add sparse update section in fluid dist doc (#8997)
* add sparse update section in fluid dist doc * update by comment * update * update by comment
Showing
文件已移动
文件已移动
{kind=link}
文件已移动
文件已移动
{kind=link}
文件已移动
文件已移动
{kind=link}
文件已移动
文件已移动
{kind=link}
文件已移动
文件已移动
{kind=link}
文件已移动
文件已移动
{kind=link}
文件已移动
{kind=link}
文件已移动
文件已移动
{kind=link}
文件已移动
文件已移动
{kind=link}
文件已移动
文件已添加
{kind=link}
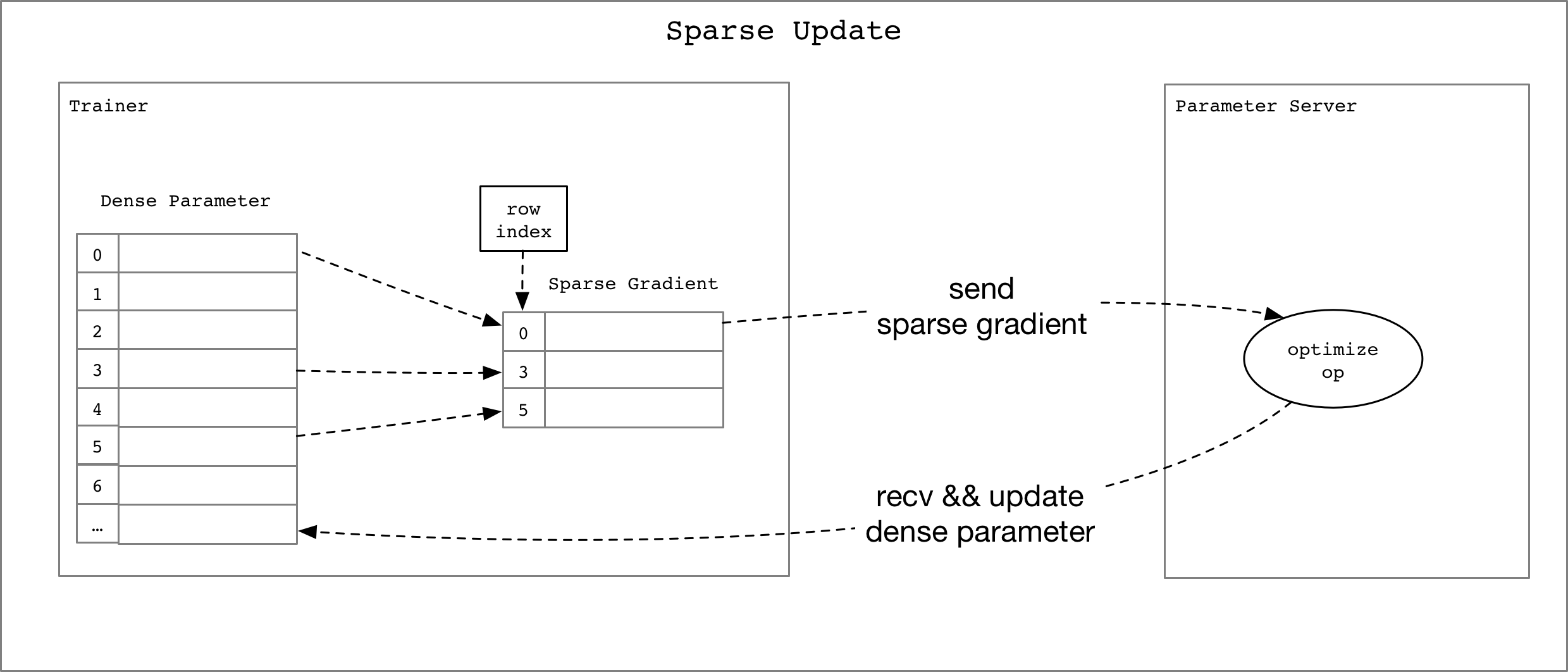
119.7 KB