grad_op_maker_ should not be null and GradOpMaker has not been registered??
Created by: ManWingloeng
with fluid.program_guard(d_program):
# declare_data(self)
self.inputs = fluid.layers.data(shape=image_dims, name='real_images')
self.y = fluid.layers.data(shape=[self.y_dim], name='y')
self.z = fluid.layers.data(shape=[self.z_dim], name='z')
self.unlabelled_inputs = fluid.layers.data(shape=image_dims, name='unlabelled_images')
print(self.inputs)
D_real, D_real_logits, _ = self.D(self.inputs, self.y, is_test=False)
G_train = self.G(self.z, self.y, is_test=False)
print(G_train)
D_fake, D_fake_logits, _ = self.D(G_train, self.y, is_test=False, reuse=True)
Y_c, _ = self.C(self.unlabelled_inputs, is_test=False)
D_cla, D_cla_logits, _ = self.D(self.unlabelled_inputs, Y_c, is_test=False, reuse=True)
ones_real = ones(D_real.shape)
zeros_fake = zeros(D_fake.shape)
zeros_cla = zeros(D_cla.shape)
ce_real = fluid.layers.sigmoid_cross_entropy_with_logits(x=D_real_logits, label=ones_real)
ce_fake = fluid.layers.sigmoid_cross_entropy_with_logits(x=D_fake_logits, label=zeros_fake)
ce_cla = fluid.layers.sigmoid_cross_entropy_with_logits(x=D_cla_logits, label=zeros_cla)
d_loss_real = fluid.layers.reduce_mean(ce_real)
d_loss_fake = (1 - alpha) * fluid.layers.reduce_mean(ce_fake)
d_loss_cla = alpha * fluid.layers.reduce_mean(ce_cla)
self.d_loss = d_loss_real + d_loss_fake + d_loss_cla
d_parameters = self.get_params(d_program, prefix='D')
d_opt = fluid.optimizer.Adam(learning_rate=self.gan_lr, beta1=self.GAN_beta1)
d_opt.minimize(self.d_loss, parameter_list=d_parameters)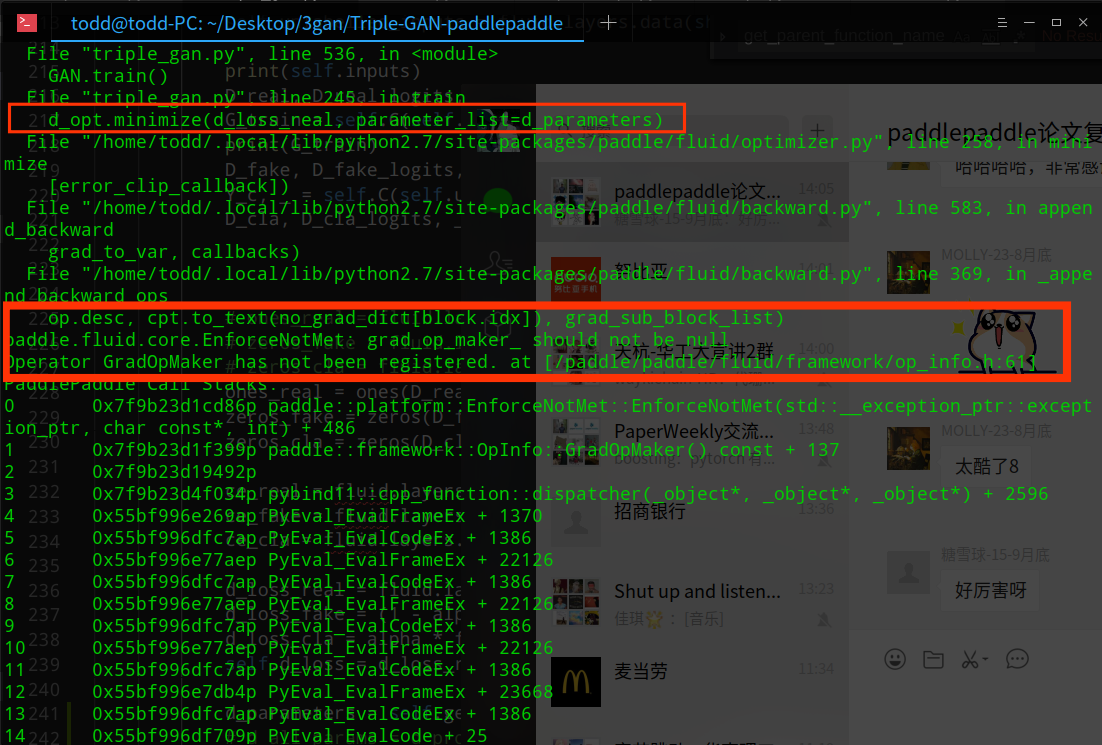
ones and zeros is written as :
def ones(shape, dtype='float32'):
return fluid.layers.ones(shape, dtype)
def zeros(shape, dtype='float32'):
return fluid.layers.zeros(shape, dtype)and the get_params functions is:
def get_params(self, program, prefix):
all_params = program.global_block().all_parameters()
return [t.name for t in all_params if t.name.startswith(prefix)]Anyone has point on this problem?