Skip to content
体验新版
项目
组织
正在加载...
登录
切换导航
打开侧边栏
PaddlePaddle
Paddle
提交
c2a16b5c
P
Paddle
项目概览
PaddlePaddle
/
Paddle
大约 2 年 前同步成功
通知
2325
Star
20933
Fork
5424
代码
文件
提交
分支
Tags
贡献者
分支图
Diff
Issue
1423
列表
看板
标记
里程碑
合并请求
543
Wiki
0
Wiki
分析
仓库
DevOps
项目成员
Pages
P
Paddle
项目概览
项目概览
详情
发布
仓库
仓库
文件
提交
分支
标签
贡献者
分支图
比较
Issue
1,423
Issue
1,423
列表
看板
标记
里程碑
合并请求
543
合并请求
543
Pages
分析
分析
仓库分析
DevOps
Wiki
0
Wiki
成员
成员
收起侧边栏
关闭侧边栏
动态
分支图
创建新Issue
提交
Issue看板
提交
c2a16b5c
编写于
8月 31, 2017
作者:
H
Helin Wang
浏览文件
操作
浏览文件
下载
电子邮件补丁
差异文件
update OP based parameter server design
上级
74b22c37
变更
3
隐藏空白更改
内联
并排
Showing
3 changed file
with
43 addition
and
22 deletion
+43
-22
doc/design/ops/dist_train.md
doc/design/ops/dist_train.md
+43
-22
doc/design/ops/src/dist-graph.graffle
doc/design/ops/src/dist-graph.graffle
+0
-0
doc/design/ops/src/dist-graph.png
doc/design/ops/src/dist-graph.png
+0
-0
未找到文件。
doc/design/ops/dist_train.md
浏览文件 @
c2a16b5c
...
@@ -4,13 +4,13 @@
...
@@ -4,13 +4,13 @@
We propose an approach to implement the parameter server. In this
We propose an approach to implement the parameter server. In this
approach, there is no fundamental difference between the trainer and
approach, there is no fundamental difference between the trainer and
the parameter server: they both run sub
-graphs, but sub-
graphs of
the parameter server: they both run sub
graphs, but sub
graphs of
different purposes.
different purposes.
## Background
## Background
The previous implementations of the parameter server does not run a
The previous implementations of the parameter server does not run a
sub
-
graph. parameter initialization, optimizer computation, network
subgraph. parameter initialization, optimizer computation, network
communication and checkpointing are implemented twice on both the
communication and checkpointing are implemented twice on both the
trainer and the parameter server.
trainer and the parameter server.
...
@@ -26,35 +26,40 @@ server becomes a natural extension.
...
@@ -26,35 +26,40 @@ server becomes a natural extension.
### Graph Converter
### Graph Converter
The
*graph converter*
converts the user-defined operation (OP) graph
The
*graph converter*
converts the user-defined operation (OP) graph
into sub-graphs to be scheduled on different nodes.
into subgraphs to be scheduled on different nodes with the following
steps:
1.
The user-defined OP graph will be cut into sub-graphs of
1.
OP placement: the OPs will be placed on different nodes according
different purposes (e.g., trainer, parameter server) to run on
to heuristic that minimizes estimated total computation
different workers.
time. Currently we will use a simple heuristic that puts parameter
varable on parameter server workers and everything else on trainer
workers.
1.
OPs will be added to the subgraphs, so the subgraphs can
1.
Add communication OPs to enable the communication between nodes.
communicate with each other. We will need these OPs:
*send*
,
*recv*
,
*gradient accumulator*
,
*string accumulator*
,
*loop forever
*
.
We will need these OPs:
*Send*
,
*Recv*
,
*Enqueue*
,
*Dequeue
*
.
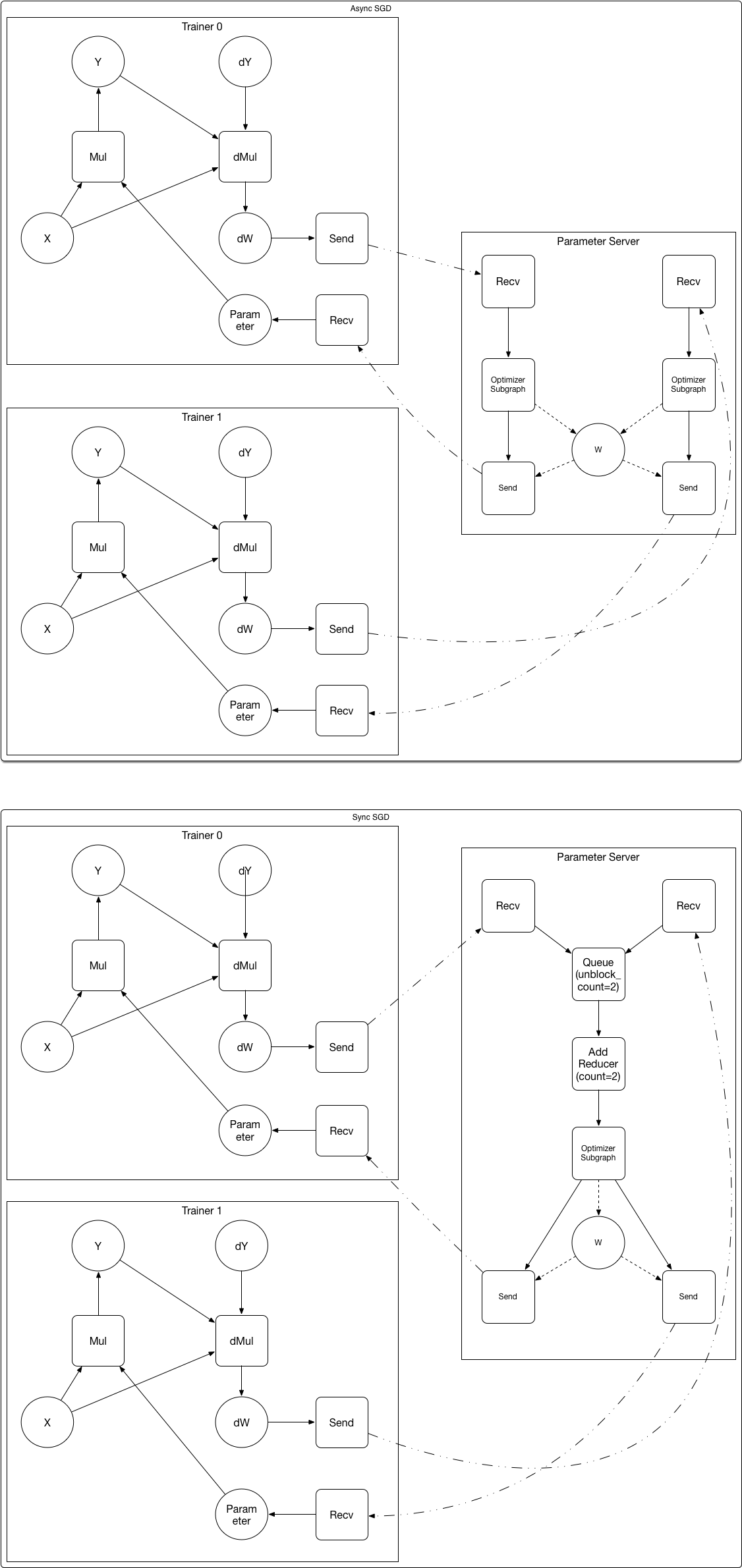
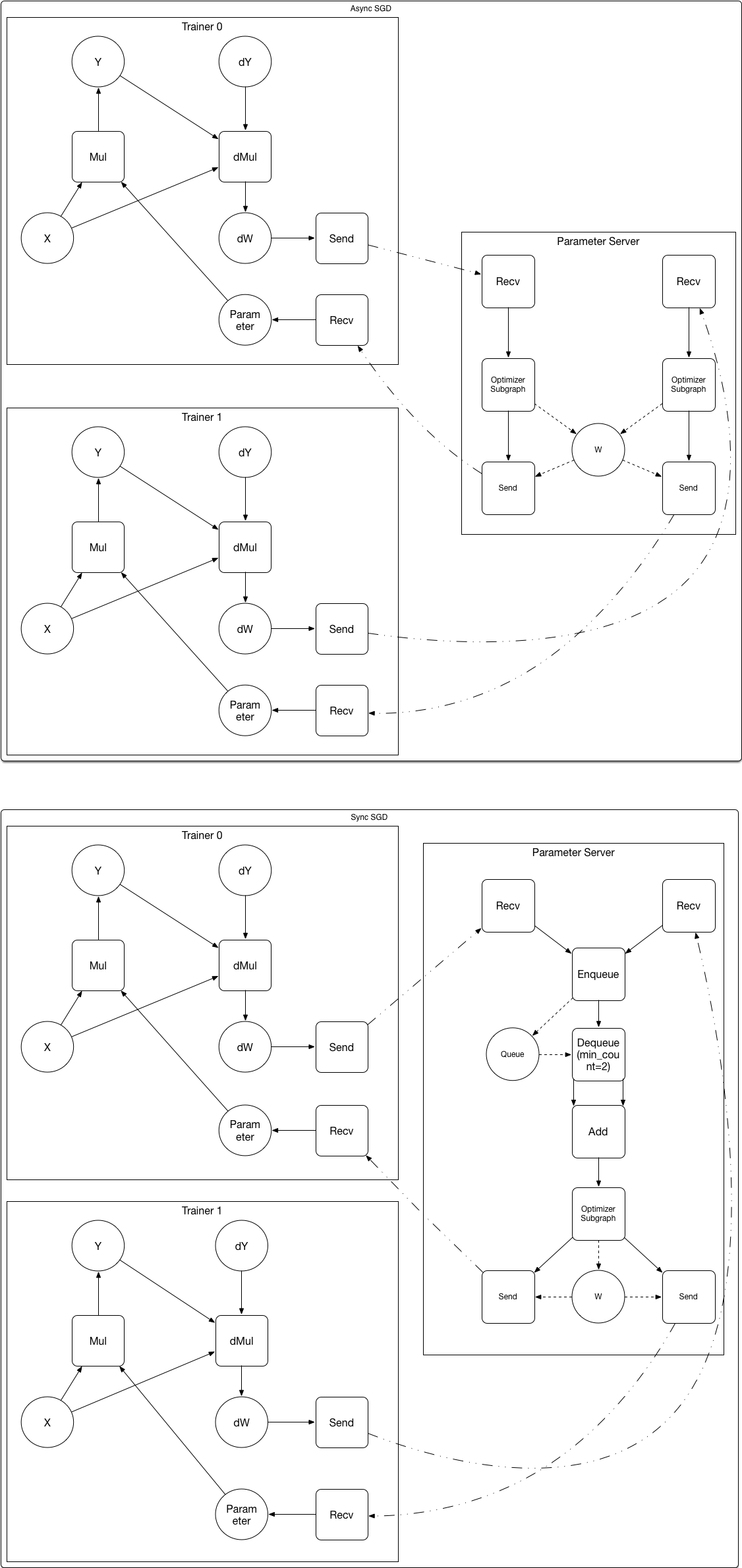
Below is an example of converting the user defined graph to the
Below is an example of converting the user defined graph to the
sub
-
graphs for the trainer and the parameter server:
subgraphs for the trainer and the parameter server:
<img
src=
"src/local-graph.png"
width=
"300"
/>
<img
src=
"src/local-graph.png"
width=
"300"
/>
After converting:
After converting:
<img
src=
"src/dist-graph.png"
width=
"
5
00"
/>
<img
src=
"src/dist-graph.png"
width=
"
7
00"
/>
1.
The parameter variable W and it's optimizer subgraph are placed on the parameter server.
1.
The parameter variable W and it's optimizer subgraph are placed on the parameter server.
1.
Operators are added to the sub-graphs.
1.
Operators are added to the subgraphs.
-
*send*
operator sends data and sender's address to the destination.
-
*Send*
sends data to the connected
*Recv*
operator. The
-
*recv*
operator receives data and sender's address from the
scheduler on the receive node will only schedule
*Recv*
operator
destination. It will block until data has been received.
to run when the
*Send*
operator has ran (the
*Send*
OP will mark
-
*gradient accumulator*
operator accumulates
*N*
pieces of
the
*Recv*
OP runnable automatically).
gradients. N=1 in Async-SGD, N>1 in Sync-SGD.
-
*Enueue*
enqueues the input variable, it can block until space
-
*string accumulator*
accumulates
*N*
pieces of strings into a
become available in the queue.
list of strings. N=1 in Async-SGD, N>1 in Sync-SGD.
-
*Dequeue*
outputs configurable numbers of tensors from the
-
*loop forever*
runs itself as a target forever.
queue. It will block until the queue have the required number of
tensors.
### Benefits
### Benefits
...
@@ -71,8 +76,8 @@ After converting:
...
@@ -71,8 +76,8 @@ After converting:
### Challenges
### Challenges
-
It might be hard for the graph converter to cut a general graph
-
It might be hard for the graph converter to cut a general graph
(without any hint for which sub
-
graph is the optimizer). We may need
(without any hint for which subgraph is the optimizer). We may need
to label which sub
-
graph inside the OP graph is the optimizer.
to label which subgraph inside the OP graph is the optimizer.
-
It's important to balance the parameter shards of on multiple
-
It's important to balance the parameter shards of on multiple
parameter server. If a single parameter is very big (some
parameter server. If a single parameter is very big (some
...
@@ -80,3 +85,19 @@ After converting:
...
@@ -80,3 +85,19 @@ After converting:
automatically partition the single parameter onto different
automatically partition the single parameter onto different
parameter servers when possible (only element-wise optimizer depends
parameter servers when possible (only element-wise optimizer depends
on the parameter variable).
on the parameter variable).
### Discussion
-
In the "Aync SGD" figure, the "W" variable on the parameter server
could be read and wrote concurrently, what is our locking strategy?
-
Does our current tensor design supports enqueue (put the input tensor
into the queue tensor)?
-
*Dequeue*
OP will have variable numbers of output (depends on the
`min_count`
attribute), does our current design support it? (similar
question for the
*Add*
OP)
References:
[1] (TensorFlow: Large-Scale Machine Learning on Heterogeneous Distributed Systems)[https://static.googleusercontent.com/media/research.google.com/en//pubs/archive/45166.pdf]
doc/design/ops/src/dist-graph.graffle
浏览文件 @
c2a16b5c
无法预览此类型文件
doc/design/ops/src/dist-graph.png
查看替换文件 @
74b22c37
浏览文件 @
c2a16b5c
222.7 KB
|
W:
|
H:
222.2 KB
|
W:
|
H:
2-up
Swipe
Onion skin
编辑
预览
Markdown
is supported
0%
请重试
或
添加新附件
.
添加附件
取消
You are about to add
0
people
to the discussion. Proceed with caution.
先完成此消息的编辑!
取消
想要评论请
注册
或
登录
{kind=link}
{kind=link}