- 28 6月, 2022 1 次提交
-
-
由 Ming-Xu Huang 提交于
1. test_parallel_executor_seresnext_base_gpu failed on 2 P100 GPUs with `470.82` driver. ``` ====================================================================== FAIL: test_seresnext_with_learning_rate_decay (test_parallel_executor_seresnext_base_gpu.TestResnetGPU) ---------------------------------------------------------------------- Traceback (most recent call last): File "/opt/paddle/paddle/build/python/paddle/fluid/tests/unittests/test_parallel_executor_seresnext_base_gpu.py", line 32, in test_seresnext_with_learning_rate_decay self._compare_result_with_origin_model( File "/opt/paddle/paddle/build/python/paddle/fluid/tests/unittests/seresnext_test_base.py", line 56, in _compare_result_with_origin_model self.assertAlmostEquals( AssertionError: 6.8825445 != 6.882531 within 1e-05 delta (1.335144e-05 difference) ---------------------------------------------------------------------- ``` 2. To be more accuracte on evaluating loss convergence, we proposed to apply IOU as metric, instead of comparing first and last loss values. 3. As offline discussion, we also evaluated convergence on P100 and A100 in 1000 interations to make sure this UT have the same convergence property on both devices. The curves are showed below. 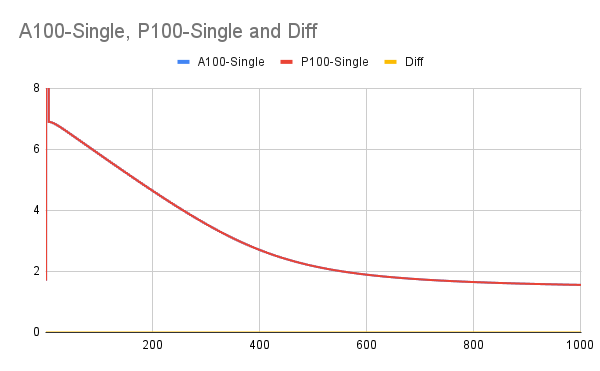
-
- 05 6月, 2022 1 次提交
-
-
由 Sing_chan 提交于
* use yapf to format all python file * yapf exclude two unittests file for they rely on writing and reading file, and format will break them * disable diff_py_file because too many diff files cause command following failed
-
- 12 5月, 2022 1 次提交
-
-
由 Shuangchi He 提交于
-
- 29 12月, 2020 1 次提交
-
-
由 liuyuhui 提交于
-
- 26 12月, 2020 1 次提交
-
-
由 liuyuhui 提交于
-
- 01 6月, 2020 1 次提交
-
-
由 Huihuang Zheng 提交于
The PR: https://github.com/PaddlePaddle/Paddle/pull/24651 seems causes new random failure of unit test test_parallel_executor_seresnext_base_cpu. The reason is that smaller batch size causes random optimization of neural network. I distinguished cpu/gpu batch size to fix the unittest.
-
- 22 8月, 2019 1 次提交
-
-
由 chengduo 提交于
* increase test_parallel_executor_seresnext time limit test=develop * split test_parallel_executor_seresnext test=develop * temporally disable reduce_and_allreduce test because of the random failure. test=develop * split gpu and cpu test=develop
-