Add distributed training overview doc (#9937)
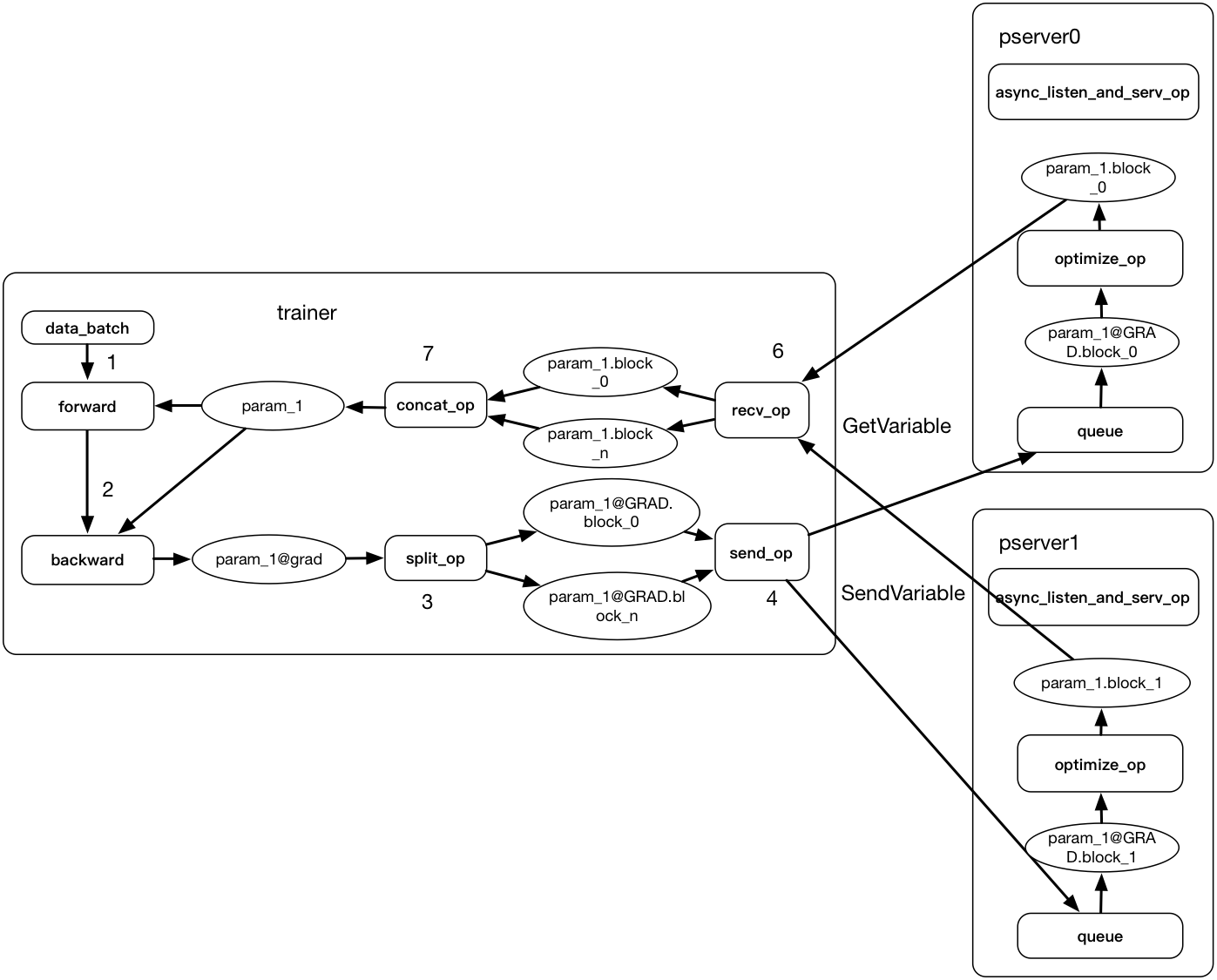
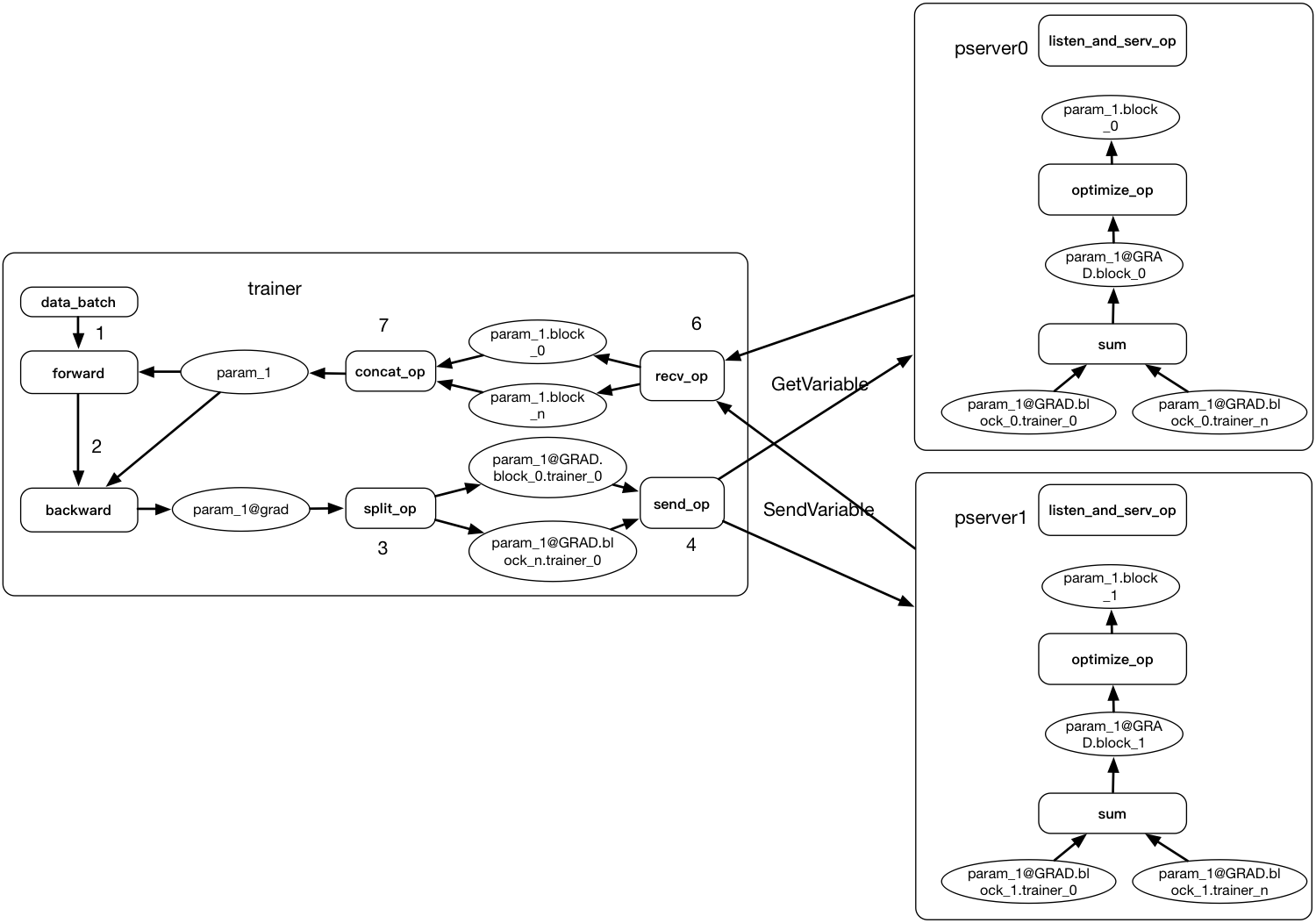
* add asynchronous design doc * update distributed_training.png * add distributed_training.graffle * add async_distributed_training.png * update design doc * change name to distributed_training_overview * follow comment * change distributed_training_overview.md to README.md * update sync_distributed_training.png * follow comment * fix typo
Showing
{kind=link}
180.2 KB
{kind=link}
184.3 KB