Skip to content
体验新版
项目
组织
正在加载...
登录
切换导航
打开侧边栏
PaddlePaddle
Paddle
提交
845618e2
P
Paddle
项目概览
PaddlePaddle
/
Paddle
大约 2 年 前同步成功
通知
2325
Star
20933
Fork
5424
代码
文件
提交
分支
Tags
贡献者
分支图
Diff
Issue
1423
列表
看板
标记
里程碑
合并请求
543
Wiki
0
Wiki
分析
仓库
DevOps
项目成员
Pages
P
Paddle
项目概览
项目概览
详情
发布
仓库
仓库
文件
提交
分支
标签
贡献者
分支图
比较
Issue
1,423
Issue
1,423
列表
看板
标记
里程碑
合并请求
543
合并请求
543
Pages
分析
分析
仓库分析
DevOps
Wiki
0
Wiki
成员
成员
收起侧边栏
关闭侧边栏
动态
分支图
创建新Issue
提交
Issue看板
未验证
提交
845618e2
编写于
7月 05, 2018
作者:
Y
Yancey
提交者:
GitHub
7月 05, 2018
浏览文件
操作
浏览文件
下载
差异文件
Merge pull request #9068 from Yancey1989/large_model_design_doc
Add design doc for lookup remote table in Fluid
上级
a0fefc27
e343afb1
变更
3
隐藏空白更改
内联
并排
Showing
3 changed file
with
26 addition
and
0 deletion
+26
-0
doc/fluid/design/dist_train/distributed_lookup_table_design.md
...luid/design/dist_train/distributed_lookup_table_design.md
+26
-0
doc/fluid/design/dist_train/src/fluid_lookup_remote_table.graffle
...d/design/dist_train/src/fluid_lookup_remote_table.graffle
+0
-0
doc/fluid/design/dist_train/src/fluid_lookup_remote_table.png
...fluid/design/dist_train/src/fluid_lookup_remote_table.png
+0
-0
未找到文件。
doc/fluid/design/dist_train/distributed_lookup_table_design.md
浏览文件 @
845618e2
...
...
@@ -119,6 +119,32 @@ optimization algorithm $f$ runs on the storage service.
-
Con: the storage service needs to be able to run the optimization
algorithm.
## Distributed Sparse Table in Fluid
For another design, we can implement a distributed sparse table in Fluid,
and don't need to maintain an external storage component while training.
You may need to read Fluid
[
Distributed Training Architecture
](
./distributed_architecture.md
)
and
[
Parameter Server
](
./parameter_server.md
)
before going on.

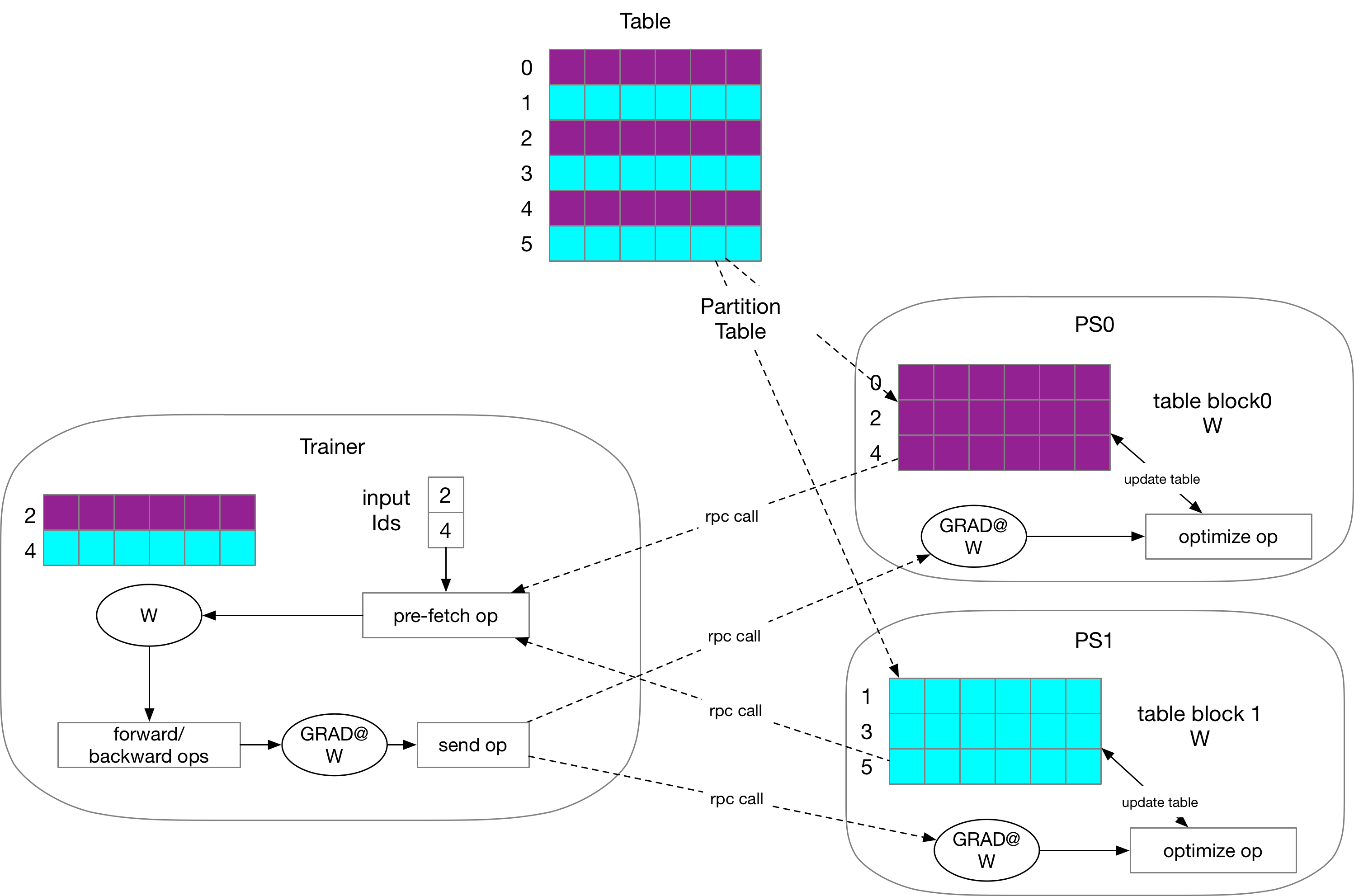
Partition a large table into multiple pserver instances
1.
`DistributeTranspiler`
would split the table partitioned into some small
table blocks with some partitioned algorithms such as
[
RoundRobin
](
https://en.wikipedia.org/wiki/Round-robin_scheduling
)
,
[
Hash
](
https://en.wikipedia.org/wiki/Hash
)
and etc...
1.
For some cases, the range of input
`Ids`
is very wide and unpredictable, so the sparse
table would be able to fill a new value for the id that didn't appear before with
zero, uniform random or Gaussian distribution.
For each Trainer's training process:
1.
In the forward pass, we use
`pre-fetch`
op to pre-fetch parameter blocks according to the
input
`Ids`
from PServers instead of the local
`lookup_table`
op, and then merge the blocks
into a parameter
`W`
.
1.
Compute
`GRAD@W'`
in the backward pass using the pre-fetched
`W`
and send it to PServer to
execute the optimize pass.
## Conclusion
Let us do the "storage service does not optimize" solution first, as a
...
...
doc/fluid/design/dist_train/src/fluid_lookup_remote_table.graffle
0 → 100644
浏览文件 @
845618e2
文件已添加
doc/fluid/design/dist_train/src/fluid_lookup_remote_table.png
0 → 100644
浏览文件 @
845618e2
316.8 KB
编辑
预览
Markdown
is supported
0%
请重试
或
添加新附件
.
添加附件
取消
You are about to add
0
people
to the discussion. Proceed with caution.
先完成此消息的编辑!
取消
想要评论请
注册
或
登录
{kind=link}