed_center_words = to_lodtensor([[dat[0]] for dat in data], place)
feed_context_words = to_lodtensor([[dat[1]] for dat in data], place)
ret_avg_loss = train_exe.run(main_program,
feed={ "center_words": feed_center_words,
"context_words": feed_context_words
}, fetch_list=fetch_list)
#if i % batch_size == 0:
# print("step:%d avg_loss:%.4f" % (i, ret_avg_loss[0]))
t1 = time.time()
total_time += t1 - t0
print("epoch:%d num_steps:%d time_cost(s):%f avg_loss:%.4f" % (epoch_idx, i, total_time / epoch_idx, ret_avg_loss[0]))
save_dir = "%s/epoch_%d" % (model_dir, epoch_idx)
feed_var_names = ["center_words", "context_words"]
fetch_vars = [avg_loss]
fluid.io.save_inference_model(save_dir, feed_var_names, fetch_vars, exe)
print("model saved in %s" % save_dir)
word_embs = np.array(fluid.global_scope().find_var("emb.w").get_tensor())
word_embs = ["\t".join([word_data_set.index2nodeid[idx]] + map(str, emb)) for idx, emb in enumerate(word_embs)]
with open(save_dir + "/word_vec.txt", "w") as fw:
fw.write("\n".join(word_embs))
print("finish tranining")
if args.is_local:
print("run local trainning")
train_loop(fluid.default_main_program())
else:
print("run distribute tranining")
port = os.getenv("PADDLE_PORT", "6174")
pserver_ips = os.getenv("PADDLE_PSERVERS") # ip,ip...
eplist = []
for ip in pserver_ips.split(","):
eplist.append(':'.join([ip, port]))
pserver_endpoints = ",".join(eplist) # ip:port,ip:port...
trainers = int(os.getenv("PADDLE_TRAINERS_NUM", "0"))
current_endpoint = os.getenv("POD_IP") + ":" + port
trainer_id = int(os.getenv("PADDLE_TRAINER_ID", "0"))
t = fluid.DistributeTranspiler()
t.transpile(trainer_id, pservers=pserver_endpoints, trainers=trainers)
if training_role == "PSERVER":
pserver_prog = t.get_pserver_program(current_endpoint)
pserver_startup = t.get_startup_program(current_endpoint,
pserver_prog)
exe.run(pserver_startup)
exe.run(pserver_prog)
elif training_role == "TRAINER":
train_loop(t.get_trainer_program())
if __name__ == '__main__':
print("skip-gram word2vec in paddle")
train()dataset.py主要是统计词频,计算采样概率的以及构建batch_reader用的,这里先不贴代码了,和tf训练时用的基本一致。
然后训练的时候,输出的loss一直这样波动
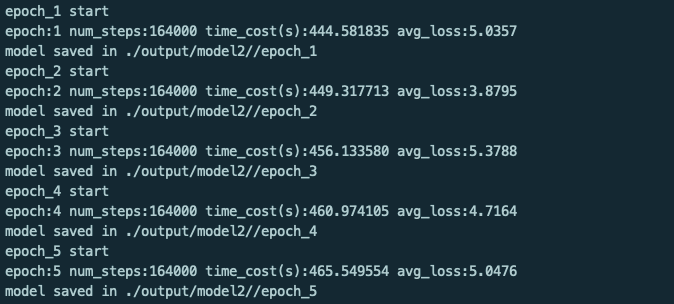
最后学出来的向量感觉还是随机生成的,与tf相比效果很差,使用的都是一样的参数配置。
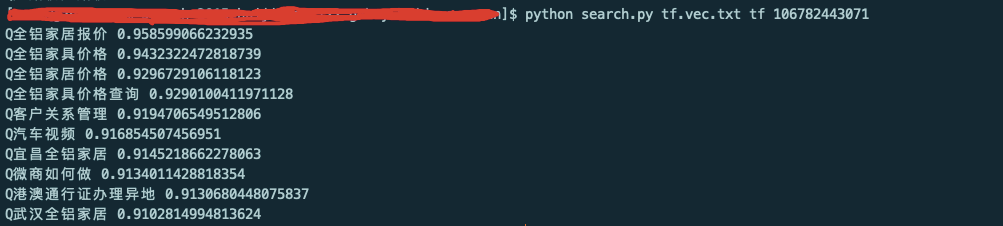
这是我应用的一个效果,这个userid是做铝制品家具的,想看这个客户的top10相关的query,paddle的效果:

tf的效果: