remove conflict
Showing
doc/design/fluid-compiler.graffle
0 → 100644
文件已添加
doc/design/fluid-compiler.png
0 → 100644
{kind=link}
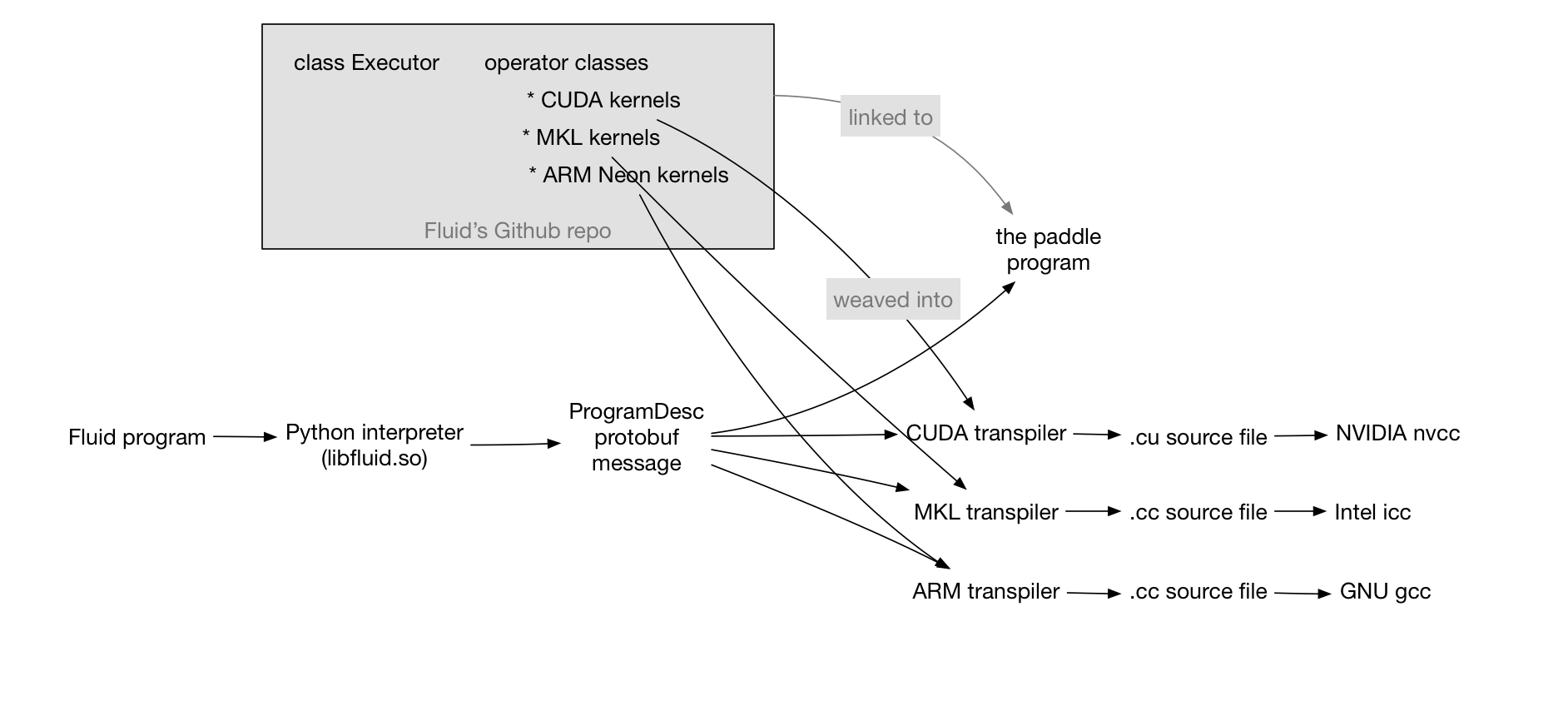
121.2 KB
doc/design/fluid.md
0 → 100644
doc/design/support_new_device.md
0 → 100644
doc/howto/read_source.md
0 → 100644
此差异已折叠。
此差异已折叠。