“abc167338a99f1b644e1a5d4bb324a566d2fd87f”上不存在“develop/doc_cn/api/v2/fluid/optimizer.html”
merge develop, fix conflict
Showing
{kind=link}

52.0 KB
doc/optimization/nvvp1.png
0 → 100644
{kind=link}

416.1 KB
doc/optimization/nvvp2.png
0 → 100644
{kind=link}

483.5 KB
doc/optimization/nvvp3.png
0 → 100644
{kind=link}
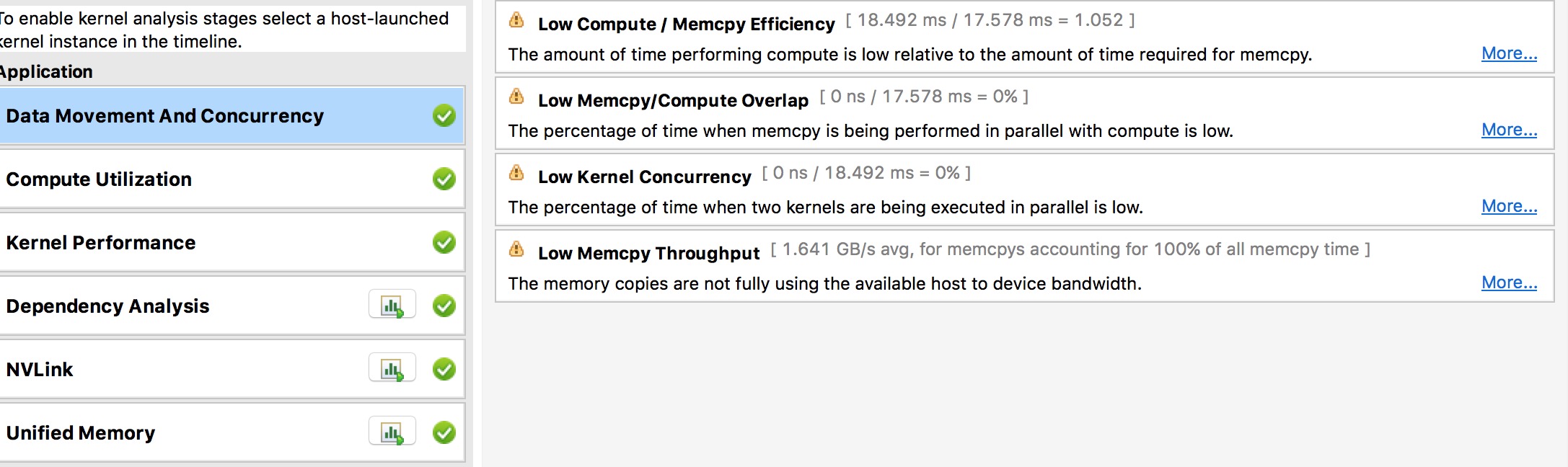
247.8 KB
doc/optimization/nvvp4.png
0 → 100644
{kind=link}

276.6 KB
doc/source/cuda/rnn/index.rst
已删除
100644 → 0
doc/source/gserver/index.rst
0 → 100644
doc/source/gserver/neworks.rst
0 → 100644
doc/source/index.md
已删除
100644 → 0
doc/source/index.rst
0 → 100644
doc/source/math/functions.rst
0 → 100644
doc/source/math/index.rst
0 → 100644
doc/source/math/matrix.rst
0 → 100644
doc/source/math/vector.rst
0 → 100644
doc/source/pserver/client.rst
0 → 100644
doc/source/pserver/index.rst
0 → 100644
doc/source/pserver/network.rst
0 → 100644
doc/source/pserver/server.rst
0 → 100644
doc/source/utils/index.rst
0 → 100644
doc_cn/cluster/k8s/Dockerfile
0 → 100644
doc_cn/cluster/k8s/job.yaml
0 → 100644
{kind=link}

21.6 KB
doc_cn/cluster/k8s/start.sh
0 → 100755
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
paddle/utils/CompilerMacros.h
0 → 100644
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。