Deploy to GitHub Pages: 1ff47b28
Showing
doc/_images/bi_lstm1.jpg
已删除
100644 → 0
{kind=link}
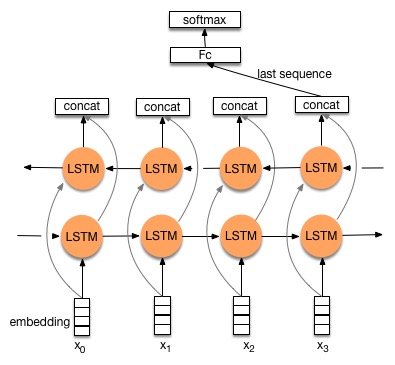
34.8 KB
doc/_images/cifar.png
已删除
100644 → 0
{kind=link}

455.6 KB
doc/_images/curve.jpg
已删除
100644 → 0
{kind=link}
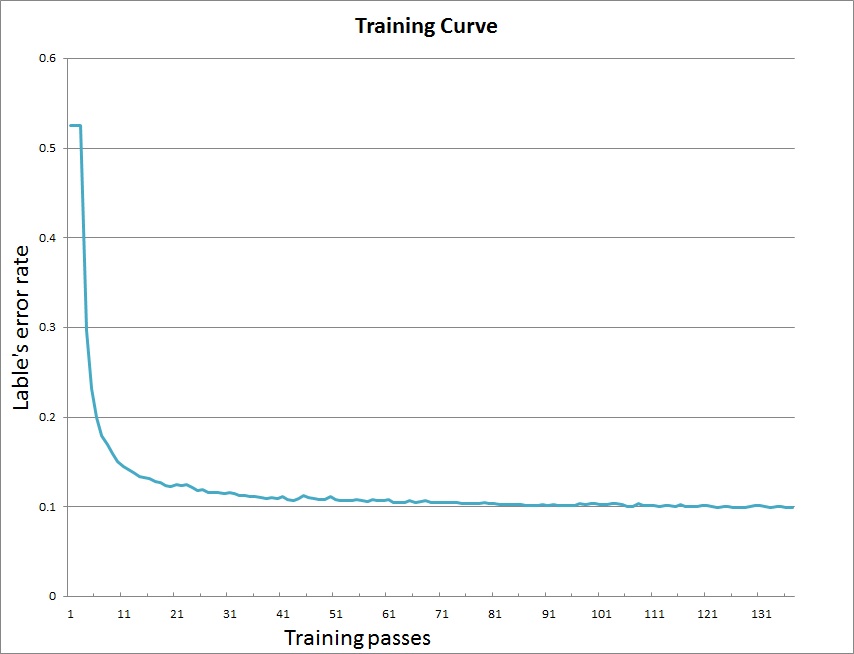
52.0 KB
{kind=link}
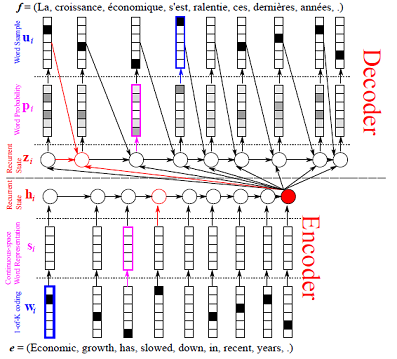
66.5 KB
doc/_images/feature.jpg
已删除
100644 → 0
{kind=link}
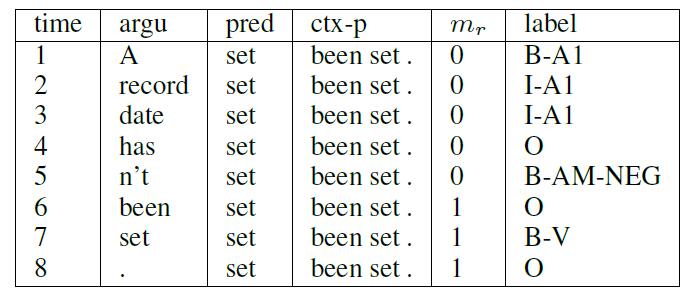
30.5 KB
{kind=link}
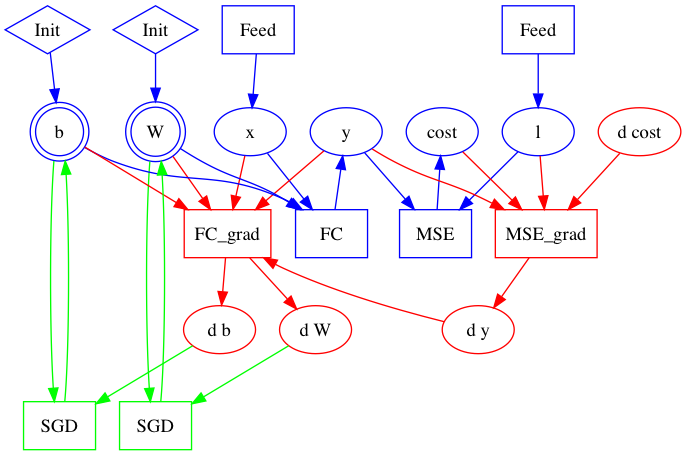
56.2 KB
{kind=link}
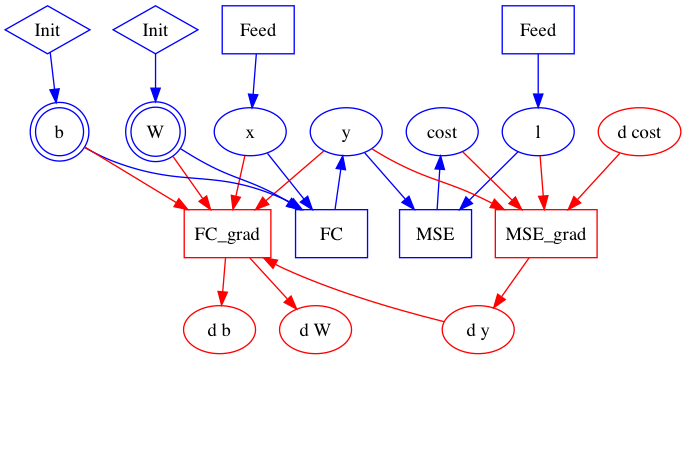
48.9 KB
{kind=link}
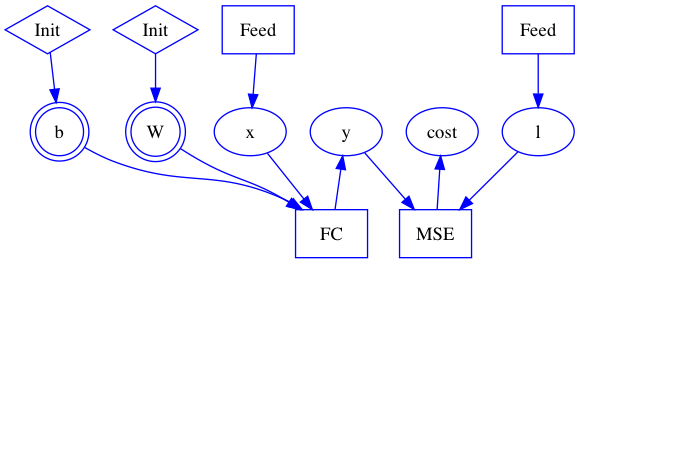
30.1 KB
{kind=link}
51.4 KB
doc/_images/lenet.png
已删除
100644 → 0
{kind=link}
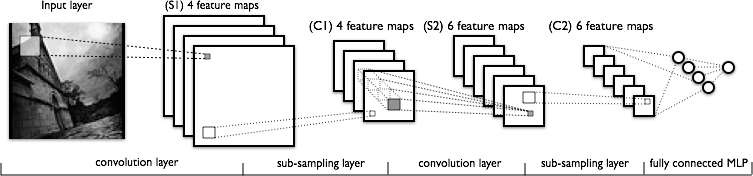
48.7 KB
doc/_images/lstm.png
已删除
100644 → 0
{kind=link}
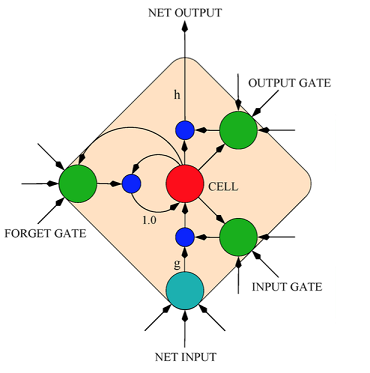
49.5 KB
doc/_images/network_arch.png
已删除
100644 → 0
{kind=link}
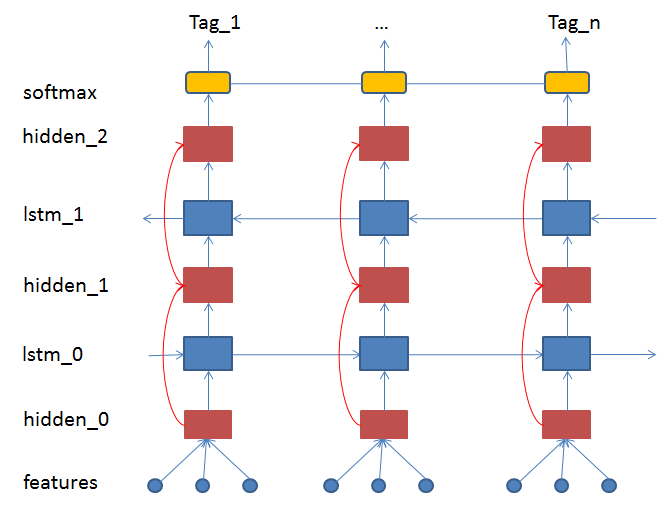
27.2 KB
doc/_images/paddleci.png
0 → 100644
{kind=link}
39.3 KB
doc/_images/parameters.png
已删除
100644 → 0
{kind=link}
43.4 KB
doc/_images/plot.png
已删除
100644 → 0
{kind=link}
30.3 KB
doc/_images/pprof_1.png
0 → 100644
{kind=link}
344.4 KB
doc/_images/pprof_2.png
0 → 100644
{kind=link}

189.5 KB
{kind=link}
81.2 KB
doc/_images/stacked_lstm.jpg
已删除
100644 → 0
{kind=link}
30.3 KB
doc/_sources/api/v2/fluid.rst.txt
0 → 100644
doc/_sources/design/block.md.txt
0 → 100644
doc/_sources/design/graph.md.txt
0 → 100644
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
doc/_sources/design/prune.md.txt
0 → 100644
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
doc/_sources/design/scope.md.txt
0 → 100644
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
文件已移动
文件已移动
文件已移动
文件已移动
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
doc/api/v2/data/data_reader.html
0 → 100644
此差异已折叠。
doc/api/v2/data/dataset.html
0 → 100644
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
doc/api/v2/fluid/initializer.html
0 → 100644
此差异已折叠。
doc/api/v2/fluid/layers.html
0 → 100644
此差异已折叠。
doc/api/v2/fluid/nets.html
0 → 100644
此差异已折叠。
doc/api/v2/fluid/optimizer.html
0 → 100644
此差异已折叠。
doc/api/v2/fluid/param_attr.html
0 → 100644
此差异已折叠。
doc/api/v2/fluid/profiler.html
0 → 100644
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
doc/design/block.html
0 → 100644
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
doc/design/evaluator.html
0 → 100644
此差异已折叠。
doc/design/executor.html
0 → 100644
此差异已折叠。
此差异已折叠。
此差异已折叠。
doc/design/float16.html
0 → 100644
此差异已折叠。
此差异已折叠。
doc/design/gan_api.html
0 → 100644
此差异已折叠。
doc/design/graph.html
0 → 100644
此差异已折叠。
doc/design/graph_survey.html
0 → 100644
此差异已折叠。
doc/design/if_else_op.html
0 → 100644
此差异已折叠。
doc/design/infer_var_type.html
0 → 100644
此差异已折叠。
doc/design/model_format.html
0 → 100644
此差异已折叠。
此差异已折叠。
此差异已折叠。
doc/design/ops/rnn.html
0 → 100644
此差异已折叠。
此差异已折叠。
doc/design/optimizer.html
0 → 100644
此差异已折叠。
doc/design/parameter_average.html
0 → 100644
此差异已折叠。
doc/design/parameters_in_cpp.html
0 → 100644
此差异已折叠。
doc/design/program.html
0 → 100644
此差异已折叠。
doc/design/prune.html
0 → 100644
此差异已折叠。
doc/design/python_api.html
0 → 100644
此差异已折叠。
此差异已折叠。
此差异已折叠。
doc/design/refactor/session.html
0 → 100644
此差异已折叠。
doc/design/refactorization.html
0 → 100644
此差异已折叠。
doc/design/register_grad_op.html
0 → 100644
此差异已折叠。
doc/design/regularization.html
0 → 100644
此差异已折叠。
doc/design/releasing_process.html
0 → 100644
此差异已折叠。
doc/design/scope.html
0 → 100644
此差异已折叠。
doc/design/selected_rows.html
0 → 100644
此差异已折叠。
doc/design/simple_op_design.html
0 → 100644
此差异已折叠。
doc/design/tensor_array.html
0 → 100644
此差异已折叠。
doc/design/var_desc.html
0 → 100644
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
doc/howto/dev/build_en.html
0 → 100644
此差异已折叠。
doc/howto/dev/new_op_en.html
0 → 100644
此差异已折叠。
doc/howto/dev/use_eigen_en.html
0 → 100644
此差异已折叠。
doc/howto/dev/write_docs_en.html
0 → 100644
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
doc/operators.json
0 → 100644
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
doc_cn/_images/bi_lstm1.jpg
已删除
100644 → 0
{kind=link}
此差异已折叠。
doc_cn/_images/cifar.png
已删除
100644 → 0
{kind=link}
此差异已折叠。
doc_cn/_images/curve.jpg
已删除
100644 → 0
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
doc_cn/_images/feature.jpg
已删除
100644 → 0
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
doc_cn/_images/lenet.png
已删除
100644 → 0
{kind=link}
此差异已折叠。
doc_cn/_images/lstm.png
已删除
100644 → 0
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
doc_cn/_images/paddleci.png
0 → 100644
{kind=link}
此差异已折叠。
doc_cn/_images/parameters.png
已删除
100644 → 0
{kind=link}
此差异已折叠。
doc_cn/_images/plot.png
已删除
100644 → 0
{kind=link}
此差异已折叠。
doc_cn/_images/pprof_1.png
0 → 100644
{kind=link}
此差异已折叠。
doc_cn/_images/pprof_2.png
0 → 100644
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
文件已移动
文件已移动
文件已移动
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
doc_cn/api/v2/data/dataset.html
0 → 100644
此差异已折叠。
此差异已折叠。
doc_cn/api/v2/fluid.html
0 → 100644
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
doc_cn/api/v2/fluid/layers.html
0 → 100644
此差异已折叠。
doc_cn/api/v2/fluid/nets.html
0 → 100644
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
doc_cn/design/block.html
0 → 100644
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
doc_cn/design/evaluator.html
0 → 100644
此差异已折叠。
doc_cn/design/executor.html
0 → 100644
此差异已折叠。
此差异已折叠。
此差异已折叠。
doc_cn/design/float16.html
0 → 100644
此差异已折叠。
此差异已折叠。
doc_cn/design/gan_api.html
0 → 100644
此差异已折叠。
doc_cn/design/graph.html
0 → 100644
此差异已折叠。
doc_cn/design/graph_survey.html
0 → 100644
此差异已折叠。
doc_cn/design/if_else_op.html
0 → 100644
此差异已折叠。
doc_cn/design/infer_var_type.html
0 → 100644
此差异已折叠。
doc_cn/design/model_format.html
0 → 100644
此差异已折叠。
此差异已折叠。
此差异已折叠。
doc_cn/design/ops/rnn.html
0 → 100644
此差异已折叠。
此差异已折叠。
doc_cn/design/optimizer.html
0 → 100644
此差异已折叠。
此差异已折叠。
此差异已折叠。
doc_cn/design/program.html
0 → 100644
此差异已折叠。
doc_cn/design/prune.html
0 → 100644
此差异已折叠。
doc_cn/design/python_api.html
0 → 100644
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
doc_cn/design/regularization.html
0 → 100644
此差异已折叠。
此差异已折叠。
doc_cn/design/scope.html
0 → 100644
此差异已折叠。
doc_cn/design/selected_rows.html
0 → 100644
此差异已折叠。
此差异已折叠。
doc_cn/design/tensor_array.html
0 → 100644
此差异已折叠。
doc_cn/design/var_desc.html
0 → 100644
此差异已折叠。
此差异已折叠。
此差异已折叠。
doc_cn/faq/local/index_cn.html
0 → 100644
此差异已折叠。
doc_cn/faq/model/index_cn.html
0 → 100644
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
doc_cn/howto/dev/build_cn.html
0 → 100644
此差异已折叠。
doc_cn/howto/dev/new_op_cn.html
0 → 100644
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。