transformer里data层的疑问
Created by: shiyazhou121
tranformer的fluid实现是参考https://github.com/PaddlePaddle/models/tree/develop/fluid/PaddleNLP/neural_machine_translation/transformer
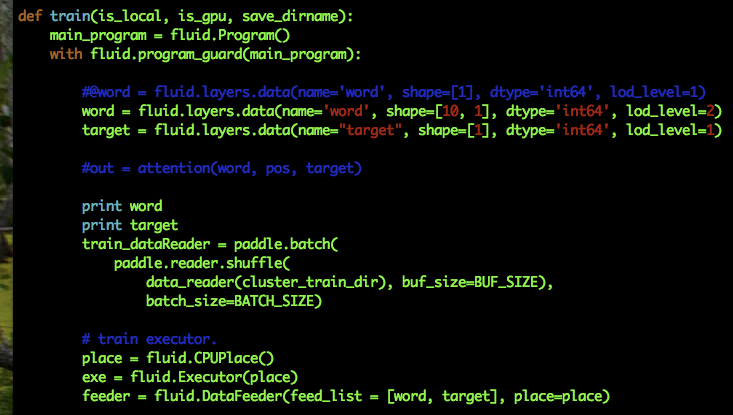
其中src_word数据层定义是"src_word": [(batch_size, seq_len, 1), "int64", 2], 对应的是data的shape, dtype, lod_level。
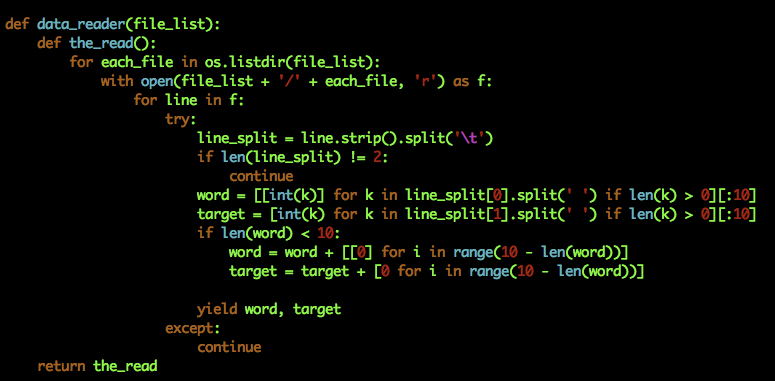
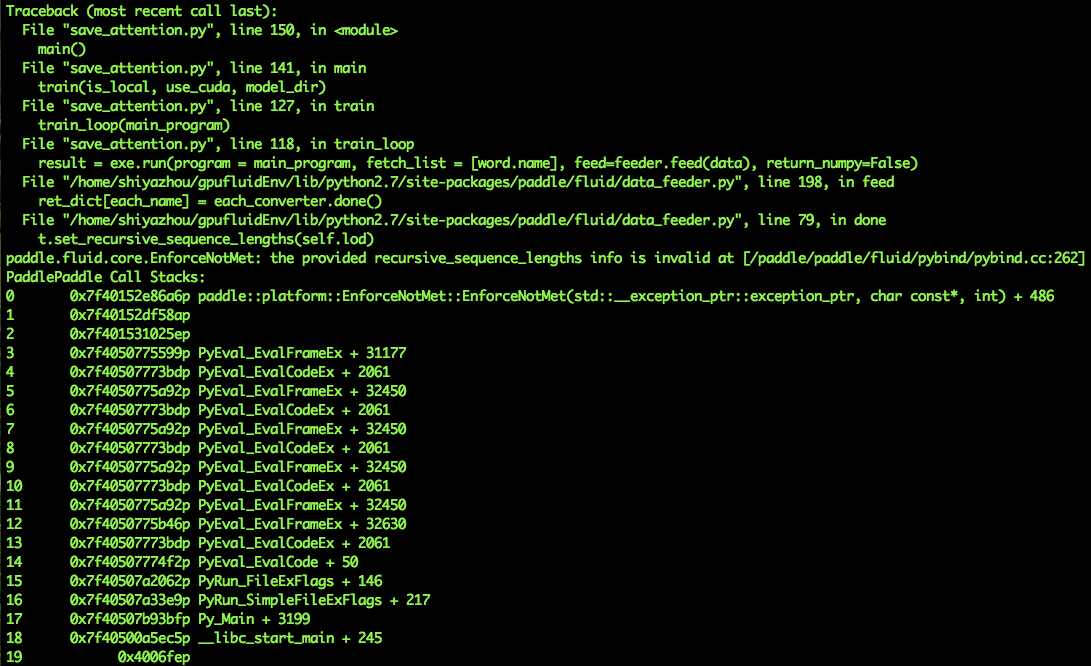
以上是tranformer的实现,我在用到自己模型中时,参考上边的配置,结果报错了。 我的数据是将一个句子转变成的序列vector,比如 [[1], [2], [3], [5]] 另外有个疑惑,既然已经做了padding,可以当定长处理,为什么tranformer里用的lod_level = 2.