Merge pull request #11358 from panyx0718/new_master
Merge release 0.12.0 and 0.13.0 to master
Showing
.copyright.hook
0 → 100644
CODE_OF_CONDUCT.md
0 → 100644
CODE_OF_CONDUCT_cn.md
0 → 100644
{kind=link}
15.1 KB
{kind=link}
15.6 KB
{kind=link}
14.1 KB
{kind=link}
{kind=link}
| W: | H:
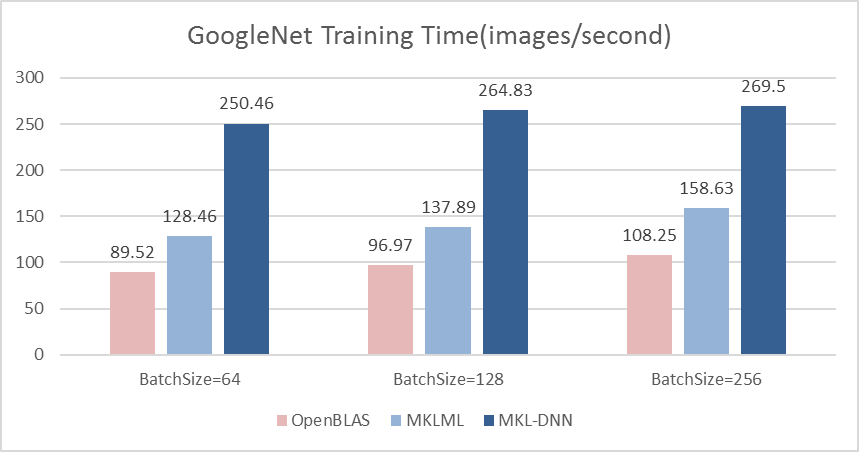
| W: | H:
{kind=link}
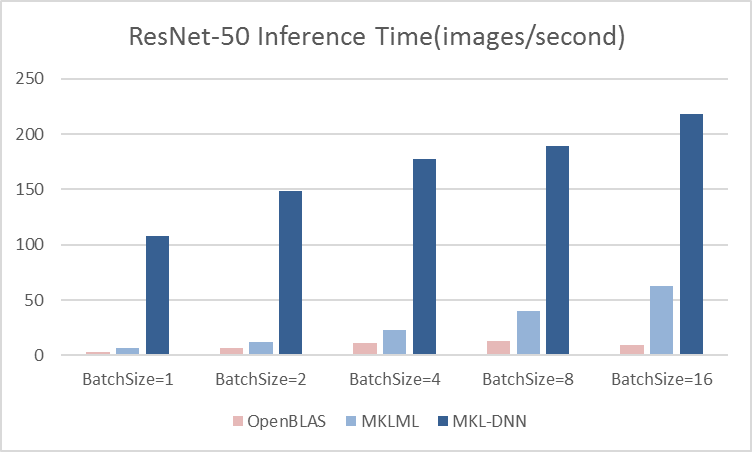
13.7 KB
{kind=link}
{kind=link}
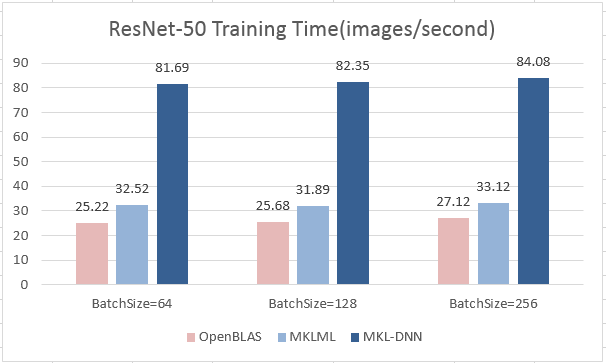
| W: | H:
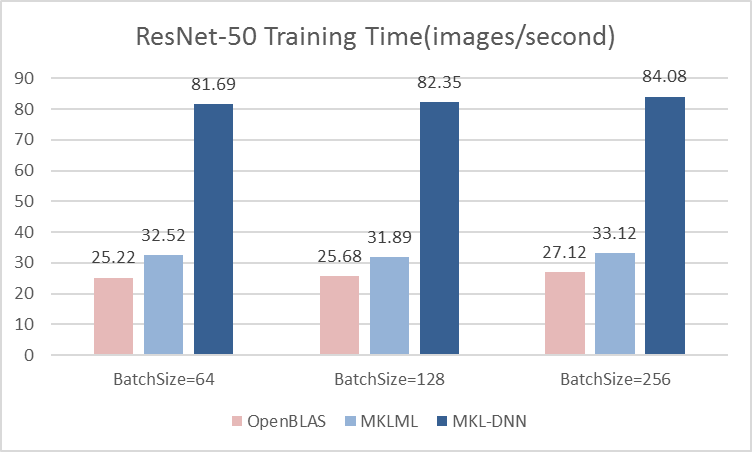
| W: | H:
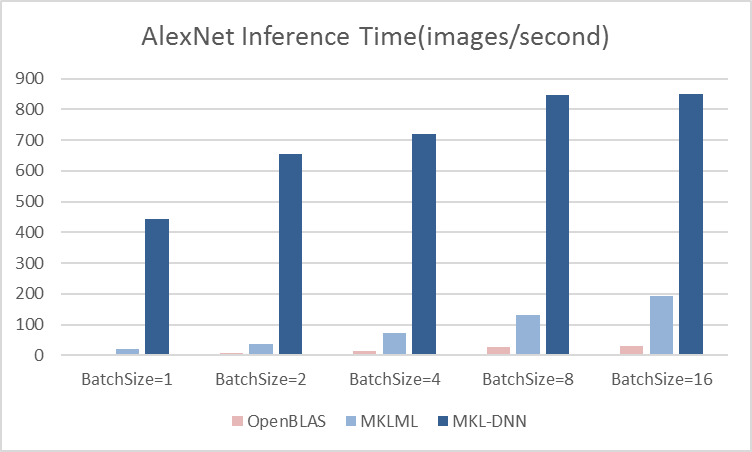
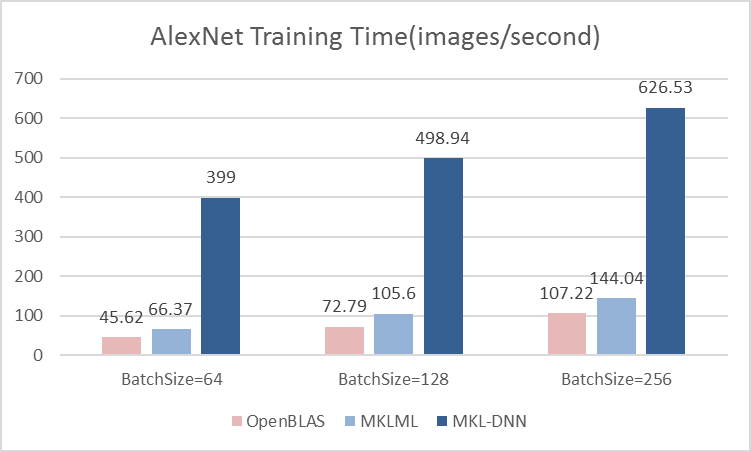
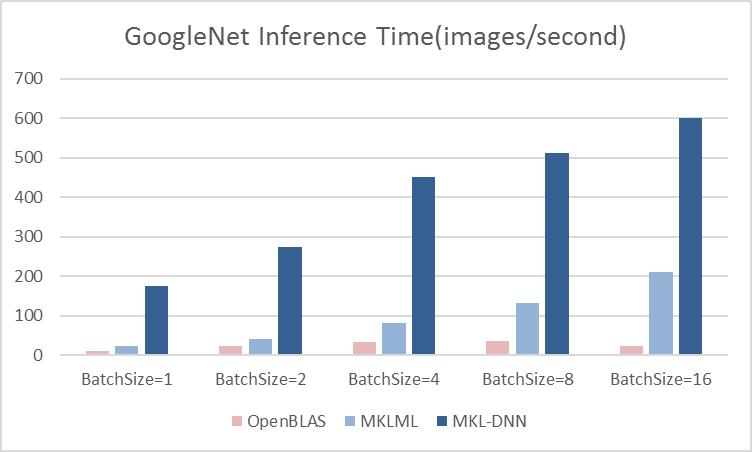
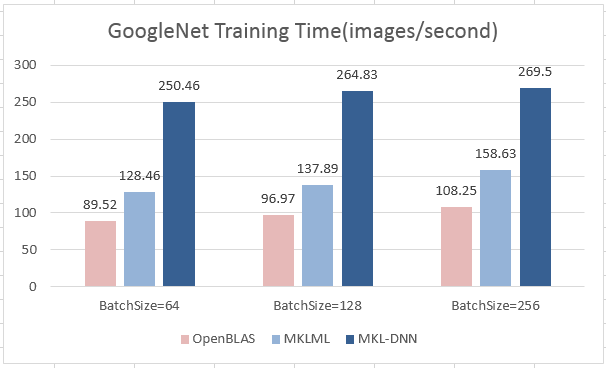
benchmark/figs/vgg-cpu-infer.png
0 → 100644
{kind=link}
13.7 KB
{kind=link}
{kind=link}
| W: | H:
| W: | H:
benchmark/fluid/README.md
0 → 100644
benchmark/fluid/kube_gen_job.py
0 → 100644
benchmark/fluid/models/mnist.py
0 → 100644
benchmark/fluid/models/resnet.py
0 → 100644
benchmark/fluid/models/vgg.py
0 → 100644
benchmark/fluid/run.sh
0 → 100644
benchmark/paddle/image/plotlog.py
0 → 100644
此差异已折叠。
benchmark/tensorflow/mnist.py
0 → 100644
benchmark/tensorflow/resnet.py
0 → 100644
benchmark/tensorflow/vgg.py
0 → 100644
此差异已折叠。
此差异已折叠。
cmake/cpplint.cmake
已删除
100644 → 0
此差异已折叠。
此差异已折叠。
cmake/cupti.cmake
0 → 100644
此差异已折叠。
cmake/external/boost.cmake
0 → 100644
此差异已折叠。
cmake/external/nccl.cmake
已删除
100644 → 0
此差异已折叠。
cmake/external/snappy.cmake
0 → 100644
此差异已折叠。
cmake/external/snappystream.cmake
0 → 100644
此差异已折叠。
cmake/external/threadpool.cmake
0 → 100644
此差异已折叠。
此差异已折叠。
cmake/hip.cmake
0 → 100644
此差异已折叠。
cmake/inference_lib.cmake
0 → 100644
此差异已折叠。
此差异已折叠。
cmake/tensorrt.cmake
0 → 100644
此差异已折叠。
此差异已折叠。
doc/api/index_cn.rst
已删除
100644 → 0
此差异已折叠。
doc/api/index_en.rst
已删除
100644 → 0
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
doc/api/v1/index_cn.rst
已删除
100644 → 0
此差异已折叠。
doc/api/v1/index_en.rst
已删除
100644 → 0
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
doc/api/v2/config/layer.rst
已删除
100644 → 0
此差异已折叠。
此差异已折叠。
doc/api/v2/data/dataset.rst
已删除
100644 → 0
此差异已折叠。
doc/api/v2/fluid.rst
已删除
100644 → 0
此差异已折叠。
此差异已折叠。
此差异已折叠。
doc/api/v2/fluid/executor.rst
已删除
100644 → 0
此差异已折叠。
此差异已折叠。
doc/api/v2/fluid/layers.rst
已删除
100644 → 0
此差异已折叠。
doc/api/v2/fluid/nets.rst
已删除
100644 → 0
此差异已折叠。
此差异已折叠。
此差异已折叠。
doc/api/v2/fluid/profiler.rst
已删除
100644 → 0
此差异已折叠。
此差异已折叠。
doc/design/api.md
已删除
100644 → 0
此差异已折叠。
此差异已折叠。
doc/design/block.md
已删除
100644 → 0
此差异已折叠。
此差异已折叠。
doc/design/evaluator.md
已删除
100644 → 0
此差异已折叠。
doc/design/executor.md
已删除
100644 → 0
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
{kind=link}
此差异已折叠。
doc/design/float16.md
已删除
100644 → 0
此差异已折叠。
此差异已折叠。
doc/design/gan_api.md
已删除
100644 → 0
此差异已折叠。
doc/design/images/replica.png
已删除
100644 → 0
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
doc/design/mkldnn/README.MD
已删除
100644 → 0
此差异已折叠。
doc/design/model_format.md
已删除
100644 → 0
此差异已折叠。
doc/design/ops/rnn.md
已删除
100644 → 0
此差异已折叠。
此差异已折叠。
doc/design/optimizer.md
已删除
100644 → 0
此差异已折叠。
此差异已折叠。
doc/design/program.md
已删除
100644 → 0
此差异已折叠。
doc/design/python_api.md
已删除
100644 → 0
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
{kind=link}
此差异已折叠。
此差异已折叠。
{kind=link}
此差异已折叠。
doc/design/refactorization.md
已删除
100644 → 0
此差异已折叠。
doc/design/regularization.md
已删除
100644 → 0
此差异已折叠。
此差异已折叠。
doc/design/scope.md
已删除
100644 → 0
此差异已折叠。
doc/design/speech/README.MD
已删除
100644 → 0
此差异已折叠。
doc/design/var_desc.md
已删除
100644 → 0
此差异已折叠。
此差异已折叠。
doc/faq/index_cn.rst
已删除
100644 → 0
此差异已折叠。
doc/faq/local/index_cn.rst
已删除
100644 → 0
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
doc/faq/model/index_cn.rst
已删除
100644 → 0
此差异已折叠。
此差异已折叠。
doc/fluid/CMakeLists.txt
0 → 100644
此差异已折叠。
doc/fluid/api/CMakeLists.txt
0 → 100644
此差异已折叠。
doc/fluid/api/clip.rst
0 → 100644
此差异已折叠。
此差异已折叠。
doc/fluid/api/data/dataset.rst
0 → 100644
此差异已折叠。
doc/fluid/api/data_feeder.rst
0 → 100644
此差异已折叠。
doc/fluid/api/evaluator.rst
0 → 100644
此差异已折叠。
doc/fluid/api/executor.rst
0 → 100644
此差异已折叠。
doc/fluid/api/gen_doc.py
0 → 100644
此差异已折叠。
doc/fluid/api/gen_doc.sh
0 → 100755
此差异已折叠。
doc/fluid/api/index_en.rst
0 → 100644
此差异已折叠。
doc/fluid/api/initializer.rst
0 → 100644
此差异已折叠。
doc/fluid/api/io.rst
0 → 100644
此差异已折叠。
doc/fluid/api/layers.rst
0 → 100644
此差异已折叠。
doc/fluid/api/metrics.rst
0 → 100644
此差异已折叠。
doc/fluid/api/nets.rst
0 → 100644
此差异已折叠。
doc/fluid/api/optimizer.rst
0 → 100644
此差异已折叠。
doc/fluid/api/param_attr.rst
0 → 100644
此差异已折叠。
doc/fluid/api/profiler.rst
0 → 100644
此差异已折叠。
doc/fluid/api/regularizer.rst
0 → 100644
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
{kind=link}
此差异已折叠。
此差异已折叠。
此差异已折叠。
{kind=link}
{kind=link}
文件已移动
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
{kind=link}
此差异已折叠。
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
{kind=link}
此差异已折叠。
此差异已折叠。
{kind=link}
此差异已折叠。
此差异已折叠。
{kind=link}
此差异已折叠。
文件已移动
{kind=link}
文件已移动
文件已移动
{kind=link}
文件已移动
此差异已折叠。
{kind=link}
此差异已折叠。
此差异已折叠。
文件已移动
{kind=link}
文件已移动
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
文件已移动
{kind=link}
文件已移动
此差异已折叠。
{kind=link}
此差异已折叠。
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
文件已移动
{kind=link}
文件已移动
此差异已折叠。
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
文件已移动
{kind=link}
文件已移动
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
doc/fluid/design/index_cn.rst
0 → 100644
此差异已折叠。
doc/fluid/design/index_en.rst
0 → 100644
此差异已折叠。
此差异已折叠。
此差异已折叠。
doc/fluid/design/memory/README.md
0 → 100644
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
文件已移动
{kind=link}
文件已移动
{kind=link}
文件已移动
{kind=link}
文件已移动
{kind=link}
文件已移动
{kind=link}
文件已移动
{kind=link}
文件已移动
{kind=link}
文件已移动
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
{kind=link}
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
{kind=link}
文件已移动
{kind=link}
此差异已折叠。
{kind=link}
文件已移动
此差异已折叠。
此差异已折叠。
此差异已折叠。
{kind=link}
此差异已折叠。
此差异已折叠。
此差异已折叠。
{kind=link}
此差异已折叠。
文件已移动
文件已移动
{kind=link}
文件已移动
{kind=link}
文件已移动
{kind=link}
文件已移动
文件已移动
{kind=link}
doc/fluid/dev/api_doc_std_cn.md
0 → 100644
此差异已折叠。
doc/fluid/dev/api_doc_std_en.md
0 → 100644
此差异已折叠。
doc/fluid/dev/ci_build_whl.png
0 → 100644
{kind=link}
此差异已折叠。
此差异已折叠。
此差异已折叠。
doc/fluid/dev/index_cn.rst
0 → 100644
此差异已折叠。
doc/fluid/dev/index_en.rst
0 → 100644
此差异已折叠。
doc/fluid/dev/name_convention.md
0 → 100644
此差异已折叠。
doc/fluid/dev/new_op_cn.md
0 → 100644
此差异已折叠。
doc/fluid/dev/new_op_en.md
0 → 100644
此差异已折叠。
doc/fluid/dev/new_op_kernel.md
0 → 100644
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
doc/fluid/dev/src/fc.py
0 → 100644
此差异已折叠。
此差异已折叠。
doc/fluid/dev/use_eigen_cn.md
0 → 100644
此差异已折叠。
doc/fluid/dev/use_eigen_en.md
0 → 100644
此差异已折叠。
doc/fluid/dev/write_docs_cn.rst
0 → 120000
此差异已折叠。
doc/fluid/dev/write_docs_en.rst
0 → 120000
此差异已折叠。
doc/fluid/faq/index_cn.rst
0 → 100644
此差异已折叠。
doc/fluid/faq/index_en.rst
0 → 100644
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
doc/fluid/getstarted/index_cn.rst
0 → 100644
此差异已折叠。
doc/fluid/getstarted/index_en.rst
0 → 100644
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
doc/fluid/howto/index_cn.rst
0 → 100644
此差异已折叠。
doc/fluid/howto/index_en.rst
0 → 100644
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
{kind=link}
{kind=link}
{kind=link}
此差异已折叠。
此差异已折叠。
{kind=link}
此差异已折叠。
此差异已折叠。
{kind=link}
此差异已折叠。
此差异已折叠。
此差异已折叠。
{kind=link}
此差异已折叠。
此差异已折叠。
{kind=link}
此差异已折叠。
此差异已折叠。
此差异已折叠。
doc/fluid/images/1.png
0 → 100644
{kind=link}
此差异已折叠。
doc/fluid/images/2.png
0 → 100644
{kind=link}
此差异已折叠。
doc/fluid/images/2_level_rnn.dot
0 → 100644
此差异已折叠。
doc/fluid/images/2_level_rnn.png
0 → 100644
{kind=link}
此差异已折叠。
doc/fluid/images/3.png
0 → 100644
{kind=link}
此差异已折叠。
doc/fluid/images/4.png
0 → 100644
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
doc/fluid/images/LoDTensor.png
0 → 100644
{kind=link}
此差异已折叠。
doc/fluid/images/asgd.gif
0 → 100644
{kind=link}
此差异已折叠。
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
doc/fluid/images/beam_search.png
0 → 100644
{kind=link}
此差异已折叠。
doc/fluid/images/ci_build_whl.png
0 → 100644
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
doc/fluid/images/compiler.graffle
0 → 100644
此差异已折叠。
doc/fluid/images/compiler.png
0 → 100644
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
doc/fluid/images/dcgan.png
0 → 100644
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
此差异已折叠。
doc/fluid/images/dist-graph.png
0 → 100644
{kind=link}
此差异已折叠。
此差异已折叠。
{kind=link}
此差异已折叠。
doc/fluid/images/ds2_network.png
0 → 100644
{kind=link}
此差异已折叠。
doc/fluid/images/executor.png
0 → 100644
{kind=link}
此差异已折叠。
doc/fluid/images/feed_forward.png
0 → 100644
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
此差异已折叠。
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
doc/fluid/images/layer.png
0 → 100644
{kind=link}
此差异已折叠。
此差异已折叠。
doc/fluid/images/local-graph.png
0 → 100644
{kind=link}
此差异已折叠。
此差异已折叠。
{kind=link}
此差异已折叠。
doc/fluid/images/lookup_table.png
0 → 100644
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
此差异已折叠。
{kind=link}
此差异已折叠。
此差异已折叠。
{kind=link}
此差异已折叠。
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
doc/fluid/images/op.dot
0 → 100644
此差异已折叠。
此差异已折叠。
此差异已折叠。
doc/fluid/images/operator1.png
0 → 100644
{kind=link}
此差异已折叠。
doc/fluid/images/operator2.png
0 → 100644
{kind=link}
此差异已折叠。
此差异已折叠。
{kind=link}
此差异已折叠。
doc/fluid/images/place.png
0 → 100644
{kind=link}
此差异已折叠。
doc/fluid/images/pprof_1.png
0 → 100644
{kind=link}
此差异已折叠。
doc/fluid/images/pprof_2.png
0 → 100644
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
doc/fluid/images/profiler.png
0 → 100644
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
doc/fluid/images/raw_input.png
0 → 100644
{kind=link}
此差异已折叠。
doc/fluid/images/readers.png
0 → 100644
{kind=link}
此差异已折叠。
此差异已折叠。
{kind=link}
此差异已折叠。
doc/fluid/images/rnn.dot
0 → 100644
此差异已折叠。
doc/fluid/images/rnn.jpg
0 → 100644
{kind=link}
此差异已折叠。
doc/fluid/images/rnn.png
0 → 100644
{kind=link}
此差异已折叠。
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
doc/fluid/images/sorted_input.png
0 → 100644
{kind=link}
此差异已折叠。
此差异已折叠。
{kind=link}
此差异已折叠。
doc/fluid/images/test.dot
0 → 100644
此差异已折叠。
doc/fluid/images/test.dot.png
0 → 100644
{kind=link}
此差异已折叠。
doc/fluid/images/theta_star.gif
0 → 100644
{kind=link}
此差异已折叠。
doc/fluid/images/timeline.jpeg
0 → 100644
{kind=link}
此差异已折叠。
doc/fluid/images/tracing.jpeg
0 → 100644
{kind=link}
此差异已折叠。
doc/fluid/images/transpiler.png
0 → 100644
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
doc/fluid/index_cn.rst
0 → 100644
此差异已折叠。
doc/fluid/index_en.rst
0 → 100644
此差异已折叠。
doc/fluid/read_source.md
0 → 100644
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
doc/getstarted/index_cn.rst
已删除
100644 → 0
此差异已折叠。
doc/getstarted/index_en.rst
已删除
100644 → 0
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
doc/howto/dev/build_cn.md
已删除
100644 → 0
此差异已折叠。
doc/howto/dev/build_en.md
已删除
100644 → 0
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
doc/howto/dev/new_op_cn.md
已删除
100644 → 0
此差异已折叠。
doc/howto/dev/new_op_en.md
已删除
100644 → 0
此差异已折叠。
doc/howto/dev/use_eigen_cn.md
已删除
100644 → 0
此差异已折叠。
doc/howto/dev/use_eigen_en.md
已删除
100644 → 0
此差异已折叠。
此差异已折叠。
此差异已折叠。
doc/howto/index_cn.rst
已删除
100644 → 0
此差异已折叠。
doc/howto/index_en.rst
已删除
100644 → 0
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
doc/howto/usage/k8s/k8s_cn.md
已删除
100644 → 0
此差异已折叠。
此差异已折叠。
doc/howto/usage/k8s/k8s_en.md
已删除
100644 → 0
此差异已折叠。
此差异已折叠。
{kind=link}
此差异已折叠。
此差异已折叠。
doc/index_cn.rst
已删除
100644 → 0
此差异已折叠。
doc/index_en.rst
已删除
100644 → 0
此差异已折叠。
doc/mobile/CMakeLists.txt
0 → 100644
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
doc/v2/CMakeLists.txt
0 → 100644
此差异已折叠。
doc/v2/api/CMakeLists.txt
0 → 100644
此差异已折叠。
doc/v2/api/config/layer.rst
0 → 100644
此差异已折叠。
doc/v2/api/data.rst
0 → 100644
此差异已折叠。
doc/v2/api/data/data_reader.rst
0 → 100644
此差异已折叠。
doc/v2/api/data/dataset.rst
0 → 100644
此差异已折叠。
doc/v2/api/data/image.rst
0 → 100644
此差异已折叠。
doc/v2/api/index_en.rst
0 → 100644
此差异已折叠。
doc/v2/api/overview.rst
0 → 100644
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
{kind=link}
文件已移动
此差异已折叠。
此差异已折叠。
文件已移动
文件已移动
文件已移动
文件已移动
文件已移动
文件已移动
文件已移动
{kind=link}
文件已移动
{kind=link}
文件已移动
文件已移动
{kind=link}
文件已移动
文件已移动
{kind=link}
文件已移动
文件已移动
{kind=link}
文件已移动
{kind=link}
文件已移动
文件已移动
{kind=link}
文件已移动
文件已移动
{kind=link}
文件已移动
{kind=link}
文件已移动
{kind=link}
文件已移动
文件已移动
文件已移动
{kind=link}
文件已移动
文件已移动
{kind=link}
文件已移动
文件已移动
{kind=link}
文件已移动
文件已移动
{kind=link}
文件已移动
文件已移动
{kind=link}
文件已移动
文件已移动
文件已移动
文件已移动
此差异已折叠。
此差异已折叠。
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
doc/v2/design/mkl/mkl_packed.md
0 → 100644
此差异已折叠。
doc/v2/design/mkl/mkldnn.md
0 → 100644
此差异已折叠。
此差异已折叠。
文件已移动
doc/v2/dev/index_cn.rst
0 → 100644
此差异已折叠。
doc/v2/dev/index_en.rst
0 → 100644
此差异已折叠。
doc/v2/dev/new_layer_cn.rst
0 → 100644
此差异已折叠。
doc/v2/dev/new_layer_en.rst
0 → 100644
此差异已折叠。
{kind=link}
doc/v2/dev/src/doc_en.png
0 → 100644
{kind=link}
此差异已折叠。
doc/v2/dev/write_docs_cn.rst
0 → 100644
此差异已折叠。
doc/v2/dev/write_docs_en.rst
0 → 100644
此差异已折叠。
此差异已折叠。
此差异已折叠。
doc/v2/faq/cluster/index_en.rst
0 → 100644
此差异已折叠。
doc/v2/faq/index_cn.rst
0 → 100644
此差异已折叠。
doc/v2/faq/index_en.rst
0 → 100644
此差异已折叠。
doc/v2/faq/local/index_cn.rst
0 → 100644
此差异已折叠。
doc/v2/faq/local/index_en.rst
0 → 100644
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
doc/v2/faq/model/index_cn.rst
0 → 100644
此差异已折叠。
doc/v2/faq/model/index_en.rst
0 → 100644
此差异已折叠。
doc/v2/faq/parameter/index_cn.rst
0 → 100644
此差异已折叠。
doc/v2/faq/parameter/index_en.rst
0 → 100644
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
doc/v2/getstarted/index_cn.rst
0 → 100644
此差异已折叠。
doc/v2/getstarted/index_en.rst
0 → 100644
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
doc/v2/howto/capi/images/csr.png
0 → 100644
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
doc/v2/howto/capi/index_cn.rst
0 → 100644
此差异已折叠。
doc/v2/howto/capi/index_en.rst
0 → 100644
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
doc/v2/howto/cluster/index_cn.rst
0 → 100644
此差异已折叠。
doc/v2/howto/cluster/index_en.rst
0 → 100644
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
{kind=link}
文件已移动
{kind=link}
文件已移动
{kind=link}
此差异已折叠。
文件已移动
文件已移动
文件已移动
此差异已折叠。
文件已移动
文件已移动
文件已移动
{kind=link}
文件已移动
{kind=link}
文件已移动
{kind=link}
文件已移动
{kind=link}
文件已移动
此差异已折叠。
此差异已折叠。
此差异已折叠。
{kind=link}
文件已移动
{kind=link}
文件已移动
{kind=link}
文件已移动
{kind=link}
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
文件已移动
文件已移动
文件已移动
文件已移动
此差异已折叠。
此差异已折叠。
文件已移动
文件已移动
doc/v2/howto/index_cn.rst
0 → 100644
此差异已折叠。
doc/v2/howto/index_en.rst
0 → 100644
此差异已折叠。
此差异已折叠。
此差异已折叠。
{kind=link}
{kind=link}
{kind=link}
{kind=link}
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
doc/v2/howto/rnn/index_cn.rst
0 → 100644
此差异已折叠。
doc/v2/howto/rnn/index_en.rst
0 → 100644
此差异已折叠。
文件已移动
此差异已折叠。
文件已移动
文件已移动
{kind=link}
{kind=link}
文件已移动
文件已移动
文件已移动
文件已移动
文件已移动
doc/v2/images/FullyConnected.jpg
0 → 100644
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
doc/v2/images/bi_lstm.jpg
0 → 100644
{kind=link}
此差异已折叠。
doc/v2/images/checkpointing.png
0 → 100644
{kind=link}
此差异已折叠。
doc/v2/images/create_efs.png
0 → 100644
{kind=link}
此差异已折叠。
doc/v2/images/csr.png
0 → 100644
{kind=link}
此差异已折叠。
doc/v2/images/data_dispatch.png
0 → 100644
{kind=link}
此差异已折叠。
doc/v2/images/dataset.graffle
0 → 100644
此差异已折叠。
doc/v2/images/dataset.png
0 → 100644
{kind=link}
此差异已折叠。
doc/v2/images/doc_en.png
0 → 100644
{kind=link}
此差异已折叠。
doc/v2/images/efs_mount.png
0 → 100644
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
doc/v2/images/engine.png
0 → 100644
{kind=link}
此差异已折叠。
此差异已折叠。
doc/v2/images/file_storage.png
0 → 100644
{kind=link}
此差异已折叠。
doc/v2/images/glossary_rnn.dot
0 → 100644
此差异已折叠。
此差异已折叠。
doc/v2/images/gradients.png
0 → 100644
{kind=link}
此差异已折叠。
doc/v2/images/init_lock.graffle
0 → 100644
此差异已折叠。
doc/v2/images/init_lock.png
0 → 100644
{kind=link}
此差异已折叠。
doc/v2/images/k8s-paddle-arch.png
0 → 100644
{kind=link}
此差异已折叠。
doc/v2/images/layers.png
0 → 100644
{kind=link}
此差异已折叠。
doc/v2/images/managed_policy.png
0 → 100644
{kind=link}
此差异已折叠。
doc/v2/images/matrix.png
0 → 100644
{kind=link}
此差异已折叠。
doc/v2/images/nvvp1.png
0 → 100644
{kind=link}
此差异已折叠。
doc/v2/images/nvvp2.png
0 → 100644
{kind=link}
此差异已折叠。
doc/v2/images/nvvp3.png
0 → 100644
{kind=link}
此差异已折叠。
doc/v2/images/nvvp4.png
0 → 100644
{kind=link}
此差异已折叠。
doc/v2/images/overview.png
0 → 100644
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
doc/v2/images/paddle-etcd.graffle
0 → 100644
此差异已折叠。
doc/v2/images/paddle-etcd.png
0 → 100644
{kind=link}
此差异已折叠。
此差异已折叠。
{kind=link}
此差异已折叠。
doc/v2/images/paddle-ps-0.png
0 → 100644
{kind=link}
此差异已折叠。
doc/v2/images/paddle-ps-1.png
0 → 100644
{kind=link}
此差异已折叠。
doc/v2/images/paddle-ps.graffle
0 → 100644
此差异已折叠。
此差异已折叠。
{kind=link}
此差异已折叠。
此差异已折叠。
{kind=link}
此差异已折叠。
doc/v2/images/ps_cn.png
0 → 100644
{kind=link}
此差异已折叠。
doc/v2/images/ps_en.png
0 → 100644
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
此差异已折叠。
doc/v2/images/pserver_init.png
0 → 100644
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
doc/v2/images/sequence_data.png
0 → 100644
{kind=link}
此差异已折叠。
此差异已折叠。
此差异已折叠。
doc/v2/images/submit-job.graffle
0 → 100644
此差异已折叠。
doc/v2/images/submit-job.png
0 → 100644
{kind=link}
此差异已折叠。
doc/v2/images/trainer.graffle
0 → 100644
此差异已折叠。
doc/v2/images/trainer.png
0 → 100644
{kind=link}
此差异已折叠。
doc/v2/images/trainer_cn.png
0 → 100644
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
doc/v2/index_cn.rst
0 → 100644
此差异已折叠。
doc/v2/index_en.rst
0 → 100644
此差异已折叠。
此差异已折叠。
{kind=link}
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
paddle/contrib/CMakeLists.txt
0 → 100644
此差异已折叠。
paddle/contrib/float16/.gitignore
0 → 100644
此差异已折叠。
paddle/contrib/float16/README.md
0 → 100644
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。