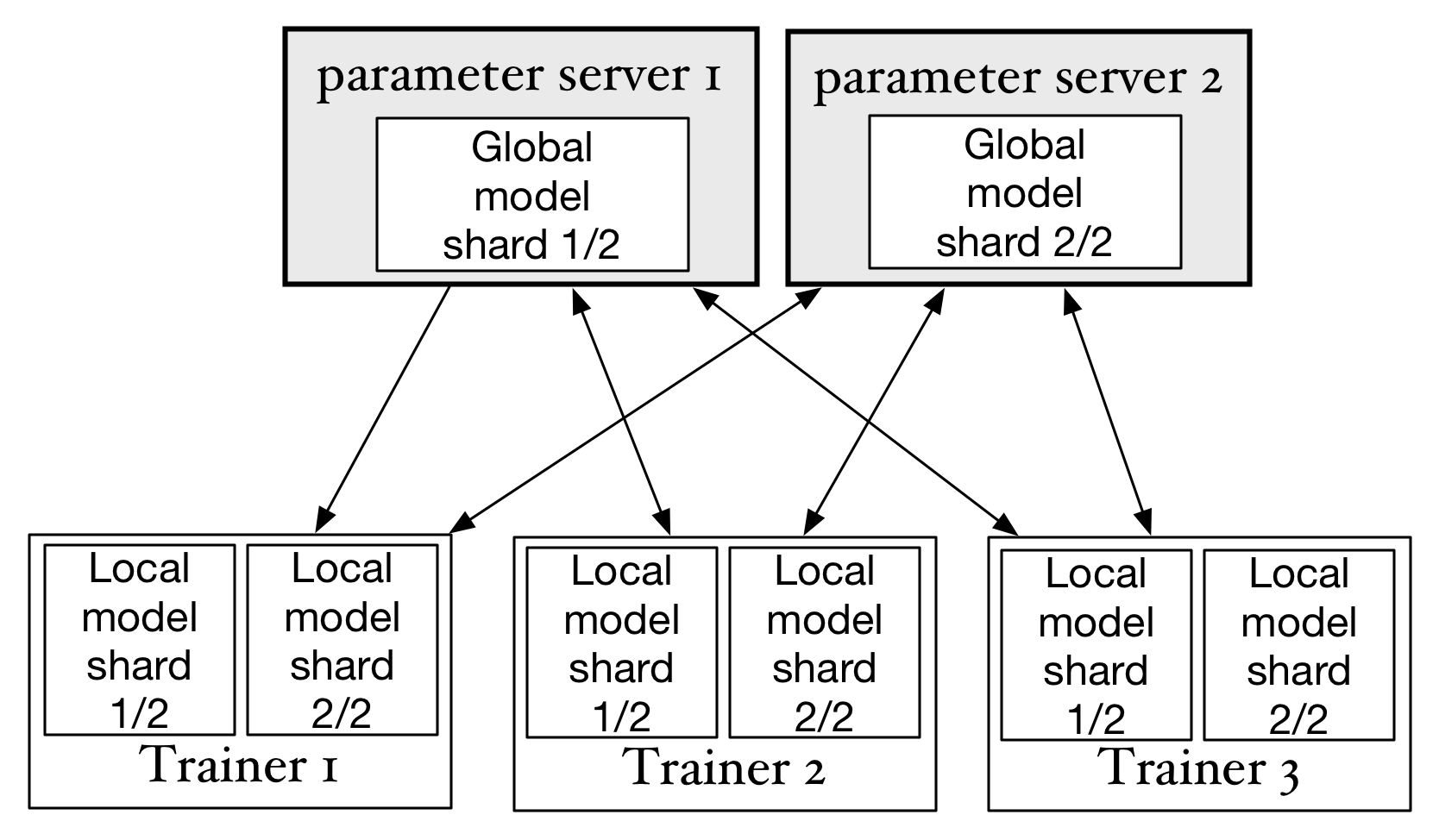
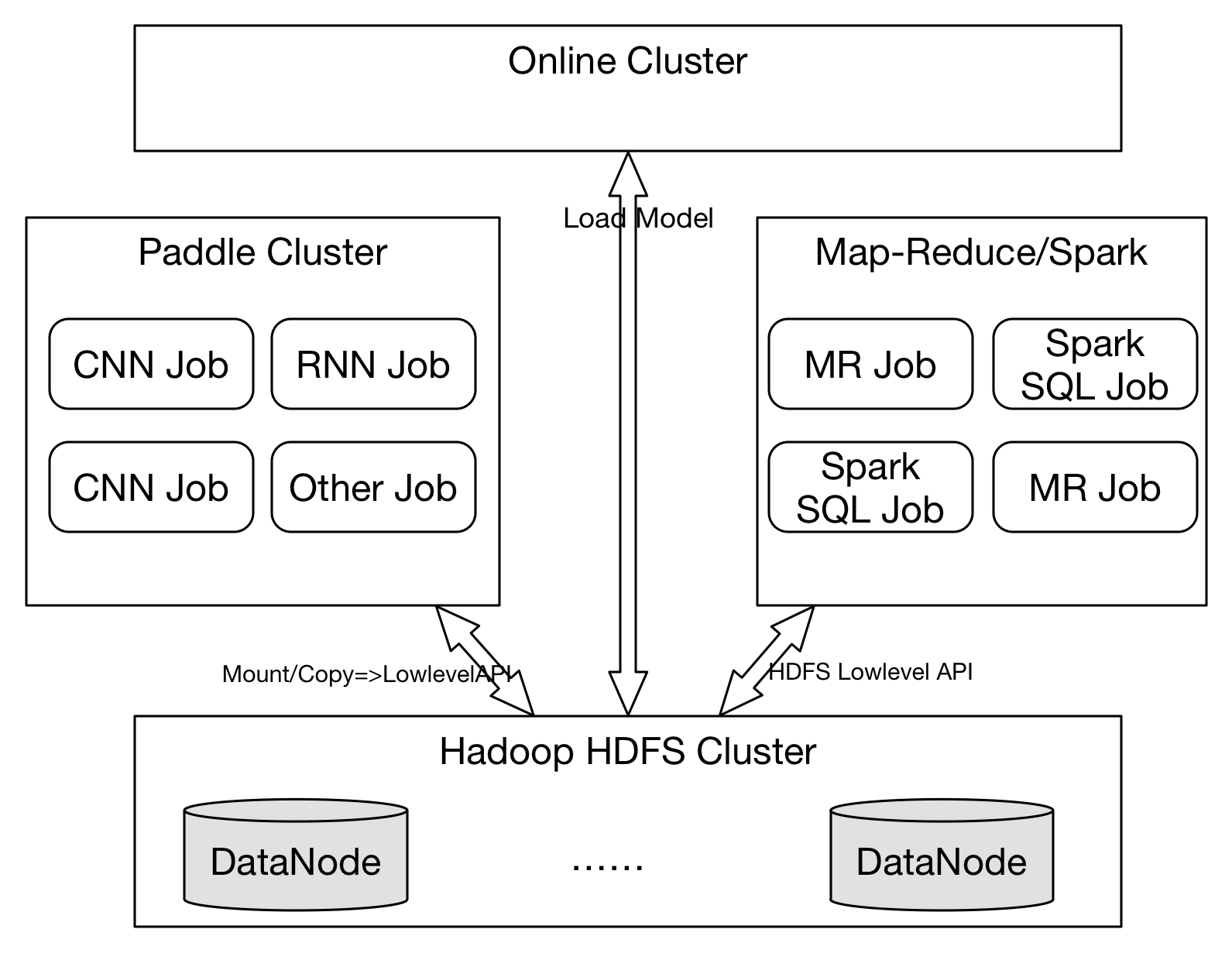
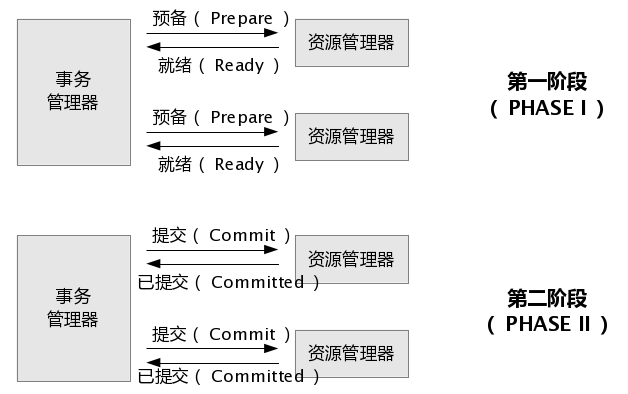
cluster design and thoughts
Showing
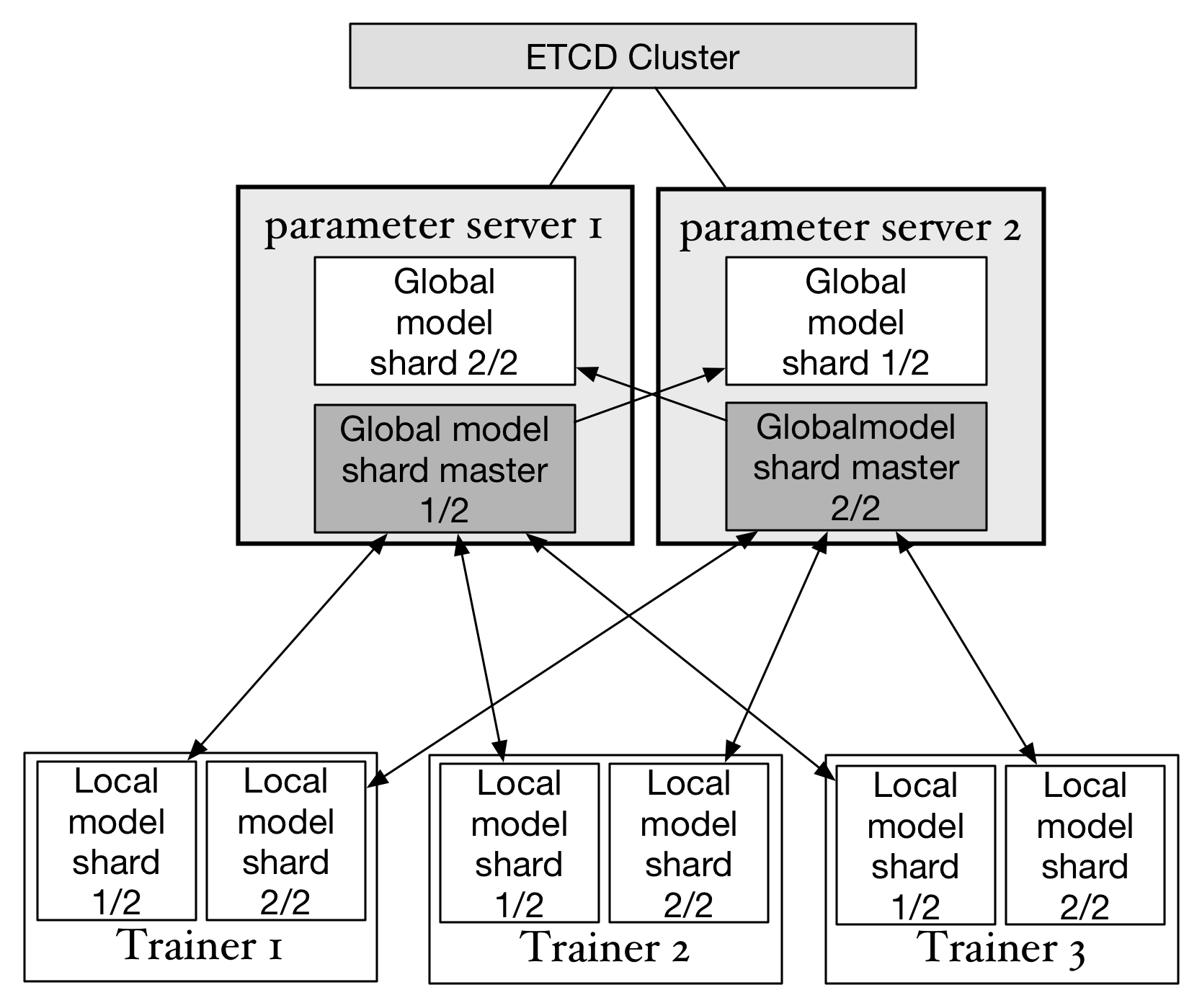
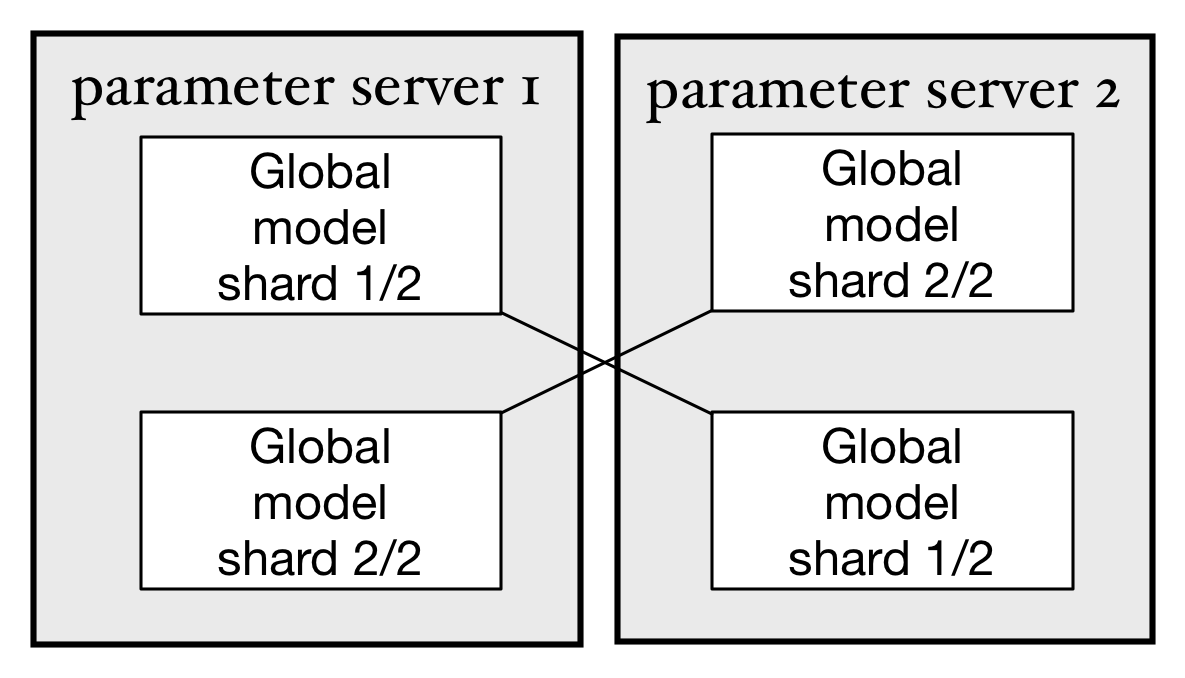
doc/design/images/arch.png
0 → 100644
{kind=link}
161.2 KB
{kind=link}
59.7 KB
{kind=link}
31.8 KB
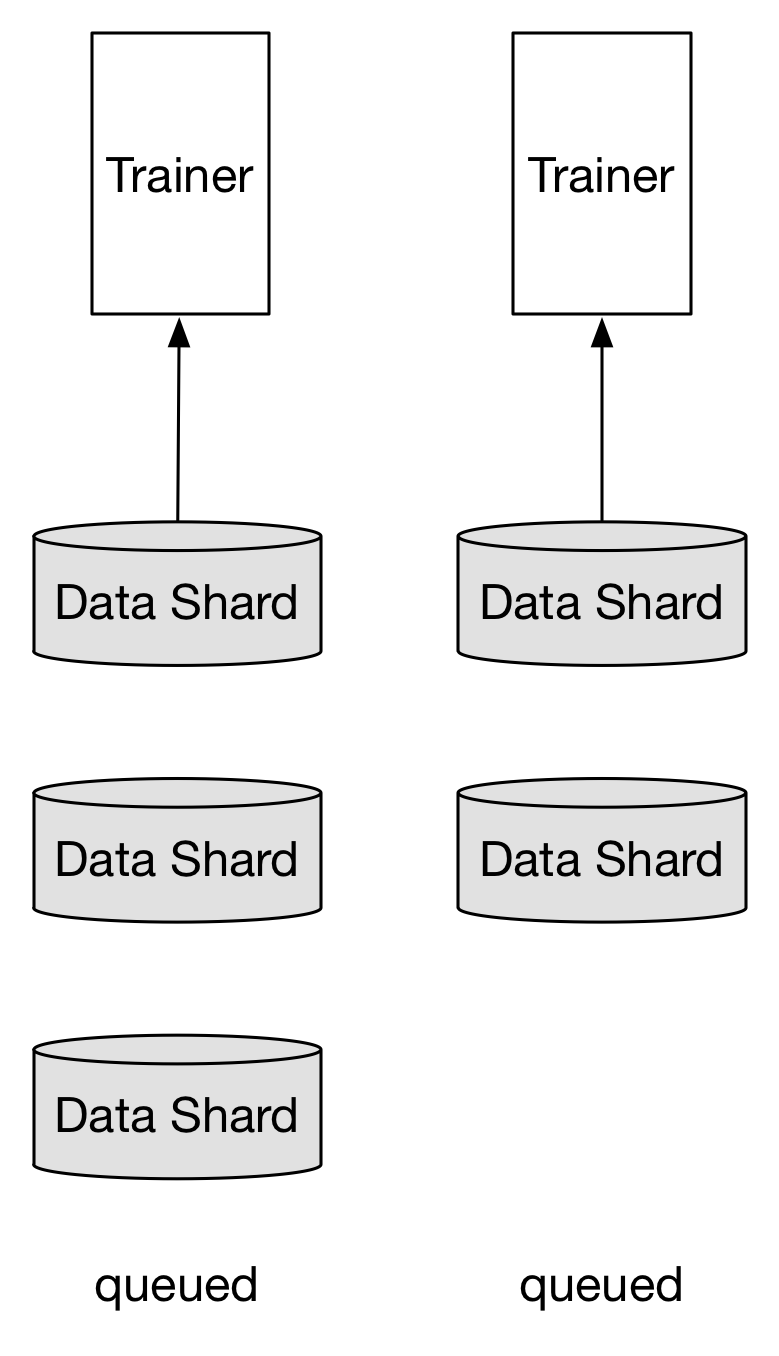
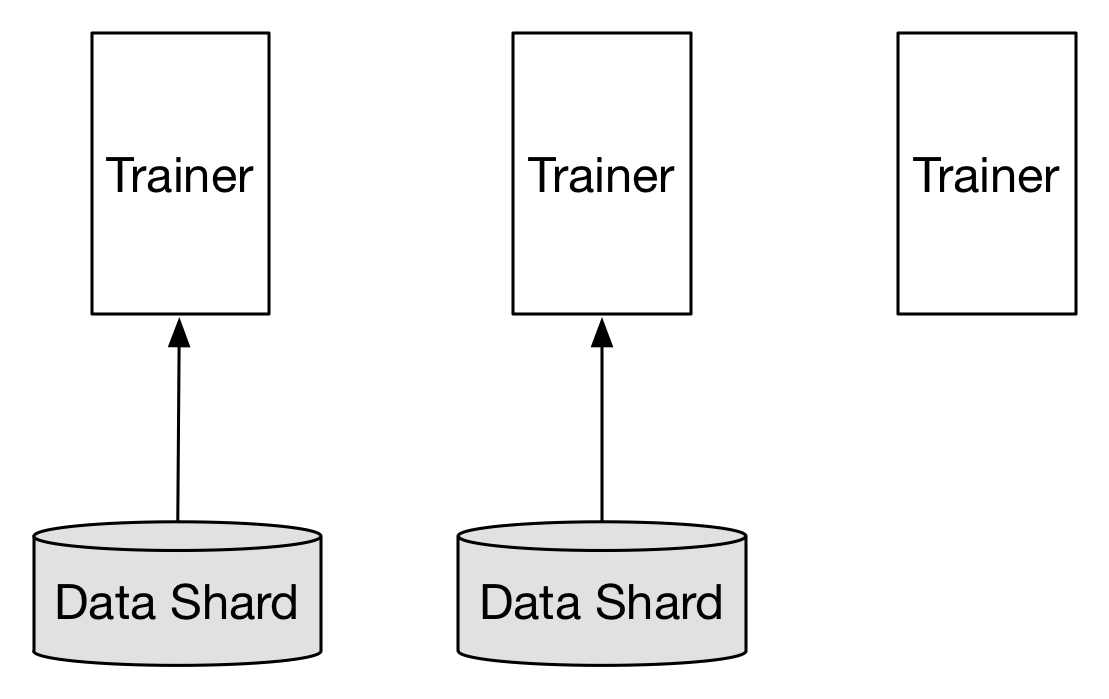
doc/design/images/replica.png
0 → 100644
{kind=link}
58.2 KB
doc/design/images/trainer.graffle
0 → 100644
文件已添加
doc/design/images/trainer.png
0 → 100644
{kind=link}
116.9 KB
{kind=link}
134.9 KB
{kind=link}
48.0 KB