Merge branch 'develop' into core_inference_multi_thread
Showing
benchmark/fluid/mnist.py
0 → 100644
benchmark/fluid/resnet.py
0 → 100644
benchmark/fluid/run.sh
0 → 100644
benchmark/fluid/vgg.py
0 → 100644
cmake/external/threadpool.cmake
0 → 100644
cmake/hip.cmake
0 → 100644
{kind=link}

175.1 KB
doc/design/parallel_executor.md
0 → 100644
doc/fluid/CMakeLists.txt
0 → 100644
doc/fluid/api/CMakeLists.txt
0 → 100644
{kind=link}
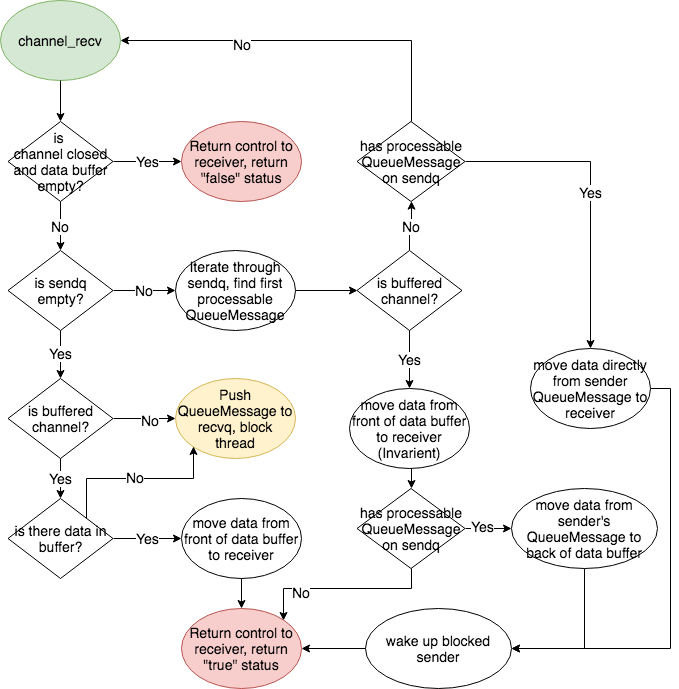
133.4 KB
{kind=link}
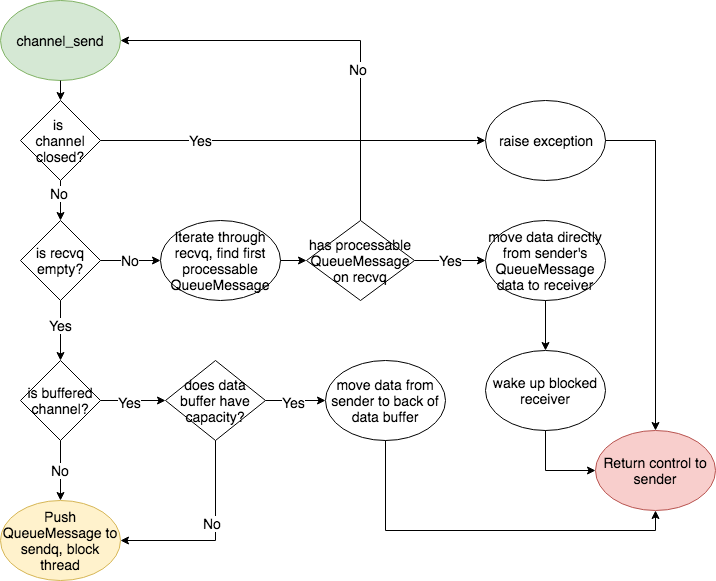
83.6 KB
doc/fluid/design/index_cn.rst
0 → 100644
doc/fluid/design/index_en.rst
0 → 100644
doc/fluid/dev/api_doc_std_en.md
0 → 100644
doc/fluid/dev/index_cn.rst
0 → 100644
doc/fluid/dev/index_en.rst
0 → 100644
doc/fluid/faq/index_cn.rst
0 → 100644
此差异已折叠。
doc/fluid/faq/index_en.rst
0 → 100644
此差异已折叠。
此差异已折叠。
此差异已折叠。
doc/fluid/getstarted/index_cn.rst
0 → 100644
此差异已折叠。
doc/fluid/getstarted/index_en.rst
0 → 100644
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
doc/fluid/howto/index_cn.rst
0 → 100644
此差异已折叠。
doc/fluid/howto/index_en.rst
0 → 100644
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
doc/fluid/index_cn.rst
0 → 100644
此差异已折叠。
doc/fluid/index_en.rst
0 → 100644
此差异已折叠。
此差异已折叠。
文件已移动
文件已移动
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
paddle/scripts/docker/build.sh
100644 → 100755
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
python/paddle/batch.py
0 → 100644
此差异已折叠。
python/paddle/dataset/__init__.py
0 → 100644
此差异已折叠。
python/paddle/dataset/cifar.py
0 → 100644
此差异已折叠。
python/paddle/dataset/common.py
0 → 100644
此差异已折叠。
python/paddle/dataset/conll05.py
0 → 100644
此差异已折叠。
python/paddle/dataset/flowers.py
0 → 100644
此差异已折叠。
python/paddle/dataset/image.py
0 → 100644
此差异已折叠。
python/paddle/dataset/imdb.py
0 → 100644
此差异已折叠。
python/paddle/dataset/imikolov.py
0 → 100644
此差异已折叠。
python/paddle/dataset/mnist.py
0 → 100644
此差异已折叠。
此差异已折叠。
python/paddle/dataset/mq2007.py
0 → 100644
此差异已折叠。
此差异已折叠。
此差异已折叠。
{kind=link}
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
python/paddle/dataset/voc2012.py
0 → 100644
此差异已折叠。
python/paddle/dataset/wmt14.py
0 → 100644
此差异已折叠。
python/paddle/dataset/wmt16.py
0 → 100644
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
文件模式从 100755 更改为 100644
此差异已折叠。
此差异已折叠。
文件模式从 100755 更改为 100644
此差异已折叠。
python/paddle/reader/__init__.py
0 → 100644
此差异已折叠。
python/paddle/reader/creator.py
0 → 100644
此差异已折叠。
python/paddle/reader/decorator.py
0 → 100644
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。