Merge branch 'develop' of https://github.com/PaddlePaddle/Paddle into transpiler_split_tensor
Showing
adversarial/README.md
0 → 100644
adversarial/advbox/__init__.py
0 → 100644
adversarial/advbox/models/base.py
0 → 100644
adversarial/fluid_mnist.py
0 → 100644
benchmark/cluster/README.md
0 → 100644
{kind=link}
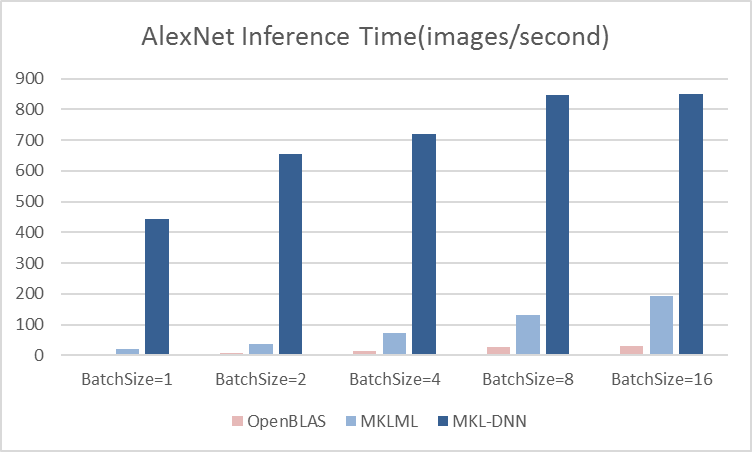
15.1 KB
{kind=link}
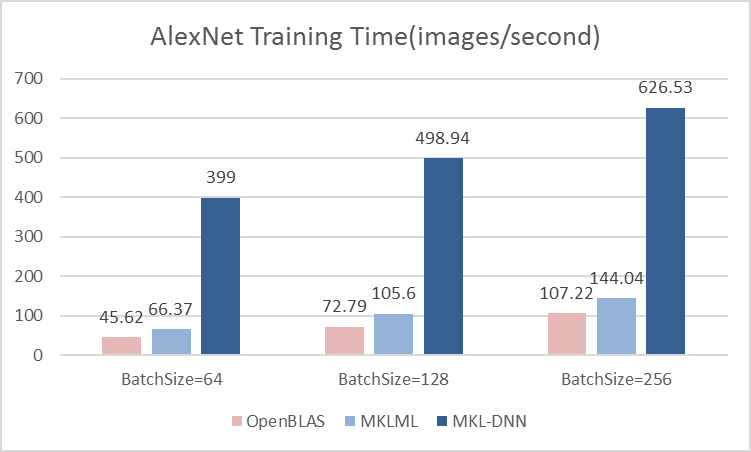
15.6 KB
{kind=link}
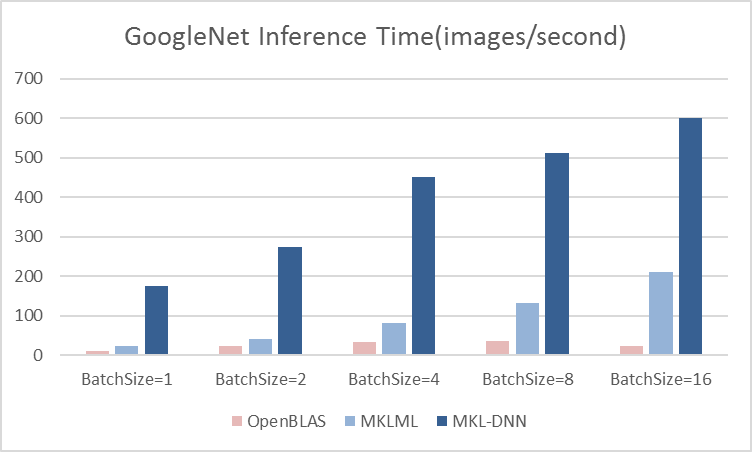
14.1 KB
{kind=link}
{kind=link}
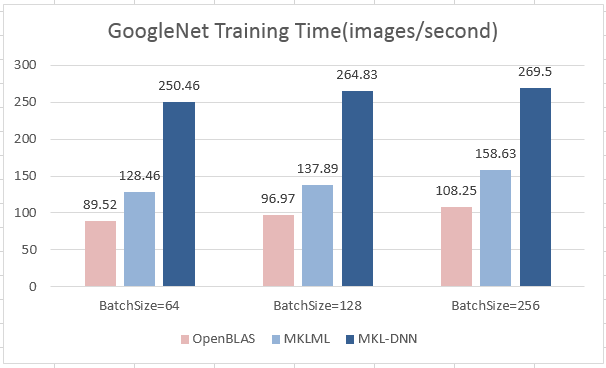
| W: | H:
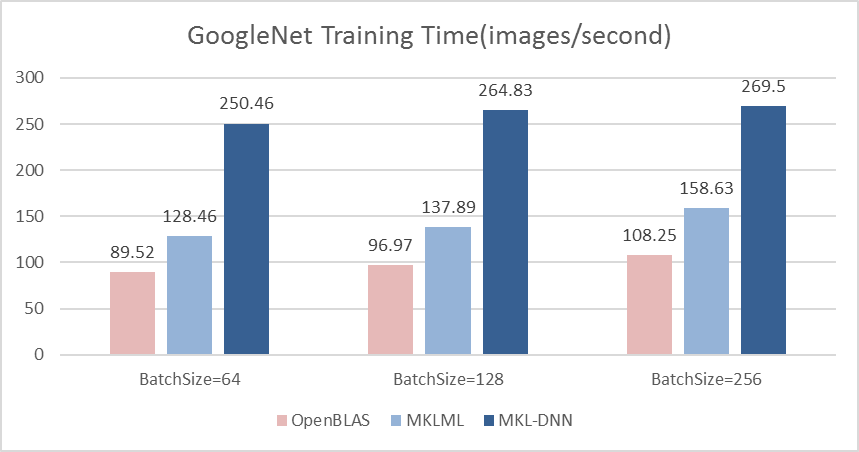
| W: | H:
{kind=link}
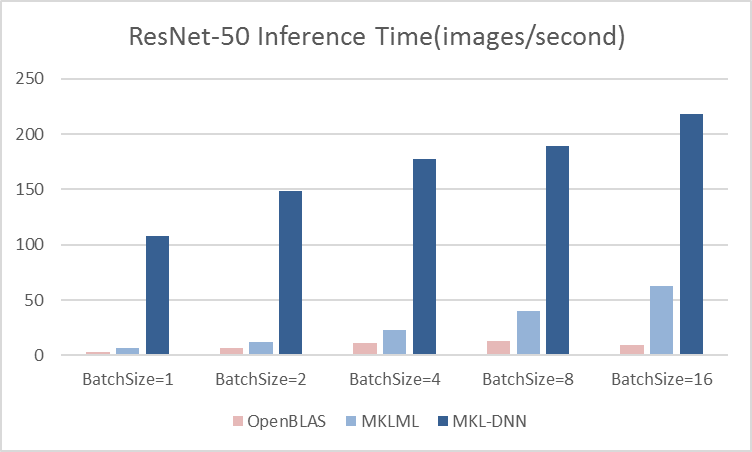
13.7 KB
{kind=link}
{kind=link}
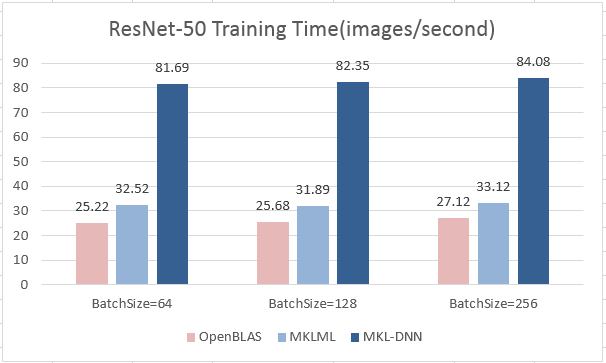
| W: | H:
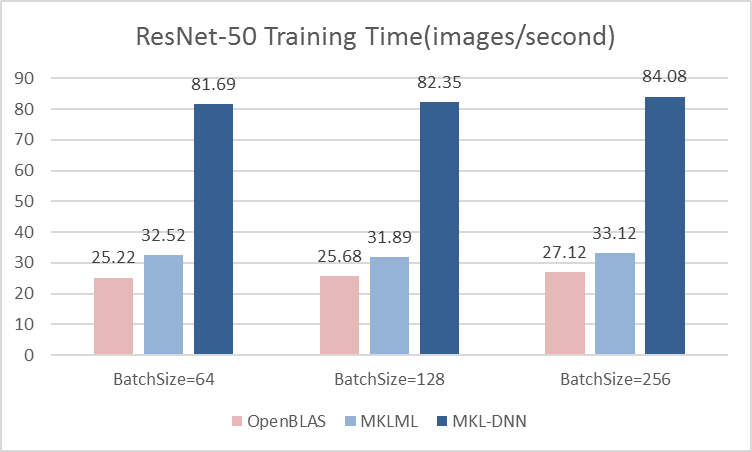
| W: | H:
benchmark/figs/vgg-cpu-infer.png
0 → 100644
{kind=link}
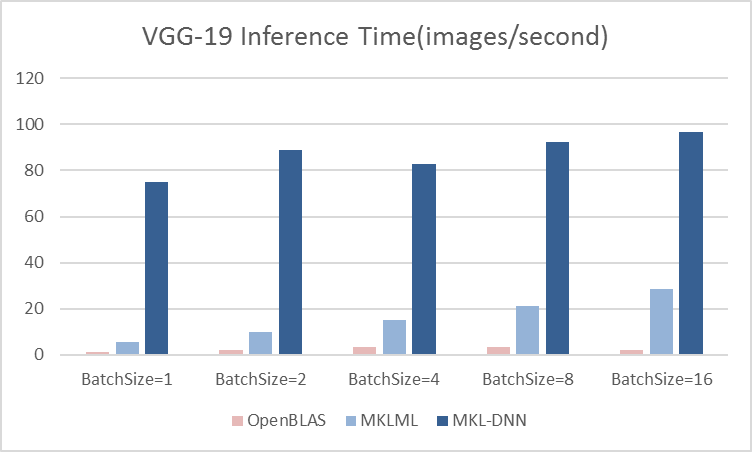
13.7 KB
{kind=link}
{kind=link}
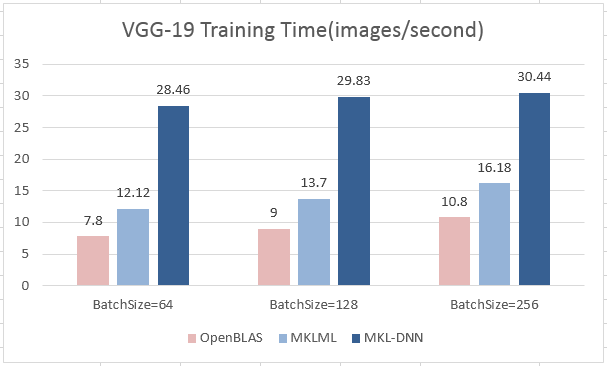
| W: | H:
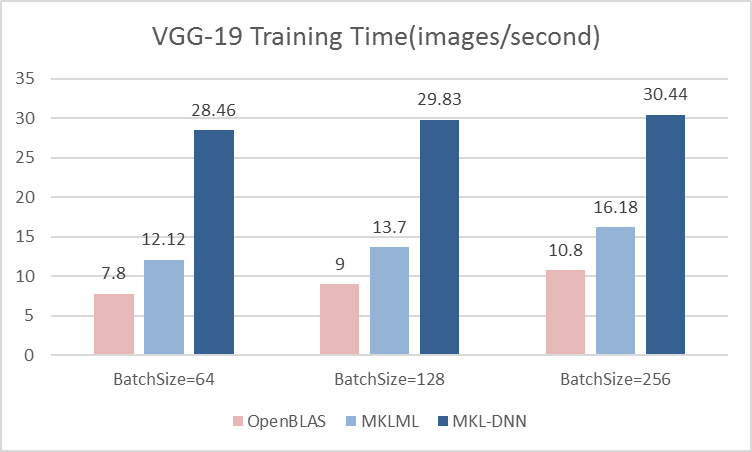
| W: | H:
benchmark/paddle/image/plotlog.py
0 → 100644
doc/api/v2/fluid/io.rst
0 → 100644
doc/design/ci_build_whl.png
0 → 100644
{kind=link}
280.4 KB
文件已移动
{kind=link}
文件已移动
文件已移动
{kind=link}
文件已移动
{kind=link}
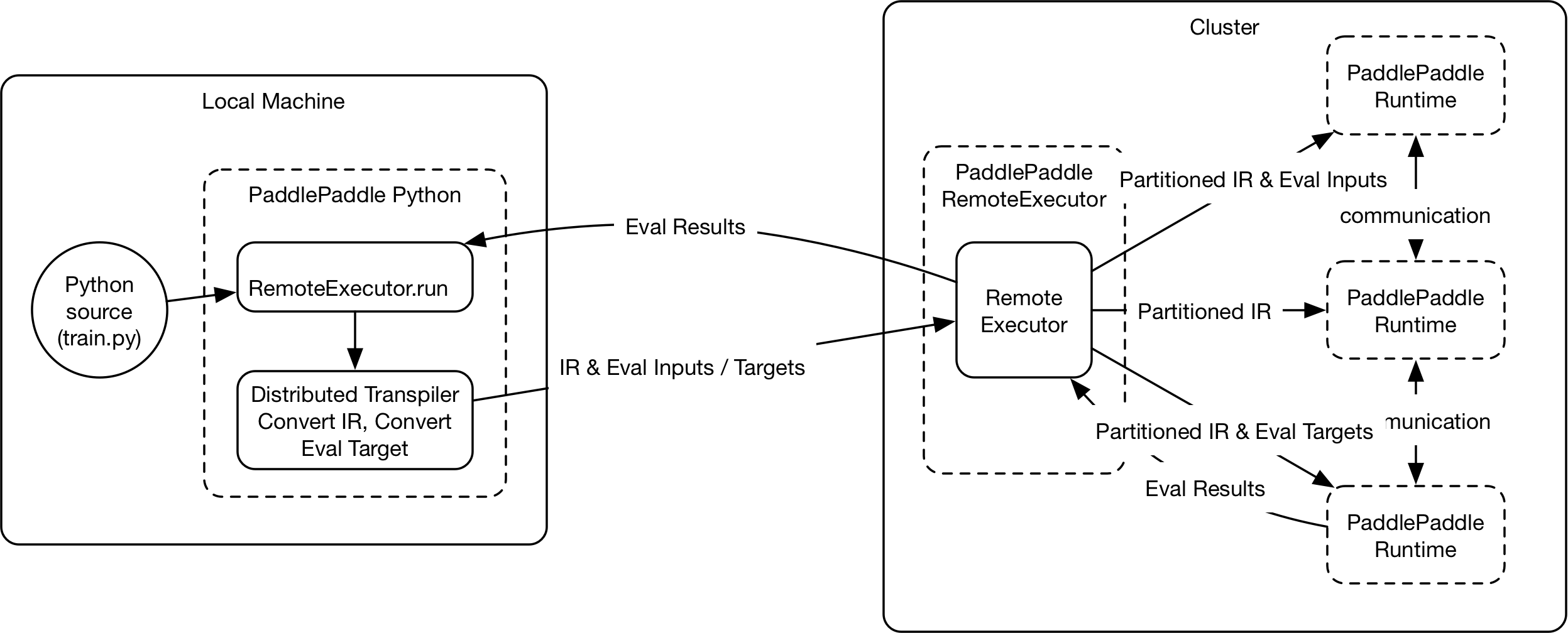
189.2 KB
文件已移动
{kind=link}
文件已移动
文件已添加
{kind=link}
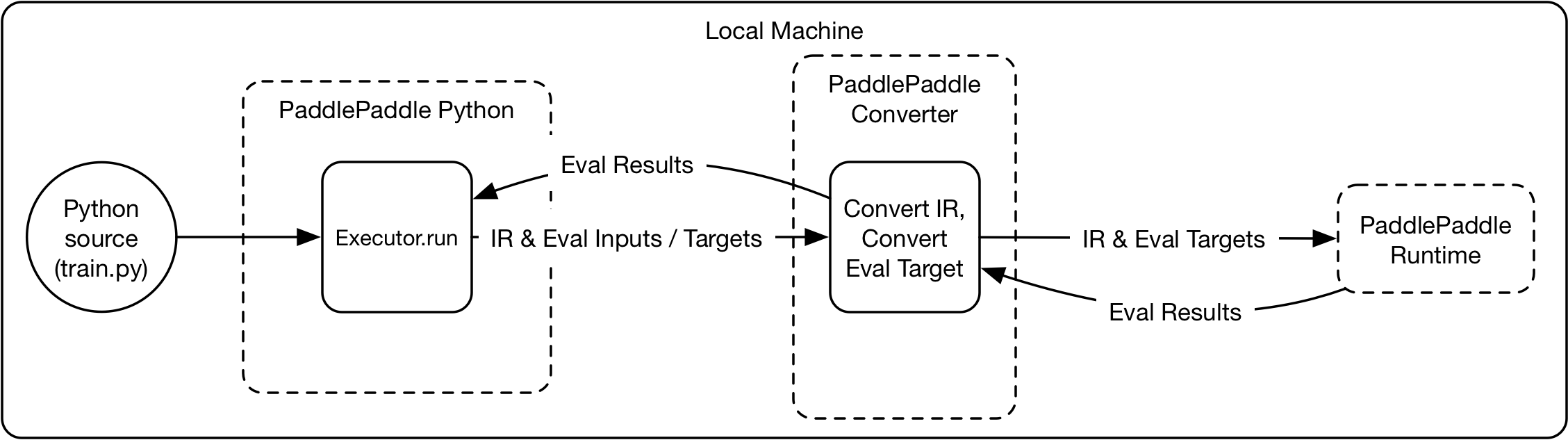
102.5 KB
文件已移动
{kind=link}
文件已移动
{kind=link}
文件已移动
文件已移动
{kind=link}
文件已移动
文件已添加
{kind=link}
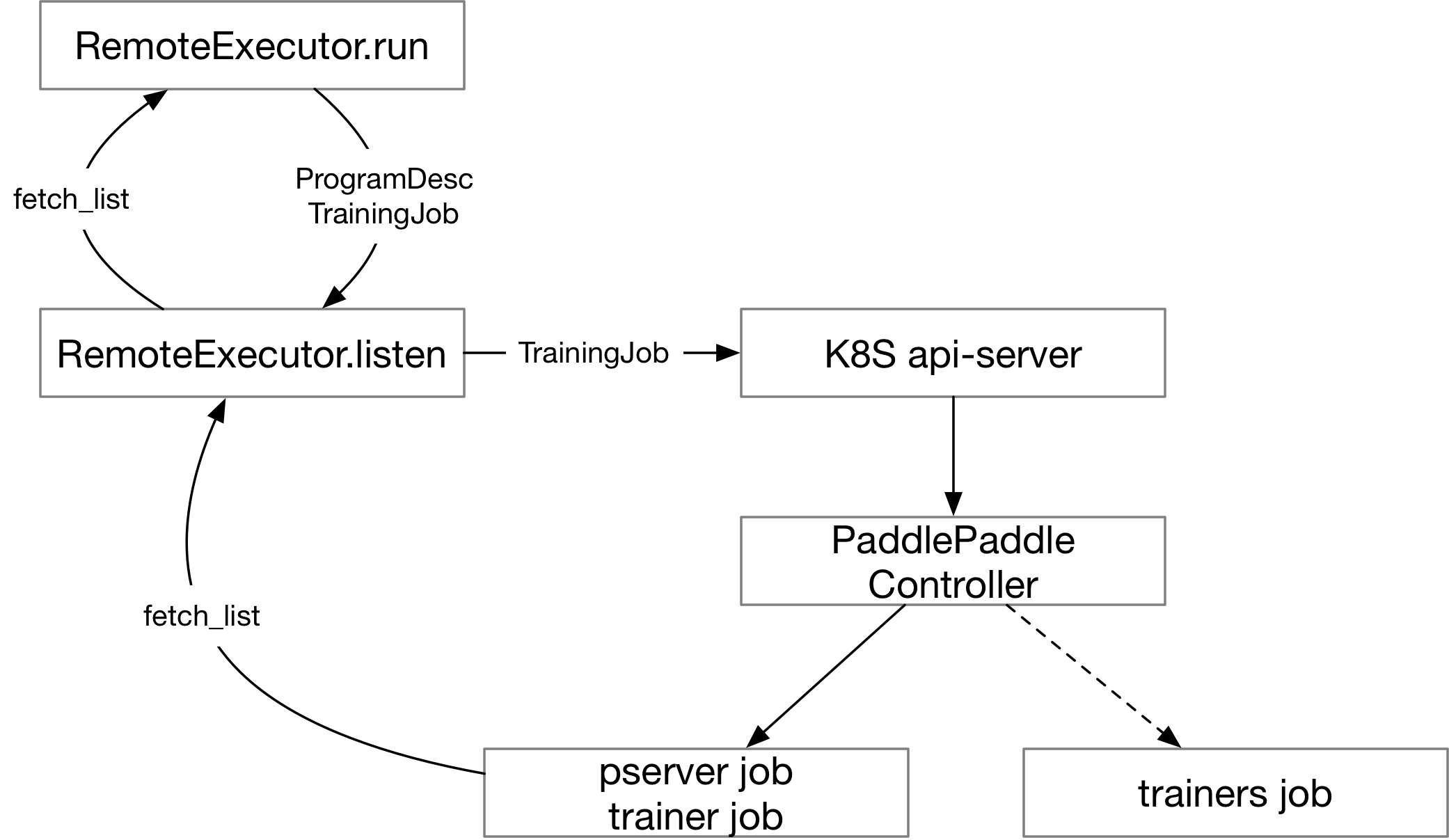
134.5 KB
doc/design/error_clip.md
0 → 100644
{kind=link}
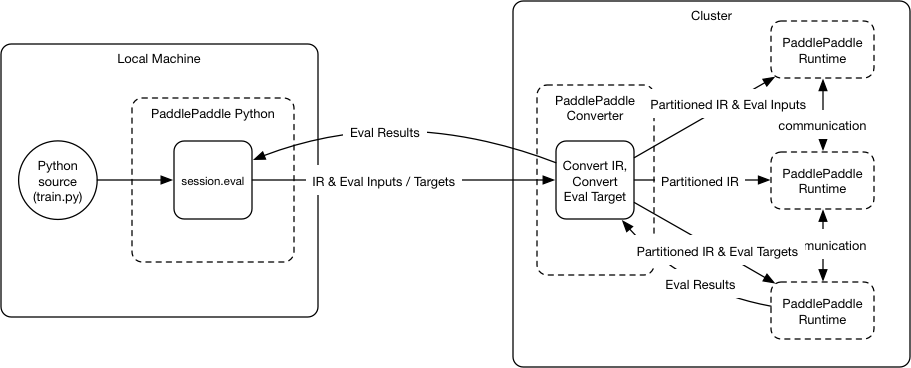
46.5 KB
文件已删除
{kind=link}
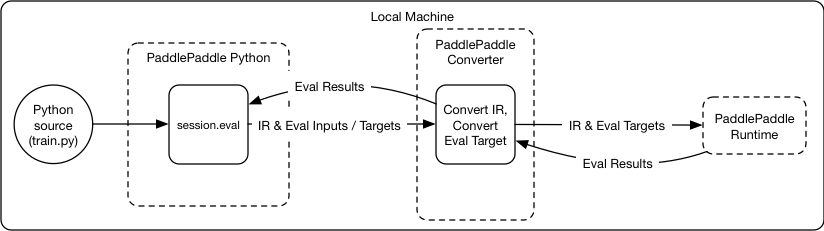
28.3 KB
{kind=link}
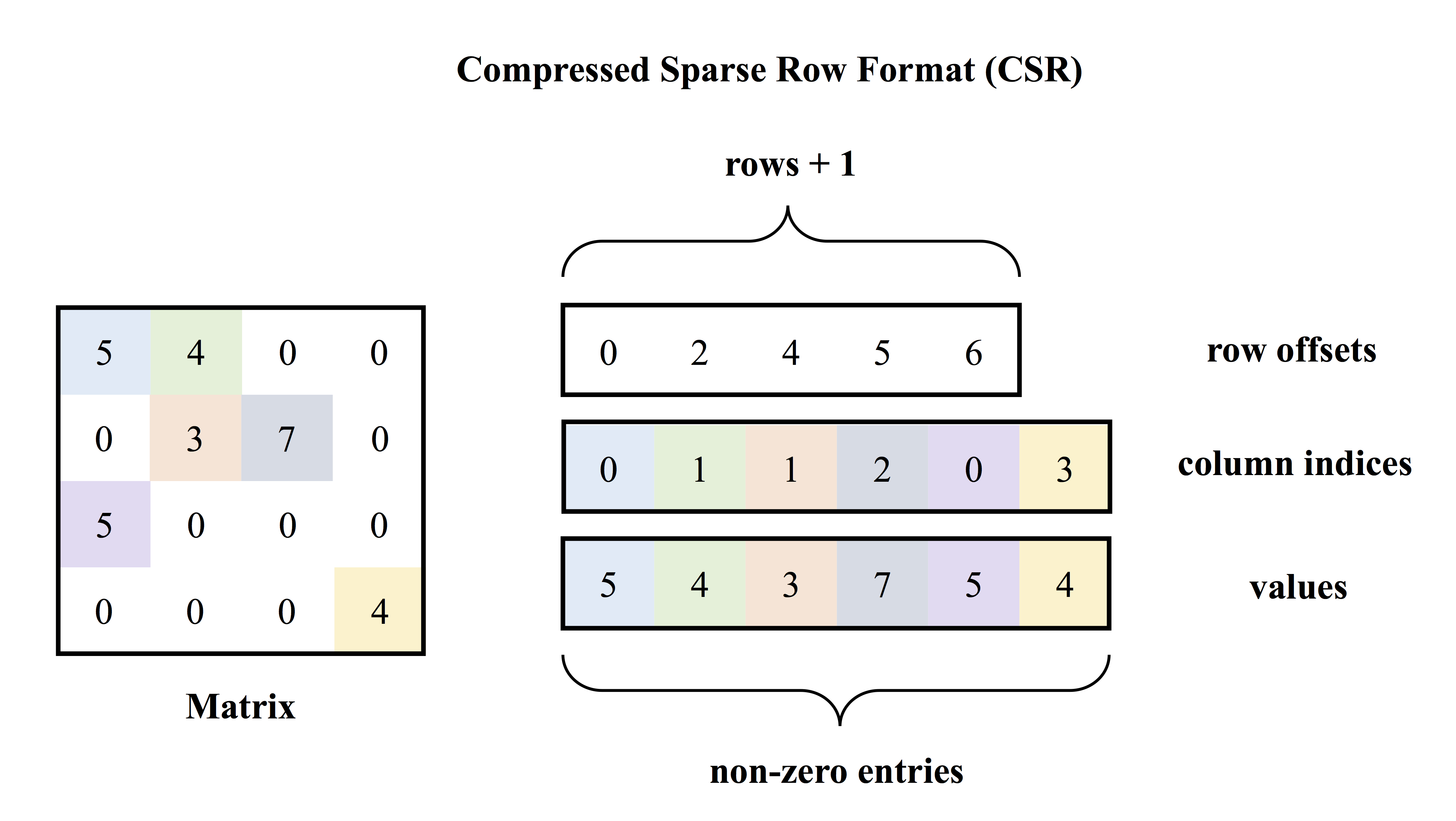
361.4 KB
{kind=link}
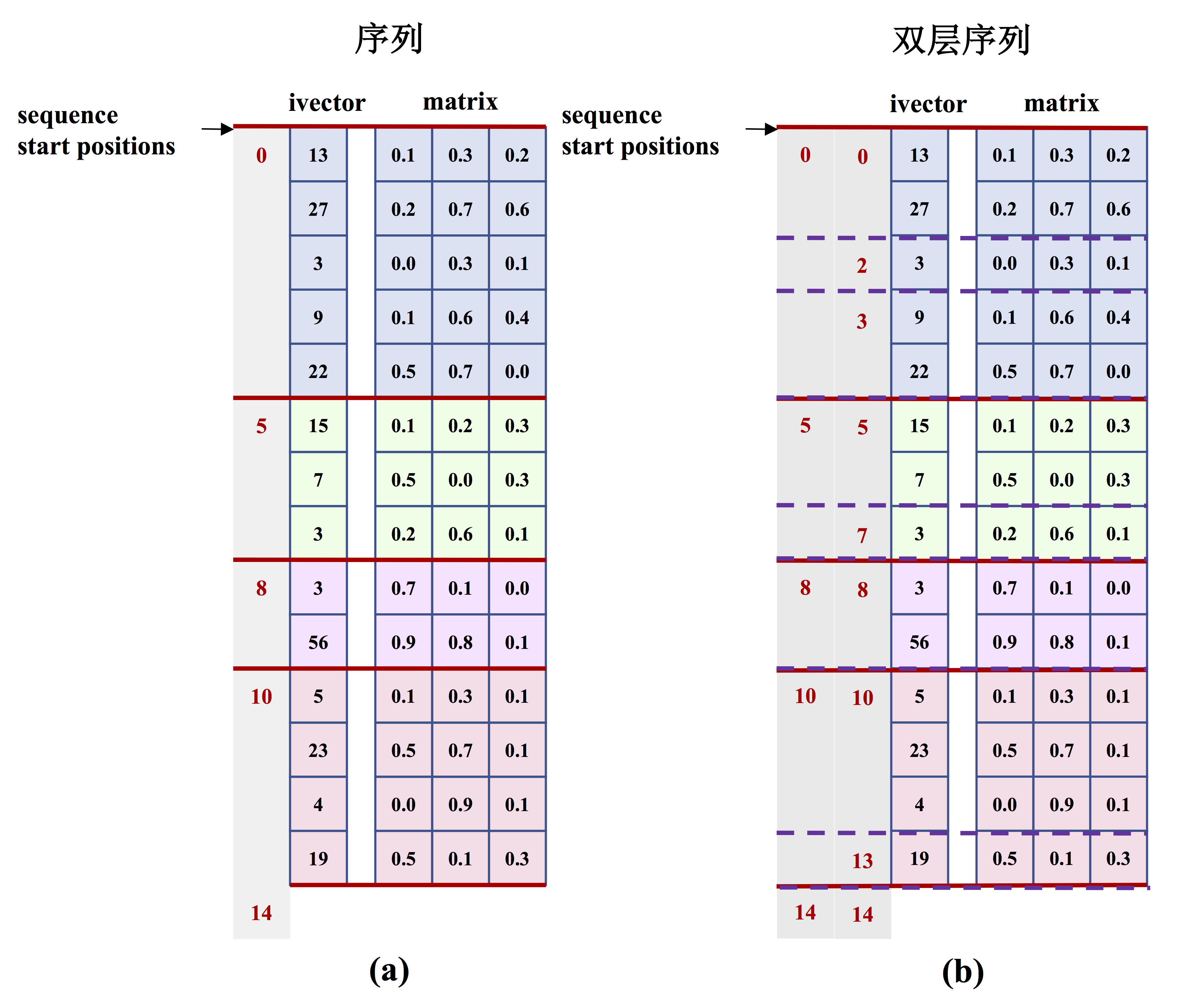
470.2 KB
{kind=link}
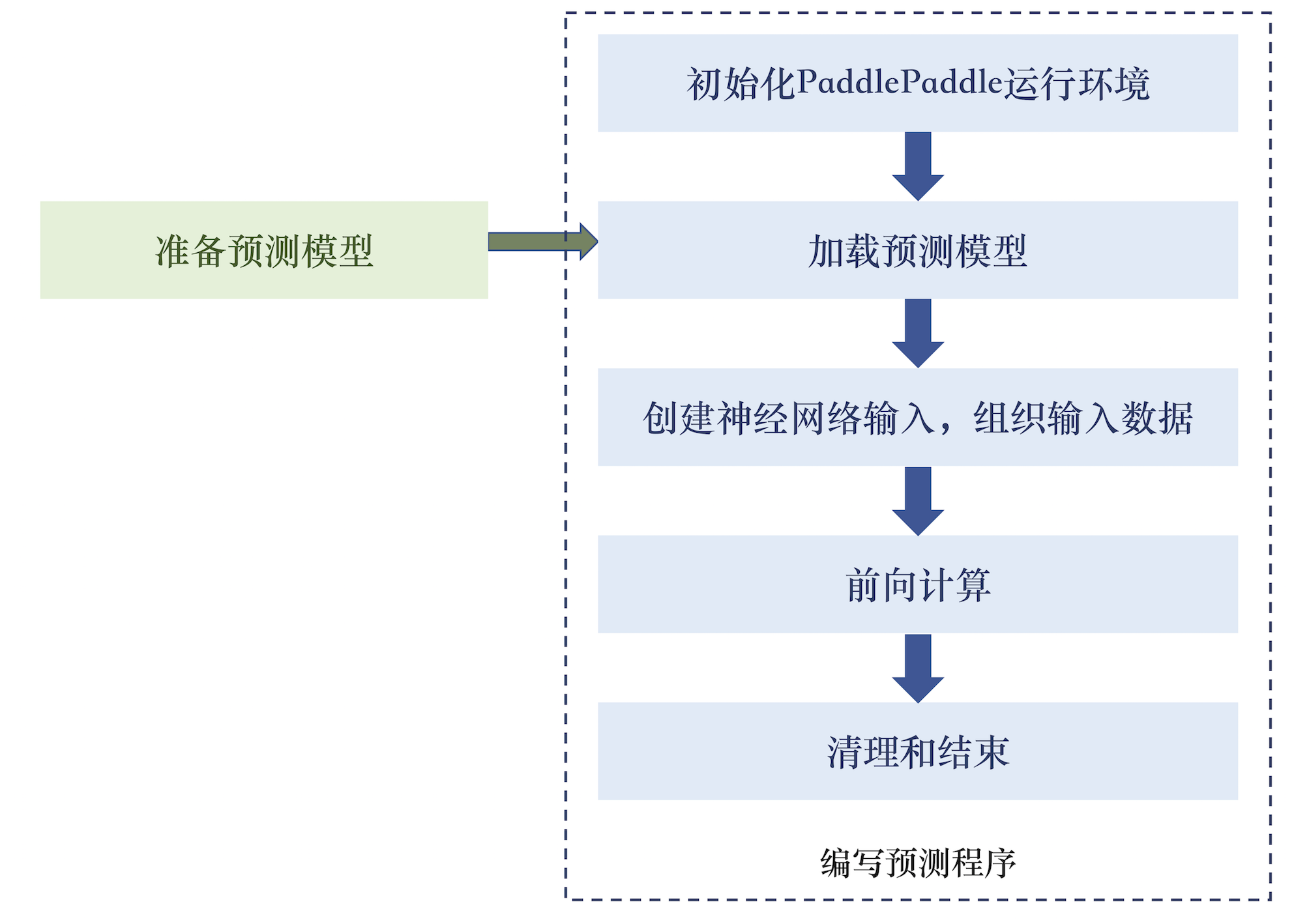
447.8 KB
doc/howto/usage/capi/index_cn.rst
0 → 100644
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
paddle/operators/get_places_op.cc
0 → 100644
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
paddle/operators/print_op.cc
0 → 100644
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
paddle/operators/tensor.save
已删除
100644 → 0
此差异已折叠。
paddle/operators/warpctc_op.cc
0 → 100644
此差异已折叠。
paddle/operators/warpctc_op.cu.cc
0 → 100644
此差异已折叠。
paddle/operators/warpctc_op.h
0 → 100644
此差异已折叠。
此差异已折叠。
paddle/platform/dynload/warpctc.h
0 → 100644
此差异已折叠。
paddle/platform/mkldnn_helper.h
0 → 100644
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
tools/manylinux1/Dockerfile.x64
0 → 100644
此差异已折叠。
tools/manylinux1/README.md
0 → 100644
此差异已折叠。
tools/manylinux1/build_all.sh
0 → 100755
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。