pull develop and fix conflict
Showing
benchmark/IntelOptimizedPaddle.md
0 → 100644
benchmark/paddle/image/resnet.py
0 → 100644
cmake/external/nccl.cmake
0 → 100644
doc/api/v2/data/data_reader.rst
0 → 100644
doc/api/v2/data/dataset.rst
0 → 100644
doc/api/v2/data/image.rst
0 → 100644
doc/design/float16.md
0 → 100644
doc/design/graph_survey.md
0 → 100644
doc/design/images/asgd.gif
0 → 100644
{kind=link}
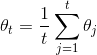
620 字节
{kind=link}
31.5 KB
{kind=link}
45.0 KB
{kind=link}
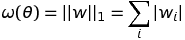
1.1 KB
{kind=link}
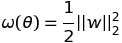
989 字节
{kind=link}

1.6 KB
doc/design/images/theta_star.gif
0 → 100644
{kind=link}
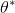
156 字节
doc/design/model_format.md
0 → 100644
{kind=link}

61.2 KB
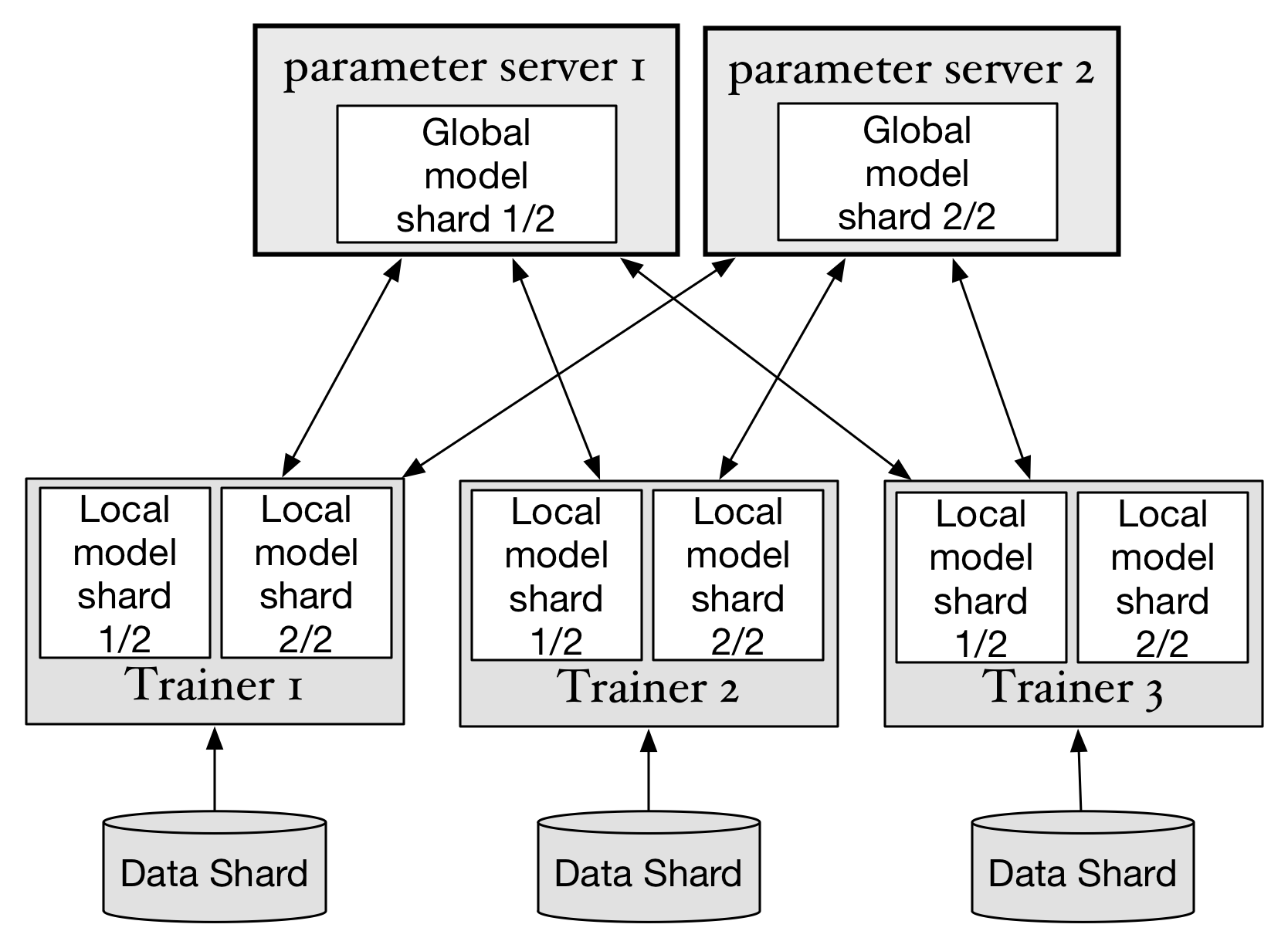
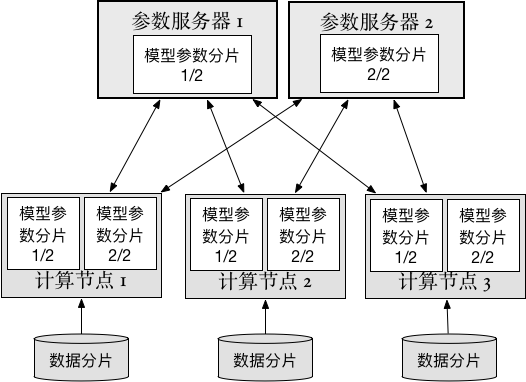
doc/design/parameter_average.md
0 → 100644
doc/design/prune.md
0 → 100644
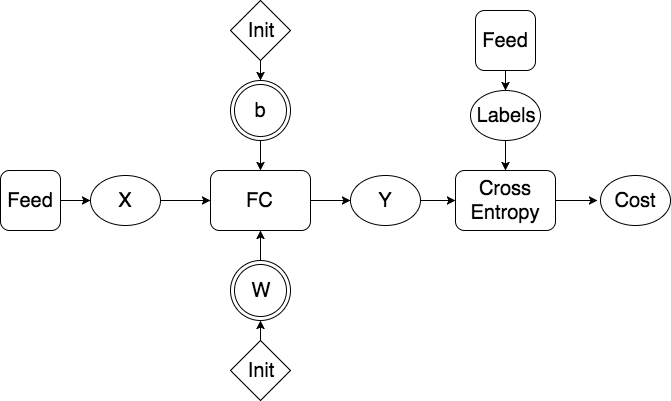
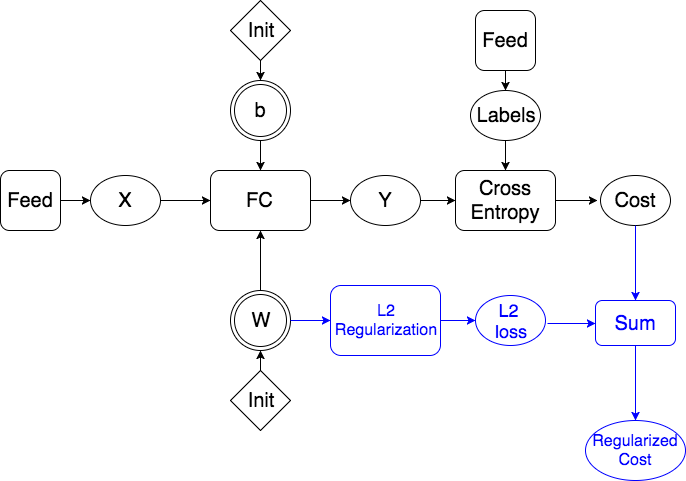
doc/design/regularization.md
0 → 100644
{kind=link}
141.7 KB
{kind=link}
33.1 KB
doc/mobile/index_cn.rst
0 → 100644
doc/mobile/index_en.rst
0 → 100644
go/proto/.gitignore
0 → 100644
此差异已折叠。
此差异已折叠。
paddle/capi/export.sym
已删除
100644 → 0
此差异已折叠。
此差异已折叠。
paddle/framework/lod_rank_table.h
0 → 100644
此差异已折叠。
此差异已折叠。
此差异已折叠。
paddle/framework/proto_desc.h
0 → 100644
此差异已折叠。
paddle/framework/prune.cc
0 → 100644
此差异已折叠。
paddle/framework/prune_test.cc
0 → 100644
此差异已折叠。
此差异已折叠。
paddle/framework/var_type.h
0 → 100644
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
paddle/operators/array_operator.h
0 → 100644
此差异已折叠。
此差异已折叠。
paddle/operators/auc_op.cc
0 → 100644
此差异已折叠。
paddle/operators/auc_op.h
0 → 100644
此差异已折叠。
paddle/operators/batch_norm_op.cc
0 → 100644
此差异已折叠。
paddle/operators/batch_norm_op.cu
0 → 100644
此差异已折叠。
paddle/operators/batch_norm_op.h
0 → 100644
此差异已折叠。
paddle/operators/batch_norm_op.md
0 → 100644
此差异已折叠。
paddle/operators/cast_op.cc
0 → 100644
此差异已折叠。
paddle/operators/cast_op.cu
0 → 100644
此差异已折叠。
paddle/operators/cast_op.h
0 → 100644
此差异已折叠。
paddle/operators/chunk_eval_op.cc
0 → 100644
此差异已折叠。
paddle/operators/chunk_eval_op.h
0 → 100644
此差异已折叠。
此差异已折叠。
此差异已折叠。
paddle/operators/compare_op.cc
0 → 100644
此差异已折叠。
paddle/operators/compare_op.cu
0 → 100644
此差异已折叠。
paddle/operators/compare_op.h
0 → 100644
此差异已折叠。
此差异已折叠。
此差异已折叠。
paddle/operators/conv_op.cu
0 → 100644
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
paddle/operators/fc_op.cc
已删除
100644 → 0
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
paddle/operators/gru_op.cc
0 → 100644
此差异已折叠。
paddle/operators/gru_op.cu
0 → 100644
此差异已折叠。
paddle/operators/gru_op.h
0 → 100644
此差异已折叠。
paddle/operators/huber_loss_op.cc
0 → 100644
此差异已折叠。
paddle/operators/huber_loss_op.cu
0 → 100644
此差异已折叠。
paddle/operators/huber_loss_op.h
0 → 100644
此差异已折叠。
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
paddle/operators/increment_op.cc
0 → 100644
此差异已折叠。
paddle/operators/interp_op.cc
已删除
100644 → 0
此差异已折叠。
paddle/operators/l1_norm_op.cc
0 → 100644
此差异已折叠。
paddle/operators/l1_norm_op.cu
0 → 100644
此差异已折叠。
paddle/operators/l1_norm_op.h
0 → 100644
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
paddle/operators/load_op.cc
0 → 100644
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
paddle/operators/lrn_op.cc
0 → 100644
此差异已折叠。
paddle/operators/lrn_op.cu
0 → 100644
此差异已折叠。
paddle/operators/lrn_op.h
0 → 100644
此差异已折叠。
paddle/operators/lstm_op.cc
0 → 100644
此差异已折叠。
paddle/operators/lstm_op.cu
0 → 100644
此差异已折叠。
paddle/operators/lstm_op.h
0 → 100644
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
paddle/operators/nccl_op.cc
0 → 100644
此差异已折叠。
paddle/operators/nccl_op.cu
0 → 100644
此差异已折叠。
paddle/operators/nccl_op_test.cu
0 → 100644
此差异已折叠。
paddle/operators/pool_cudnn_op.cc
0 → 100644
此差异已折叠。
paddle/operators/pool_cudnn_op.cu
0 → 100644
此差异已折叠。
paddle/operators/pool_cudnn_op.h
0 → 100644
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
paddle/operators/proximal_gd_op.h
0 → 100644
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
paddle/operators/save_op.cc
0 → 100644
此差异已折叠。
paddle/operators/seq_expand_op.cc
0 → 100644
此差异已折叠。
paddle/operators/seq_expand_op.cu
0 → 100644
此差异已折叠。
paddle/operators/seq_expand_op.h
0 → 100644
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
paddle/operators/sign_op.cu
0 → 100644
此差异已折叠。
paddle/operators/sign_op.h
0 → 100644
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
paddle/operators/while_op.cc
0 → 100644
此差异已折叠。
此差异已折叠。
此差异已折叠。
paddle/platform/dynload/nccl.cc
0 → 100644
此差异已折叠。
paddle/platform/dynload/nccl.h
0 → 100644
此差异已折叠。
此差异已折叠。
paddle/platform/nccl_test.cu
0 → 100644
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
python/paddle/v2/framework/io.py
0 → 100644
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。