Now, we've created a cluster with following network capability:
Training data is usually served on a distributed filesystem, we use Elastic File System (EFS) on AWS. Ceph might be a better solution, but it requires high version of Linux kernel that might not be stable enough at this moment. We haven't automated the EFS setup at this moment, so please do the following steps:
1. All Kubernetes nodes can communicate with each other.
1. All Docker containers on Kubernetes nodes can communicate with each other.
1. All Kubernetes nodes can communicate with all Docker containers on Kubernetes nodes.
1. All other traffic loads from outside of Kubernetes nodes cannot reach to the Docker containers on Kubernetes nodes except for creating the services for containers.
For sharing the training data across all the Kubernetes nodes, we use EFS (Elastic File System) in AWS. Ceph might be a better solution, but it requires high version of Linux kernel that might not be stable enough at this moment. We haven't automated the EFS setup at this moment, so please do the following steps:
1. Make sure you added AmazonElasticFileSystemFullAccess policy in your group.
1. Make sure you added AmazonElasticFileSystemFullAccess policy in your group.
...
@@ -391,57 +380,71 @@ For sharing the training data across all the Kubernetes nodes, we use EFS (Elast
...
@@ -391,57 +380,71 @@ For sharing the training data across all the Kubernetes nodes, we use EFS (Elast
<center></center>
<center></center>
Before starting the training, you should place your user config and divided training data onto EFS. When the training start, each task will copy related files from EFS into container, and it will also write the training results back onto EFS, we will show you how to place the data later in this article.
We will place user config and divided training data onto EFS. Training task will cache related files by copying them from EFS into container. It will also write the training results back onto EFS. We will show you how to place the data later in this article.
### Core Concepts of PaddlePaddle Training on AWS
Now we've already setup a 3 nodes distributed Kubernetes cluster, and on each node we've attached the EFS volume. In this training demo, we will create three Kubernetes pods and schedule them on three nodes. Each pod contains a PaddlePaddle container. When container gets created, it will start parameter server (pserver) and trainer process, load the training data from EFS volume and start the distributed training task.
#### Distributed Training Job
###Core Concept of PaddlePaddle Training on AWS
Distributed training job is represented by a [kubernetes job](https://kubernetes.io/docs/user-guide/jobs/#what-is-a-job).
Now we've already setup a 3 nodes distributed Kubernetes cluster, and on each node we've attached the EFS volume, in this training demo, we will create three Kubernetes pod and scheduling them on 3 node. Each pod contains a PaddlePaddle container. When container gets created, it will start pserver and trainer process, load the training data from EFS volume and start the distributed training task.
Kubernetes job is described by a job config file. The file contains lots of configuration information. For example, PaddlePaddle's node number, `paddle pserver` open port number, the network card info etc. These information are passed into container for `pserver` and `trainer` to use as environment variables.
####Use Kubernetes Job
In one distributed training job, we will:
We use Kubernetes job to represent one time of distributed training. After the job get finished, Kubernetes will destroy job container and release all related resources.
1. Upload the pre-divided training data and configuration file onto EFS volume.
1. Create and submit the Kubernetes job config to the Kubernetes cluster to start the training job.
We can write a yaml file to describe the Kubernetes job. The file contains lots of configuration information, for example PaddlePaddle's node number, `paddle pserver` open port number, the network card info etc., these information are passed into container for processes to use as environment variables.
#### Parameter Server and Trainer
In one time of distributed training, user will confirm the PaddlePaddle node number first. And then upload the pre-divided training data and configuration file onth EFS volume. And then create the Kubernetes job yaml file; submit to the Kubernetes cluster to start the training job.
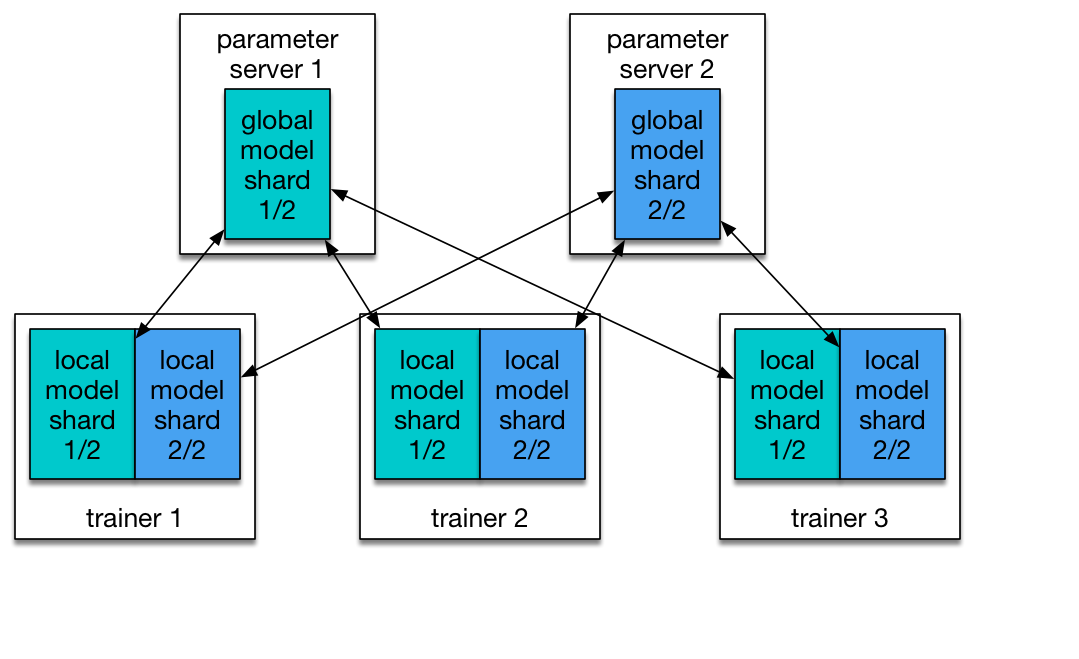
There are two roles in a PaddlePaddle cluster: `parameter server` and `trainer`. Each parameter server process maintains a shard of the global model. Each trainer has its local copy of the model, and uses its local data to update the model. During the training process, trainers send model updates to parameter servers, parameter servers are responsible for aggregating these updates, so that trainers can synchronize their local copy with the global model.
####Create PaddlePaddle Node
<center></center>
After Kubernetes master gets the request, it will parse the yaml file and create several pods (defined by PaddlePaddle's node number), Kubernetes will allocate these pods onto cluster's node. A pod represents a PaddlePaddle node, when pod is successfully allocated onto one physical/virtual machine, Kubernetes will startup the container in the pod, and this container will use the environment variables in yaml file and start up `paddle pserver` and `paddle trainer` processes.
In order to communicate with pserver, trainer needs to know the ip address of each pserver. In kubernetes it's better to use a service discovery mechanism (e.g., DNS hostname) rather than static ip address, since any pserver's pod may be killed and a new pod could be schduled onto another node of different ip address. We will improve paddlepaddle's service discovery ability. For now we will use static ip.
Parameter server and trainer are packaged into a same docker image. They will run once pod is scheduled by kubernetes job.
####Start up Training
#### Trainer ID
After container gets started, it starts up the distributed training by using scripts. We know `paddle train` process need to know other node's ip address and it's own trainer_id, since PaddlePaddle currently don't have the ability to do the service discovery, so in the start up script, each node will use job pod's name to query all to pod info from Kubernetes apiserver (apiserver's endpoint is an environment variable in container by default).
Trainer id is the index of trainer within all trainers of a job. Trainer needs this information to do things like reading the correct shared of data.
With pod information, we can assign each pod a unique trainer_id. Here we sort all the pods by pod's ip, and assign the index to each PaddlePaddle node as it's trainer_id. The workflow of starting up the script is as follows:
#### Training
1. Query the api server to get pod information, and assign the trainer_id by sorting the ip.
After container gets started, it starts up the distributed training by using scripts. Each node will use job pod's name to query Kubernetes apiserver for information of all pods in current job.
From pods information, script knows static ip addresses of pservers. And assign trainer it's own `trainer_id`. The workflow of the script is as follows:
1. Query the api server to get pod information, and assign the `trainer_id` by sorting the ip.
1. Copy the training data from EFS sharing volume into container.
1. Copy the training data from EFS sharing volume into container.
1. Parse the `paddle pserver` and 'paddle trainer' startup parameters from environment variables, and then start up the processes.
1. Parse the `paddle pserver` and `paddle trainer` startup parameters from environment variables, and then start up the processes.
1.PaddlePaddle will automatically write the result onto the PaddlePaddle node with trainer_id:0, we set the output path to be the EFS volume to save the result data.
1.Trainer with `train_id` 0 will automatically write results onto EFS volume.
###Start PaddlePaddle Training Demo on AWS
###Start PaddlePaddle Training Demo on AWS
Now we'll start a PaddlePaddle training demo on AWS, steps are as follows:
Now we'll start a PaddlePaddle training demo on AWS, steps are as follows:
1. Build PaddlePaddle Docker image.
1. Build PaddlePaddle Docker image.
1. Divide the training data file and upload it onto the EFS sharing volume.
1. Divide the training data file and upload it onto the EFS sharing volume.
1. Create the training job yaml file, and start up the job.
1. Create the training job config file, and start up the job.
1. Check the result after training.
1. Check the result after training.
####Build PaddlePaddle Docker Image
####Build PaddlePaddle Docker Image
PaddlePaddle docker image need to provide the runtime environment for `paddle pserver` and `paddle train`, so the container use this image should have two main function:
PaddlePaddle docker image need to provide the runtime environment for `pserver` and `trainer`, so the container use this image should have two main function:
1. Copy the training data into container.
1. Copy the training data into container.
1. Generate the startup parameter for `paddle pserver` and `paddle train` process, and startup the training.
1. Generate the startup parameter for `pserver` and `trainer` process, and startup the training.
We need to create a new image since official `paddledev/paddle:cpu-latest` only have PaddlePaddle binary, but lack of the above functionalities.
Since official `paddledev/paddle:cpu-latest` have already included the PaddlePaddle binary, but lack of the above functionalities, so we will create the startup script based on this image, to achieve the work above. the detailed Dockerfile is as follows:
Dockerfile for creating the new image is as follows:
```
```
FROM paddledev/paddle:cpu-latest
FROM paddledev/paddle:cpu-latest
...
@@ -530,7 +533,7 @@ And then push the built image onto docker registry.
...
@@ -530,7 +533,7 @@ And then push the built image onto docker registry.
docker push your_repo/paddle:mypaddle
docker push your_repo/paddle:mypaddle
```
```
####Upload Training Data File
####Upload Training Data File
Here we will use PaddlePaddle's official recommendation demo as the content for this training, we put the training data file into a directory named by job name, which located in EFS sharing volume, the tree structure for the directory looks like:
Here we will use PaddlePaddle's official recommendation demo as the content for this training, we put the training data file into a directory named by job name, which located in EFS sharing volume, the tree structure for the directory looks like:
...
@@ -550,7 +553,7 @@ efs
...
@@ -550,7 +553,7 @@ efs
The `paddle-cluster-job` directory is the job name for this training, this training includes 3 PaddlePaddle node, we store the pre-divided data under `paddle-cluster-job/data` directory, directory 0, 1, 2 each represent 3 nodes' trainer_id. the training data in in recommendation directory, the training results and logs will be in the output directory.
The `paddle-cluster-job` directory is the job name for this training, this training includes 3 PaddlePaddle node, we store the pre-divided data under `paddle-cluster-job/data` directory, directory 0, 1, 2 each represent 3 nodes' trainer_id. the training data in in recommendation directory, the training results and logs will be in the output directory.
####Create Kubernetes Job
####Create Kubernetes Job
Kubernetes use yaml file to describe job details, and then use command line tool to create the job in Kubernetes cluster.
Kubernetes use yaml file to describe job details, and then use command line tool to create the job in Kubernetes cluster.
...
@@ -632,7 +635,7 @@ After we execute the above command, Kubernetes will create 3 pods and then pull
...
@@ -632,7 +635,7 @@ After we execute the above command, Kubernetes will create 3 pods and then pull
####Check Training Results
####Check Training Results
During the training, we can see the logs and models on EFS sharing volume, the output directory contains the training results. (Caution: node_0, node_1, node_2 directories represents PaddlePaddle node and train_id, not the Kubernetes node)
During the training, we can see the logs and models on EFS sharing volume, the output directory contains the training results. (Caution: node_0, node_1, node_2 directories represents PaddlePaddle node and train_id, not the Kubernetes node)
It'll take around 8 hours to finish this PaddlePaddle recommendation training demo on three 2 core 8 GB EC2 machine (m3.large).
It'll take around 8 hours to finish this PaddlePaddle recommendation training demo on three 2 core 8 GB EC2 machine (m3.large).
###Kubernetes Cluster Tear Down
###Kubernetes Cluster Tear Down
If you want to tear down the whole Kubernetes cluster, make sure to *delete* the EFS volume first (otherwise, you will get stucked on following steps), and then use the following command:
If you want to tear down the whole Kubernetes cluster, make sure to *delete* the EFS volume first (otherwise, you will get stucked on following steps), and then use the following command:
...
@@ -700,16 +703,3 @@ kube-aws destroy
...
@@ -700,16 +703,3 @@ kube-aws destroy
It's an async call, it might take 5 min to tear down the whole cluster.
It's an async call, it might take 5 min to tear down the whole cluster.
If you created any Kubernetes Services of type LoadBalancer, you must delete these first, as the CloudFormation cannot be fully destroyed if any externally-managed resources still exist.
If you created any Kubernetes Services of type LoadBalancer, you must delete these first, as the CloudFormation cannot be fully destroyed if any externally-managed resources still exist.
## For Experts with Kubernetes and AWS
Sometimes we might need to create or manage the cluster on AWS manually with limited privileges, so here we will explain more on what’s going on with the Kubernetes setup script.
### Some Presumptions
* Instances run on CoreOS, the official IAM.
* Kubernetes node use instance storage, no EBS get mounted. Etcd is running on additional node.
* For networking, we use Flannel network at this moment, we will use Calico solution later on.
* When you create a service with Type=LoadBalancer, Kubernetes will create and ELB, and create a security group for the ELB.
{kind=link}