Skip to content
体验新版
项目
组织
正在加载...
登录
切换导航
打开侧边栏
PaddlePaddle
Paddle
提交
4599aea7
P
Paddle
项目概览
PaddlePaddle
/
Paddle
大约 2 年 前同步成功
通知
2325
Star
20933
Fork
5424
代码
文件
提交
分支
Tags
贡献者
分支图
Diff
Issue
1423
列表
看板
标记
里程碑
合并请求
543
Wiki
0
Wiki
分析
仓库
DevOps
项目成员
Pages
P
Paddle
项目概览
项目概览
详情
发布
仓库
仓库
文件
提交
分支
标签
贡献者
分支图
比较
Issue
1,423
Issue
1,423
列表
看板
标记
里程碑
合并请求
543
合并请求
543
Pages
分析
分析
仓库分析
DevOps
Wiki
0
Wiki
成员
成员
收起侧边栏
关闭侧边栏
动态
分支图
创建新Issue
提交
Issue看板
提交
4599aea7
编写于
11月 21, 2017
作者:
T
tensor-tang
浏览文件
操作
浏览文件
下载
电子邮件补丁
差异文件
polish mkldnn doc
上级
0690cca7
变更
5
隐藏空白更改
内联
并排
Showing
5 changed file
with
127 addition
and
43 deletion
+127
-43
doc/design/mkldnn/README.MD
doc/design/mkldnn/README.MD
+127
-43
doc/design/mkldnn/image/engine.png
doc/design/mkldnn/image/engine.png
+0
-0
doc/design/mkldnn/image/gradients.png
doc/design/mkldnn/image/gradients.png
+0
-0
doc/design/mkldnn/image/layers.png
doc/design/mkldnn/image/layers.png
+0
-0
doc/design/mkldnn/image/matrix.png
doc/design/mkldnn/image/matrix.png
+0
-0
未找到文件。
doc/design/mkldnn/README.MD
浏览文件 @
4599aea7
# Intel® MKL-DNN on PaddlePaddle: Design Doc
我们计划将Intel深度神经网络数学库(
**MKL-DNN**
\[
[
1
](
#references
)
\]
)集成到PaddlePaddle,充分展现英特尔平台的优势,有效提升PaddlePaddle在英特尔架构上的性能。
我们计划将英特尔深度神经网络数学库
[
Intel MKL-DNN
](
https://github.com/01org/mkl-dnn
)
(Intel Math Kernel Library for Deep Neural Networks)集成到PaddlePaddle,
充分展现英特尔平台的优势,有效提升PaddlePaddle在英特尔架构上的性能。
我们短期内的基本目标是:
<div
align=
"center"
>
<img
src=
"image/overview.png"
width=
350
><br/>
Figure 1. PaddlePaddle on IA
</div>
-
完成常用layer的MKL-DNN实现。
近期目标
-
完成常用Layer的MKL-DNN实现。
-
完成常见深度神经网络VGG,GoogLeNet 和 ResNet的MKL-DNN实现。
目前的优化,主要针对PaddlePaddle在重构之前的代码框架以及V1的API。
具体的完成状态可以参见
[
这里
](
https://github.com/PaddlePaddle/Paddle/projects/21
)
。
## Contents
-
[
Overview
](
#overview
)
-
[
Actions
](
#actions
)
-
[
CMake
](
#cmake
)
-
[
Matrix
](
#matrix
)
-
[
Layers
](
#layers
)
-
[
Activations
](
#activations
)
-
[
Weights
](
#weights
)
-
[
Parameters
](
#parameters
)
-
[
Gradients
](
#gradients
)
-
[
Unit Tests
](
#unit-tests
)
-
[
Protobuf Messages
](
#protobuf-messages
)
-
[
Python API
](
#python-api
)
...
...
@@ -26,42 +37,114 @@
## Overview
我们会把MKL-DNN作为第三方库集成进PaddlePaddle,整体框架图
我们会把MKL-DNN会作为第三方库集成进PaddlePaddle,与其他第三方库一样,会在编译PaddlePaddle的时候下载并编译MKL-DNN。
同时,为了进一步提升PaddlePaddle在基本数学运算的计算速度,我们也将MKLML即(MKL small library
\[
[
1
](
#references
)
\]
)
作为另一个第三方库集成进PaddlePaddle,它只会包括生成好的动态库和头文件。
MKLML可以与MKL-DNN共同使用,以此达到最好的性能。
<div
align=
"center"
>
<img
src=
"image/
overview.png"
width=
35
0
><br/>
Figure
1. PaddlePaddle on IA.
<img
src=
"image/
engine.png"
width=
30
0
><br/>
Figure
2. PaddlePaddle with MKL Engines
</div>
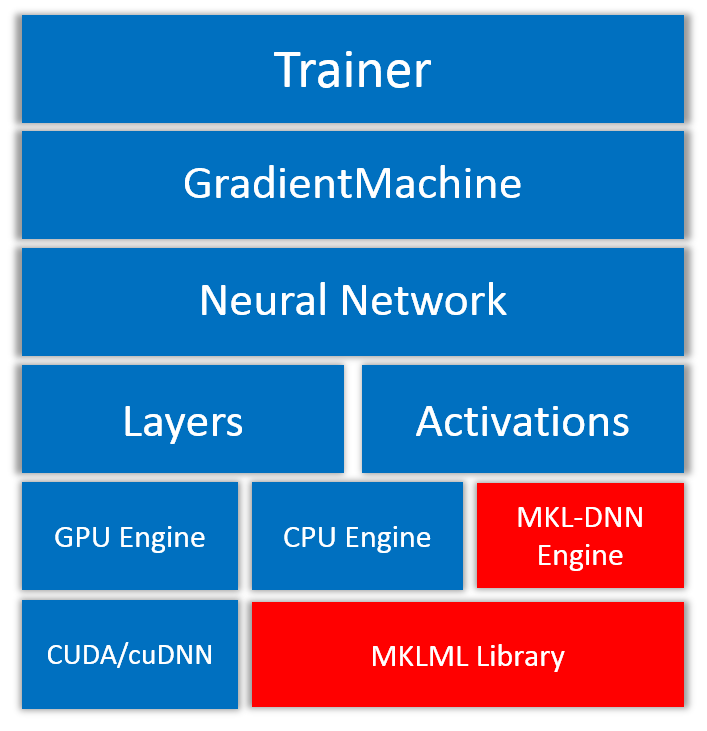
## Actions
我们把集成方案大致分为了如下几个方面。
添加的相关文件和目录结构如下:
```
txt
PaddlePaddle/Paddle
├── ...
├── cmake/
│ ├── external/
│ │ ├── ...
│ │ ├── mkldnn.cmake
│ │ └── mklml.cmake
└── paddle/
├── ...
├── math/
│ ├── ...
│ └── MKLDNNMatrix.*
└── gserver/
├── ...
├── layers/
│ ├── ...
│ └── MKLDNN*Layer.*
├── activations/
│ ├── ...
│ └── MKLDNNActivations.*
└── tests/
├── ...
├── MKLDNNTester.*
└── test_MKLDNN.cpp
```
### CMake
我们会在
`CMakeLists.txt`
中会给用户添加一个
`WITH_MKL`
的开关,他是负责
`WITH_MKLML`
和
`WITH_MKLDNN`
的总开关。
在
`CMakeLists.txt`
中提供一个与MKL有关的总开关:
`WITH_MKL`
,它负责决定编译时是否使用MKLML和MKL-DNN
当打开
`WITH_MKL`
时,会开启MKLML的功能,作为PaddlePaddle的CBLAS和LAPACK库,同时会开启Intel OpenMP用于提高MKLML的性能。 如果系统支持AVX2指令集及以上,同时会开启MKL-DNN功能。
-
`WITH_MKLML`
控制是否使用MKLML库。
当打开
`WITH_MKL`
时,会自动使用MKLML库作为PaddlePaddle的CBLAS和LAPACK库,同时会开启Intel OpenMP用于提高MKLML的性能。
-
`WITH_MKLDNN`
控制是否使用MKL-DNN。
当开启
`WITH_MKL`
时,会自动根据硬件配置
[
[2
](
#references
)
]选择是否编译MKL-DNN。
当关闭
`WITH_MKL`
时,MKLML和MKL-DNN功能会同时关闭。
### Matrix
目前在PaddlePaddle中数据都是以
`nchw`
的格式存储,但是在MKL-DNN中的排列方式不止这一种。
所以我们定义了一个
`MKLDNNMatrix`
用于管理MKL-DNN数据的不同格式以及相互之间的转换。
所以,我们会在
`cmake/external`
目录新建
`mkldnn.cmake`
和
`mklml.cmake`
文件,它们会在编译PaddlePaddle的时候下载对应的软件包,并放到PaddlePaddle的third party目录中。
<div
align=
"center"
>
<img
src=
"image/matrix.png"
width=
400
height=
250
><br/>
Figure 3. MKLDNNMatrix
</div>
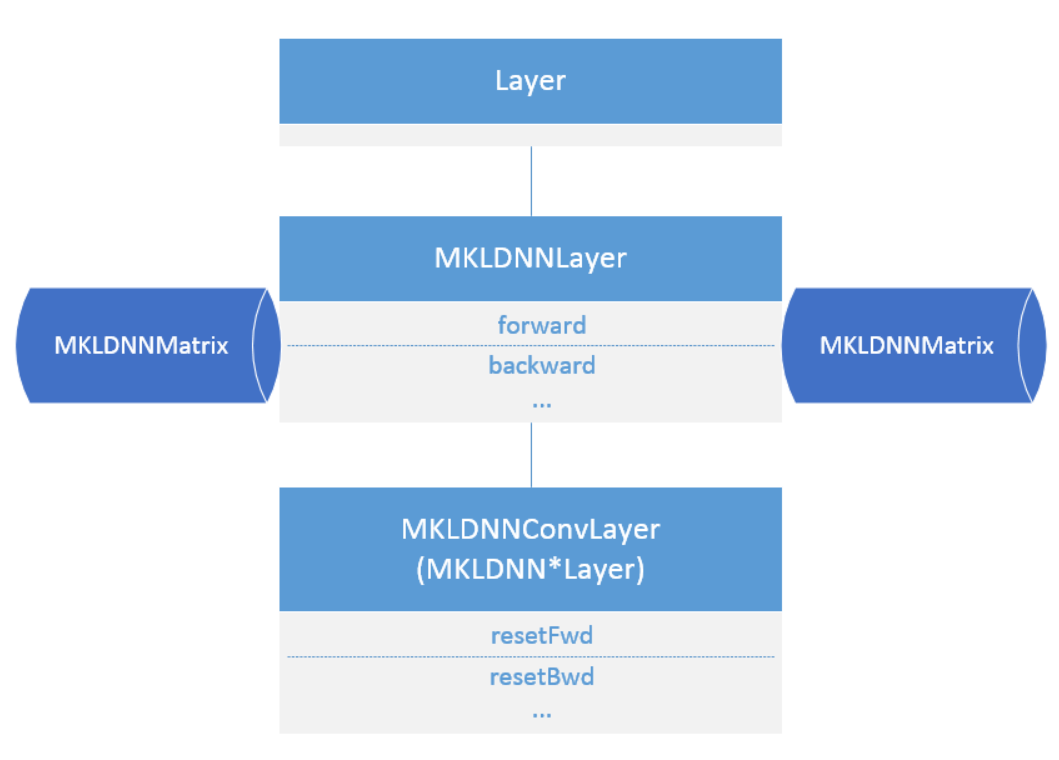
### Layers
所有MKL-DNN相关的C++ layers,都会按照PaddlePaddle的目录结构存放在
`paddle/gserver/layers`
中,并且文件名都会一以
*MKLDNN*
开头。
所有MKL-DNN的Layers都会继承于
`MKLDNNLayer`
,该类继承于PaddlePaddle的基类
`Layer`
。
在
`MKLDNNLayer`
中会提供一些必要的接口和函数,并且会写好
`forward`
和
`backward`
的基本逻辑,
子类只需要使用定义好的接口,实现具体的函数功能即可。
<div
align=
"center"
>
<img
src=
"image/layers.png"
width=
430
><br/>
Figure 4. MKLDNNLayer
</div>
每个
`MKLDNNlayer`
都会有
`inVal_`
,
`inGrad_`
,
`outVal_`
和
`outGrad_`
的
`MKLDNNMatrix`
,
分别代表input value, input gradient,output value和output gradient。
它们会存放MKL-DNN用到的internal memory,同时还会定义以
*ext*
开头的
`MKLDNNMatrix`
(表示external的memory)。
他们主要是当数据格式与PaddlePaddle默认的
`nchw`
格式不匹配时,用于转换内存的工作。
所有MKL-DNN的layers都会继承于一个叫做
`MKLDNNLayer`
的父类,该父类继承于PaddlePaddle的基类
`Layer`
。
必要的转换函数也会在
`MKLDNNLayer`
中提前定义好(具体包括reset input、output的value和grad),
这些函数会根据输入参数重新设置internal和external的memory(当然这两者也可以相等,即表示不需要转换),
每个
`MKLDNNlayer`
的子类只需要使用internal的memory就可以了,所有external的转换工作都会在reset函数中都准备好。
在
`MKLDNNLayer`
中会提供一些必要的接口和函数,并且会写好
`forward`
和
`backward`
的基本逻辑。部分函数定义为纯虚函数,子类只需要实现这些函数即可。
一般来说,每个
`MKLDNNLayer`
中的
`extOutVal_`
和
`extOutGrad_`
必须分别与
`output_.value`
和
`output_.grad`
共享内存,
因为PaddlePaddle的activation会直接使用
`output_.value`
和
`output_.grad`
,
如果不需要external的buffer用于转换,那么internal的buffer也会与它们共享内存。
### Activations
由于在PaddlePaddle中,激活函数是独立于layer概念的,所以会在
`paddle/gserver/activations`
目录下添加
`MKLDNNActivation.h`
和
`MKLDNNActivation.cpp`
文件用于定义和使用MKL-DNN的接口。
在重构前的PaddlePaddle中,激活函数是独立于
`Layer`
的概念,并且输入输出都是公用一块内存,
所以添加了对应的
`MKLDNNActivation`
来实现,方式类似于
`MKLDNNLayer`
。
### Parameters
对于有参数的层,我们会保证
`MKLDNNLayer`
使用的参数与PaddlePaddle申请的buffer公用一块内存。
如果存在数据排列格式不一样的情况时,我们会在网络训练之前把格式转换为MKL-DNN希望的格式,
在训练结束的时候再保存为PaddlePaddle的格式,但是整个训练过程中不需要任何转换。
这样既使得最终保存的参数格式与PaddlePaddle一致,又可以避免不必要的转换。
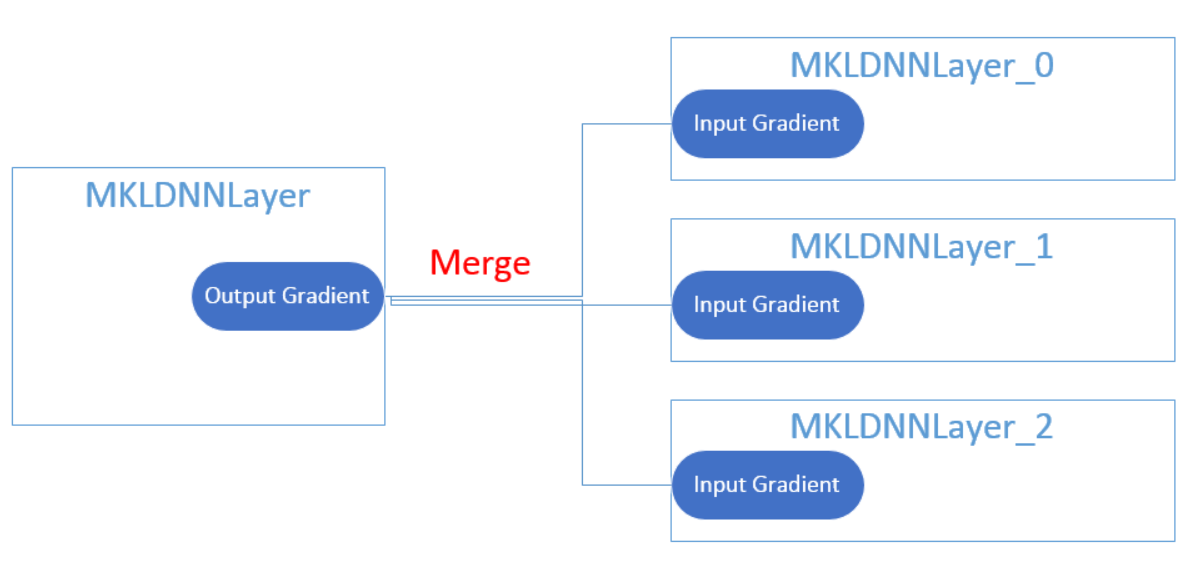
### Gradients
由于MKL-DNN的操作都是直接覆盖的形式,也就是说输出的结果不会在原来的数据上累加,
这样带来的好处就是不需要一直清空memory,节省了不必要的操作。
但是注意的是,当网络出现分支且在
`backward`
的时候,需要累加不同Layer传过来的梯度。
所以在
`MKLDNNlayer`
中实现了一个merge的方法,此时每个小分支的
`Input Gradient`
会先临时保存在
`MKLDNNMatrix`
中,由分支处的Layer负责求和,并把结果放到当前层的
`output_.grad`
中。
所以整体上,在实现每个子类的时候就不需要关心分支的事情了。
### Weights
由于有些layer是含有参数的,我们会尽量让MKL-DNN的参数与PaddlePaddle中
`parameter`
共享一块内存。
同时,由于MKL-DNN在训练时使用的参数layout可能与PaddlePaddle默认的
`nchw`
不一致,我们会在网络训练的开始和结束时分别转换这个layout,使得最终保存的参数格式与PaddlePaddle一致。
<div
align=
"center"
>
<img
src=
"image/gradients.png"
width=
600
height=
300
><br/>
Figure 5. Merge Gradients
</div>
### Unit Tests
会在
`paddle/gserver/test`
目录下
添加
`test_MKLDNN.cpp`
和
`MKLDNNTester.*`
用于MKL-DNN的测试。
测试分为每个
layer(或a
ctivation)的单元测试和简单网络的整体测试。
我们会
添加
`test_MKLDNN.cpp`
和
`MKLDNNTester.*`
用于MKL-DNN的测试。
测试分为每个
Layer(或A
ctivation)的单元测试和简单网络的整体测试。
每个测试会对比PaddlePaddle中CPU算出的结果与MKL-DNN的结果,小于某个比较小的阈值认为通过。
### Protobuf Messages
...
...
@@ -80,41 +163,42 @@ if use_mkldnn
self
.
layer_type
=
mkldnn_
*
```
所有MKL-DNN的
layer type会以
*mkldnn_*
开头
,以示区分。
所有MKL-DNN的
`layer_type`
会以
*mkldnn_*
开头,这些会在
`MKLDNN*Layer`
注册layer的时候保证
,以示区分。
并且可能在
`python/paddle/trainer_config_helper`
目录下的
`activations.py `
和
`layers.py`
里面添加必要的MKL-DNN的接口
。
同时,会在
`paddle/utils.Flags`
中添加一个
`use_mkldnn`
的flag,用于选择是否使用MKL-DNN的相关功能
。
### Demos
会在
`v1_api_demo`
目录下添加一个
`mkldnn`
的文件夹,里面放入一些用于MKL-DNN测试的demo脚本。
可能会在
`v1_api_demo`
目录下添加一个
`mkldnn`
的文件夹,里面放入一些用于MKL-DNN测试的demo脚本。
### Benchmarking
会添加
`benchmark/paddle/image/run_mkldnn.sh`
,用于测试
使用MKL-DNN之
后的性能。
会添加
`benchmark/paddle/image/run_mkldnn.sh`
,用于测试
和对比,在使用MKL-DNN前
后的性能。
### Others
1.
如果在使用MKL-DNN的情况下,会把CPU的Buffer对齐为
64
。
1.
如果在使用MKL-DNN的情况下,会把CPU的Buffer对齐为
4096,具体可以参考MKL-DNN中的
[
memory
](
https://github.com/01org/mkl-dnn/blob/master/include/mkldnn.hpp#L673
)
。
2.
深入PaddlePaddle,寻找有没有其他可以优化的可能,进一步优化。比如可能会用OpenMP改进SGD的更新性能。
## Design Concerns
为了更好的符合PaddlePaddle的代码风格
\[
[
2
](
#references
)
\]
,同时又尽可能少的牺牲MKL-DNN的性能
\[
[
3
](
#references
)
\]
。
为了更好的符合PaddlePaddle的代码风格
\[
[
3
](
#references
)
\]
,同时又尽可能少的牺牲MKL-DNN的性能
\[
[
4
](
#references
)
\]
。
我们总结出一些特别需要注意的点:
1.
使用
**deviceId_**
。为了尽可能少的在父类Layer中添加变量或者函数,我们决定使用已有的
`deviceId_`
变量来区分layer的属性,定义
`-2`
为
`MKLDNNLayer`
特有的设备ID。
2.
重写父类Layer的
**init**
函数,修改
`deviceId_`
为
`-2`
,代表这个layer是用于跑在MKL-DNN的环境下。
3.
创建
`MKLDNNMatrix`
,同时继承
`CpuMatrix`
和
`mkldnn::memory`
。用于管理MKL-DNN会用到的相关memory函数、接口以及会用的到格式信息。
4.
创建
`MKLDNNBase`
,定义一些除了layer和memory相关的类和函数。包括MKL-DNN会用到
`MKLDNNStream`
和
`CPUEngine`
,和未来可能还会用到
`FPGAEngine`
等。
5.
每个
`MKLDNNlayer`
都会有
`inVal_`
,
`inGrad_`
,
`outVal_`
和
`outGrad_`
,分别代表input value, input gradient,output value和output gradient。他们会存放MKL-DNN用到的internal memory。同时还会定义以
*ext*
开头的
`MKLDNNMatrix`
(表示external的memory),主要是在格式与PaddlePaddle默认的
`nchw`
格式不匹配时,用于转换内存的工作。必要的转换函数也会在
`MKLDNNLayer`
中提前定义好,每个子类只需要调用定义好的reset buffer函数即可。
6.
每个
`MKLDNNlayer`
的resetbuffer相关的函数(包括reset input、output的Value和grad),他们会根据输入参数reset internal和external的memory,当然这两者也可以相等,即表示不需要转换。只需要把握一个原则,每个
`MKLDNNlayer`
的子类,只需要使用internal的memory就可以了,所有external的转换工作在父类的reset函数中都提前准备好了。
7.
一般来说,external的memory会尽量与PaddlePaddle中的
`value`
和
`grad`
共享内存。同时每个
`MKLDNNLayer`
中的external output value和gradient(也就是
`extOutVal_`
和
`extOutGrad_`
)必须分别与
`output_.value`
和
`output_.grad`
共享内存,因为PaddlePaddle的activation会直接使用
`output_.value`
和
`output_.grad`
。如果不需要external的buffer用于转换,那么internal的buffer也会与他们共享内存。
8.
如果MKL-DNN layer的后面接有cpu device,那么就会使
`output_.value`
与
`extOutVal_`
共享内存,同时数据格式就是
`nchw`
,这样下一个cpu device就能拿到正确的数据。在有cpu device的时候,external的memory的格式始终是
`nchw`
或者
`nc`
。
9.
由于MKL-DNN的输出操作都是覆盖data的,不是在原来的数据上累加,所以当网络出现分支时,在
`backward`
时会需要merge不同layer的梯度。
`MKLDNNlayer`
中会实现merge的方法,此时每个小分支的input gradient会先临时保存在一个
`MKLDNNMatrix`
中,由分支处的layer负责求和,并把结果放到这个layer的
`output_.grad`
中。所以整体上,每个子类并不会需要关心分支的事情,也是在父类都实现好了。
10.
在原来的
`FLAGS`
中添加一个
`use_mkldnn`
的flag,用于选择是否使用MKL-DNN的相关功能。
1.
使用
**deviceId_**
。为了尽可能少的在父类Layer中添加变量或者函数,
我们决定使用已有的
`deviceId_`
变量来区分layer的属性,定义
`-2`
为
`MKLDNNLayer`
特有的设备ID。
2.
重写父类Layer的
**init**
函数,修改
`deviceId_`
为
`-2`
,代表这个layer是用于跑在MKL-DNN的环境下。
3.
创建
`MKLDNNBase`
,定义一些除了layer和memory相关的类和函数。
包括MKL-DNN会用到
`MKLDNNStream`
和
`CPUEngine`
,和未来可能还会用到
`FPGAEngine`
等。
4.
如果MKL-DNN layer的后面接有cpu device,那么就会使
`output_.value`
与
`extOutVal_`
共享内存,
同时数据格式就是
`nchw`
,这样下一个cpu device就能拿到正确的数据。
在有cpu device的时候,external的memory的格式始终是
`nchw`
或者
`nc`
。
## References
1.
[
Intel Math Kernel Library for Deep Neural Networks (Intel MKL-DNN)
](
https://github.com/01org/mkl-dnn
"Intel MKL-DNN"
)
2.
[
原来的方案
](
https://github.com/PaddlePaddle/Paddle/pull/3096
)
会引入
**nextLayer**
的信息。但是在PaddlePaddle中,无论是重构前的layer还是重构后的op,都不会想要知道next layer/op的信息。
3.
MKL-DNN的高性能格式与PaddlePaddle原有的
`NCHW`
不同(PaddlePaddle中的CUDNN部分使用的也是
`NCHW`
,所以不存在这个问题),所以需要引入一个转换方法,并且只需要在必要的时候转换这种格式,才能更好的发挥MKL-DNN的性能。
1.
[
MKL small library
](
https://github.com/01org/mkl-dnn#linking-your-application
)
是
[
Intel MKL
](
https://software.intel.com/en-us/mkl
)
的一个子集。
主要包括了深度学习相关的数学原语与操作,一般由MKL-DNN在发布
[
新版本
](
https://github.com/01org/mkl-dnn/releases
)
时一起更新。
2.
[
MKL-DNN System Requirements
](
https://github.com/01org/mkl-dnn#system-requirements
)
。
目前在PaddlePaddle中,仅会在支持AVX2指令集及以上的机器才使用MKL-DNN。
3.
[
原来的方案
](
https://github.com/PaddlePaddle/Paddle/pull/3096
)
会引入
**nextLayer**
的信息。
但是在PaddlePaddle中,无论是重构前的layer还是重构后的op,都不会想要知道next layer/op的信息。
4.
MKL-DNN的高性能格式与PaddlePaddle原有的
`NCHW`
不同(PaddlePaddle中的cuDNN部分使用的也是
`NCHW`
,所以不存在这个问题)。
所以需要引入一个转换方法,并且只需要在必要的时候转换这种格式,才能更好的发挥MKL-DNN的性能。
doc/design/mkldnn/image/engine.png
0 → 100644
浏览文件 @
4599aea7
35.3 KB
doc/design/mkldnn/image/gradients.png
0 → 100644
浏览文件 @
4599aea7
56.1 KB
doc/design/mkldnn/image/layers.png
0 → 100644
浏览文件 @
4599aea7
55.7 KB
doc/design/mkldnn/image/matrix.png
0 → 100644
浏览文件 @
4599aea7
19.3 KB
编辑
预览
Markdown
is supported
0%
请重试
或
添加新附件
.
添加附件
取消
You are about to add
0
people
to the discussion. Proceed with caution.
先完成此消息的编辑!
取消
想要评论请
注册
或
登录
{kind=link}
{kind=link}
{kind=link}
{kind=link}
