Merge branch 'gh-pages' of github.com:baidu/Paddle into gh-pages
Showing
develop/doc/.buildinfo
0 → 100644
{kind=link}

49.7 KB
{kind=link}
53.0 KB
{kind=link}
57.7 KB
develop/doc/_images/NetLR_en.png
0 → 100644
{kind=link}
48.3 KB
develop/doc/_images/NetRNN_en.png
0 → 100644
{kind=link}
55.8 KB
{kind=link}

7.3 KB
{kind=link}

8.5 KB
{kind=link}

8.6 KB
{kind=link}

11.4 KB
{kind=link}
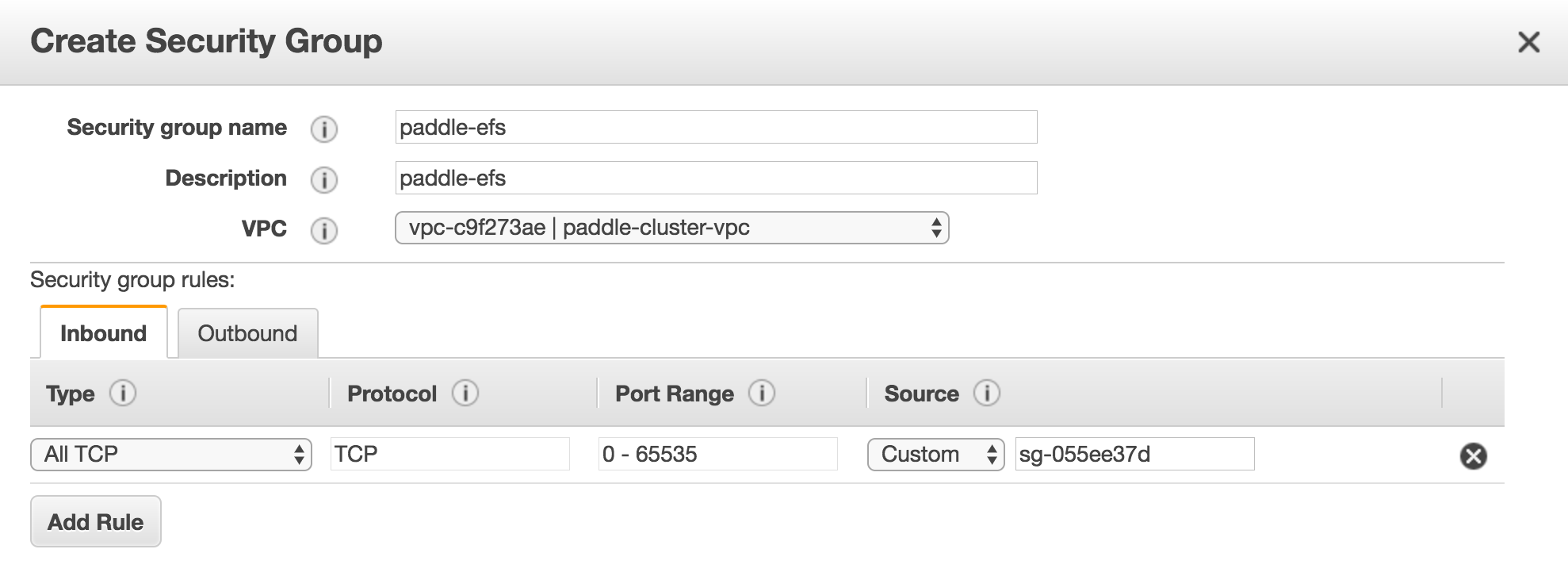
116.2 KB
develop/doc/_images/bi_lstm.jpg
0 → 100644
{kind=link}
34.8 KB
develop/doc/_images/bi_lstm1.jpg
0 → 100644
{kind=link}
34.8 KB
develop/doc/_images/cifar.png
0 → 100644
{kind=link}

455.6 KB
{kind=link}
236.1 KB
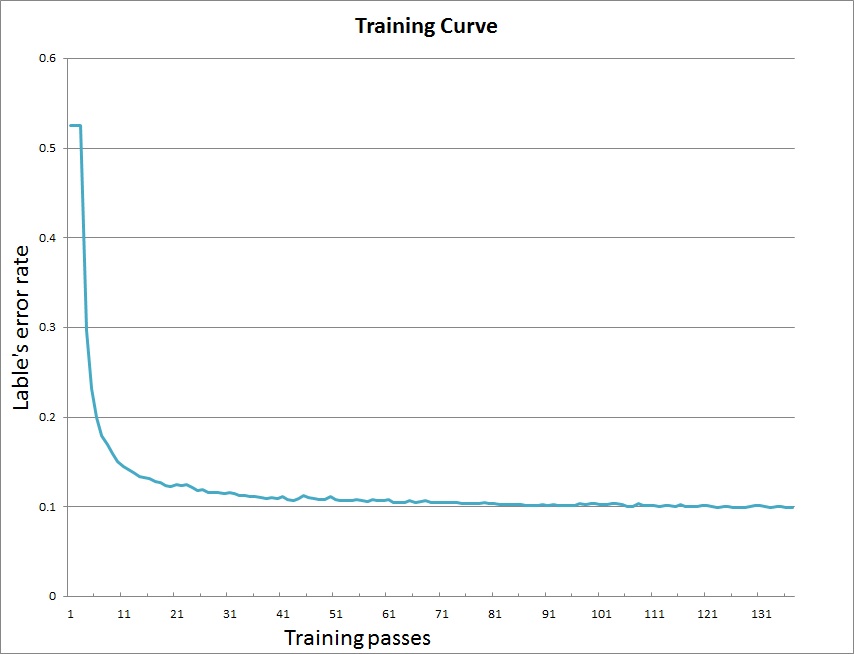
develop/doc/_images/curve.jpg
0 → 100644
{kind=link}
52.0 KB
{kind=link}
66.5 KB
{kind=link}
66.5 KB
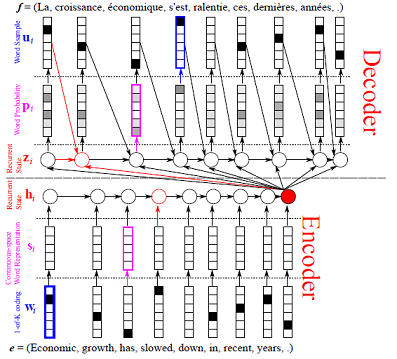
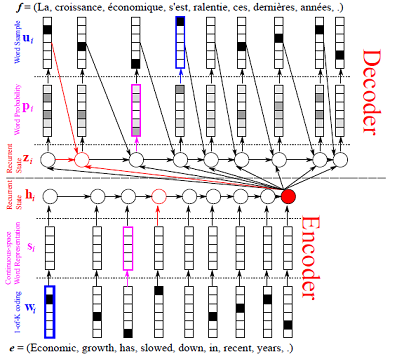
develop/doc/_images/feature.jpg
0 → 100644
{kind=link}
30.5 KB
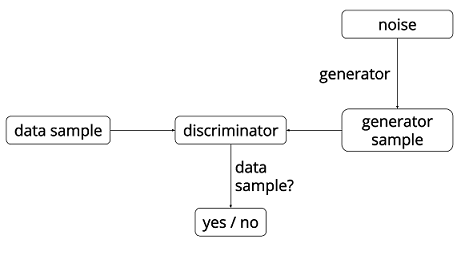
develop/doc/_images/gan.png
0 → 100644
{kind=link}
17.4 KB
{kind=link}
51.4 KB
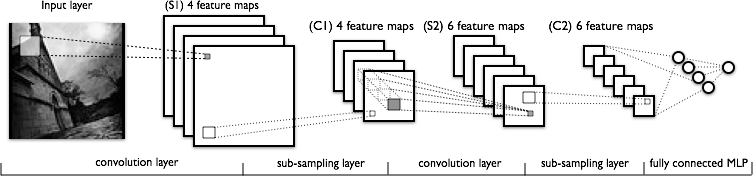
develop/doc/_images/lenet.png
0 → 100644
{kind=link}
48.7 KB
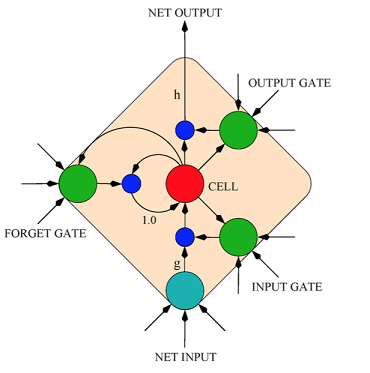
develop/doc/_images/lstm.png
0 → 100644
{kind=link}
49.5 KB
{kind=link}

28.0 KB
{kind=link}
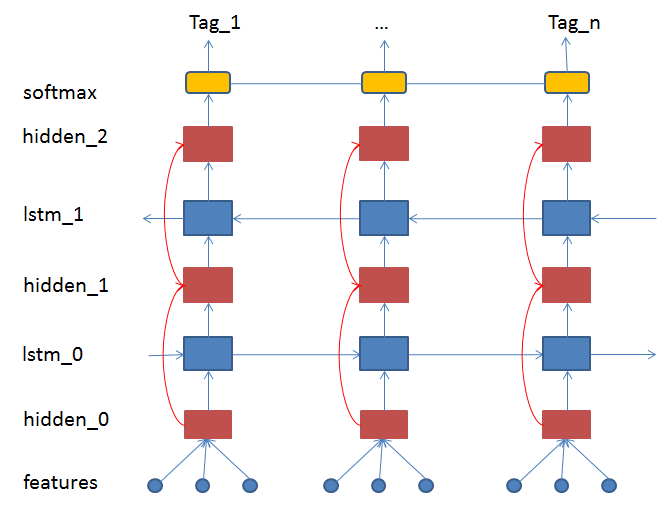
27.2 KB
{kind=link}
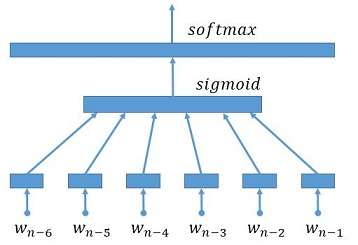
66.9 KB
develop/doc/_images/nvvp1.png
0 → 100644
{kind=link}
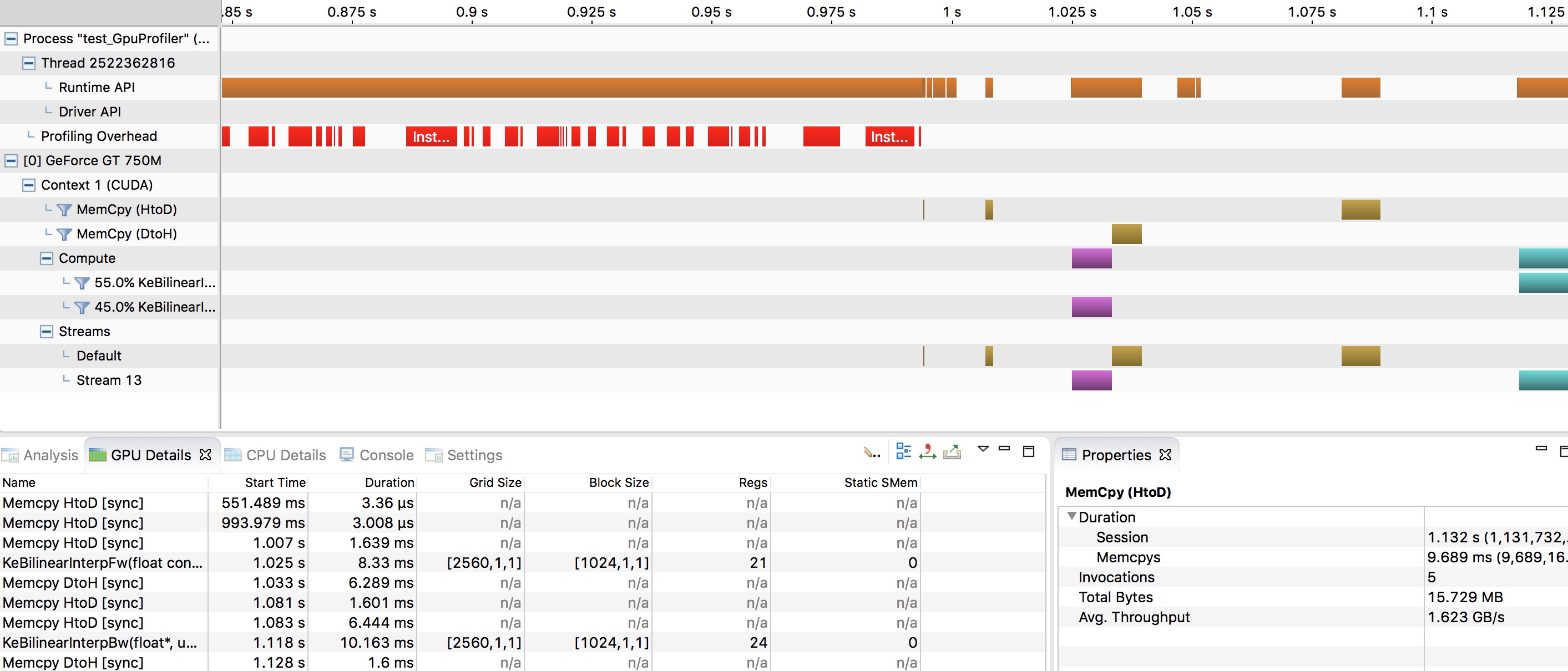
416.1 KB
develop/doc/_images/nvvp2.png
0 → 100644
{kind=link}
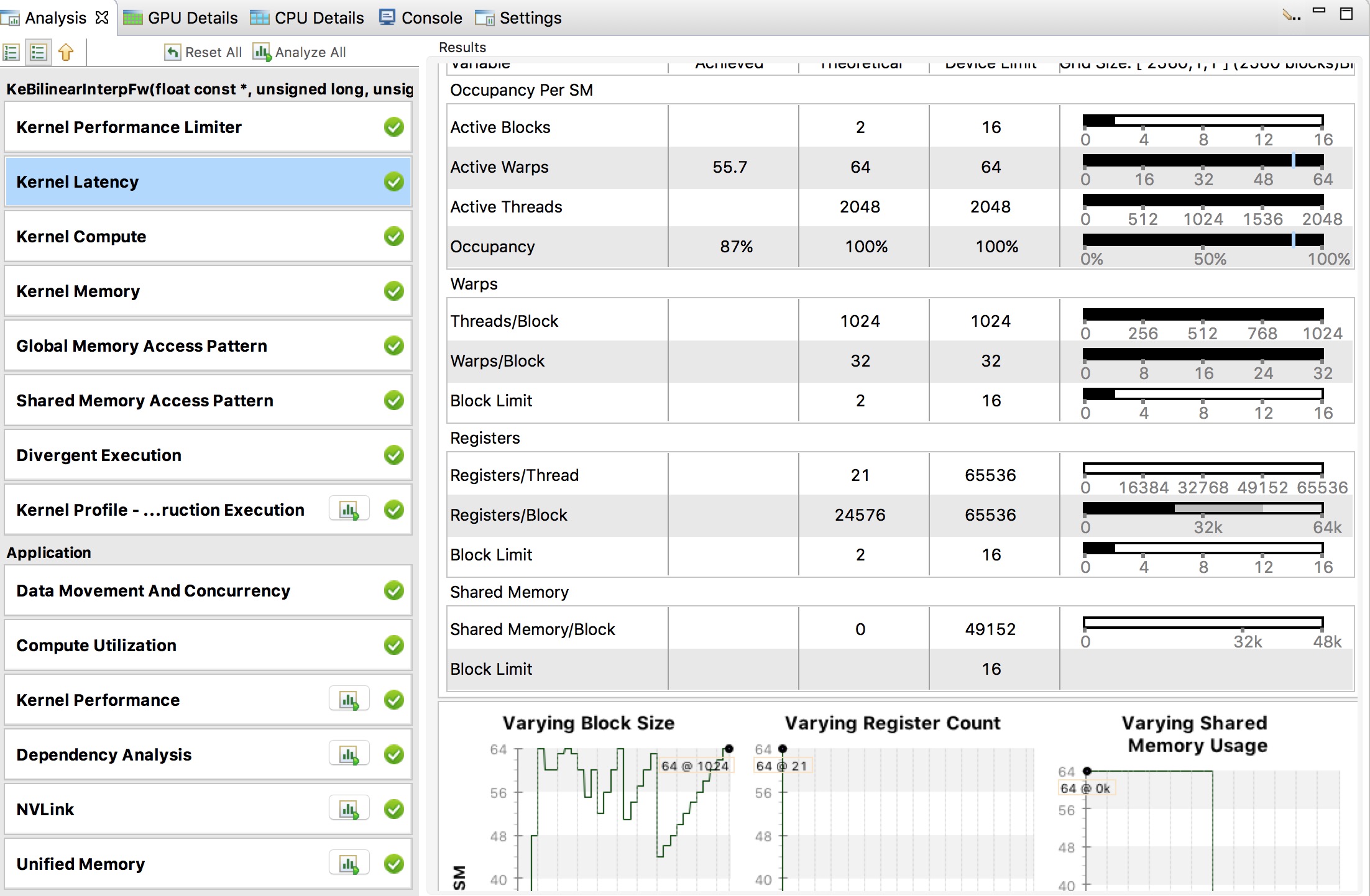
483.5 KB
develop/doc/_images/nvvp3.png
0 → 100644
{kind=link}
247.8 KB
develop/doc/_images/nvvp4.png
0 → 100644
{kind=link}

276.6 KB
{kind=link}
43.4 KB
develop/doc/_images/plot.png
0 → 100644
{kind=link}
30.3 KB
{kind=link}
70.0 KB
{kind=link}
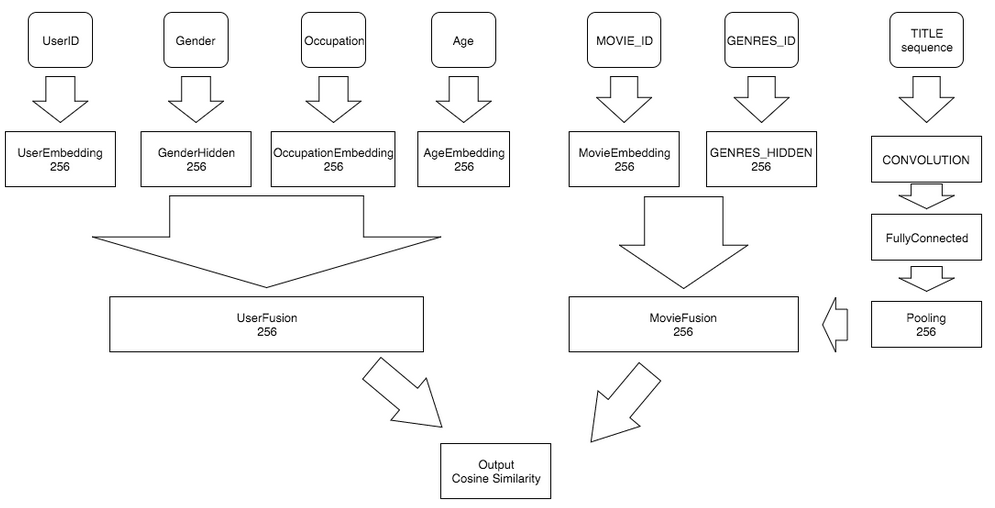
81.2 KB
{kind=link}
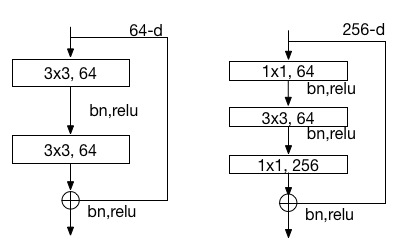
21.9 KB
{kind=link}

34.9 KB
{kind=link}
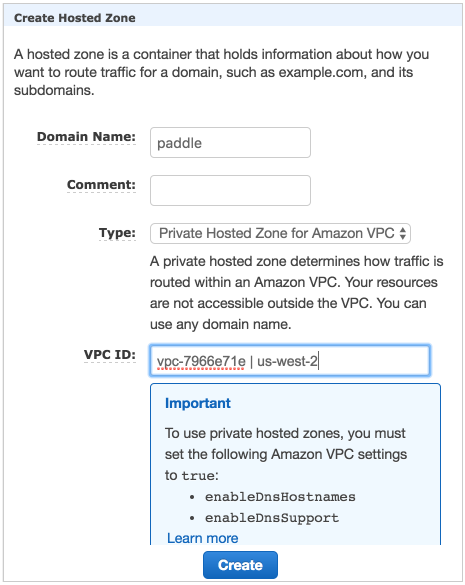
50.8 KB
{kind=link}
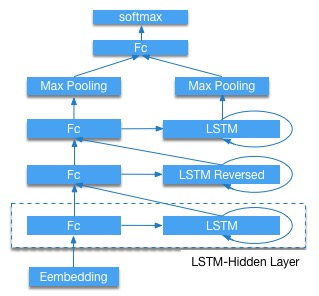
30.3 KB
{kind=link}
24.3 KB
{kind=link}

87.1 KB
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
{kind=link}
673 字节
develop/doc/_static/basic.css
0 → 100644
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
develop/doc/_static/comment.png
0 → 100644
{kind=link}
此差异已折叠。
此差异已折叠。
此差异已折叠。
develop/doc/_static/css/theme.css
0 → 100644
此差异已折叠。
develop/doc/_static/doctools.js
0 → 100644
此差异已折叠。
{kind=link}
此差异已折叠。
develop/doc/_static/down.png
0 → 100644
{kind=link}
此差异已折叠。
develop/doc/_static/file.png
0 → 100644
{kind=link}
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
{kind=link}
此差异已折叠。
此差异已折叠。
此差异已折叠。
{kind=link}
此差异已折叠。
此差异已折叠。
develop/doc/_static/jquery.js
0 → 100644
此差异已折叠。
此差异已折叠。
此差异已折叠。
develop/doc/_static/js/theme.js
0 → 100644
此差异已折叠。
develop/doc/_static/minus.png
0 → 100644
{kind=link}
此差异已折叠。
develop/doc/_static/plus.png
0 → 100644
{kind=link}
此差异已折叠。
develop/doc/_static/pygments.css
0 → 100644
此差异已折叠。
此差异已折叠。
此差异已折叠。
develop/doc/_static/underscore.js
0 → 100644
此差异已折叠。
{kind=link}
此差异已折叠。
develop/doc/_static/up.png
0 → 100644
{kind=link}
此差异已折叠。
develop/doc/_static/websupport.js
0 → 100644
此差异已折叠。
develop/doc/about/index_en.html
0 → 100644
此差异已折叠。
develop/doc/api/index_en.html
0 → 100644
此差异已折叠。
此差异已折叠。
此差异已折叠。
develop/doc/api/v1/index_en.html
0 → 100644
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
develop/doc/api/v2/data.html
0 → 100644
此差异已折叠。
此差异已折叠。
develop/doc/api/v2/run_logic.html
0 → 100644
此差异已折叠。
develop/doc/design/api.html
0 → 100644
此差异已折叠。
此差异已折叠。
develop/doc/genindex.html
0 → 100644
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
develop/doc/howto/index_en.html
0 → 100644
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
develop/doc/index.html
0 → 120000
此差异已折叠。
develop/doc/index_en.html
0 → 100644
此差异已折叠。
develop/doc/objects.inv
0 → 100644
此差异已折叠。
develop/doc/py-modindex.html
0 → 100644
此差异已折叠。
develop/doc/search.html
0 → 100644
此差异已折叠。
develop/doc/searchindex.js
0 → 100644
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
develop/doc_cn/.buildinfo
0 → 100644
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
develop/doc_cn/_images/cifar.png
0 → 100644
{kind=link}
此差异已折叠。
develop/doc_cn/_images/curve.jpg
0 → 100644
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
develop/doc_cn/_images/lenet.png
0 → 100644
{kind=link}
此差异已折叠。
develop/doc_cn/_images/lstm.png
0 → 100644
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
develop/doc_cn/_images/nvvp1.png
0 → 100644
{kind=link}
此差异已折叠。
develop/doc_cn/_images/nvvp2.png
0 → 100644
{kind=link}
此差异已折叠。
develop/doc_cn/_images/nvvp3.png
0 → 100644
{kind=link}
此差异已折叠。
develop/doc_cn/_images/nvvp4.png
0 → 100644
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
develop/doc_cn/_images/plot.png
0 → 100644
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
{kind=link}
此差异已折叠。
develop/doc_cn/_static/basic.css
0 → 100644
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
{kind=link}
此差异已折叠。
develop/doc_cn/_static/down.png
0 → 100644
{kind=link}
此差异已折叠。
develop/doc_cn/_static/file.png
0 → 100644
{kind=link}
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
{kind=link}
此差异已折叠。
此差异已折叠。
此差异已折叠。
{kind=link}
此差异已折叠。
此差异已折叠。
develop/doc_cn/_static/jquery.js
0 → 100644
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
develop/doc_cn/_static/minus.png
0 → 100644
{kind=link}
此差异已折叠。
develop/doc_cn/_static/plus.png
0 → 100644
{kind=link}
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
{kind=link}
此差异已折叠。
develop/doc_cn/_static/up.png
0 → 100644
{kind=link}
此差异已折叠。
此差异已折叠。
此差异已折叠。
develop/doc_cn/api/index_cn.html
0 → 100644
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
develop/doc_cn/api/v2/data.html
0 → 100644
此差异已折叠。
此差异已折叠。
此差异已折叠。
develop/doc_cn/design/api.html
0 → 100644
此差异已折叠。
此差异已折叠。
develop/doc_cn/faq/index_cn.html
0 → 100644
此差异已折叠。
develop/doc_cn/genindex.html
0 → 100644
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
develop/doc_cn/index.html
0 → 120000
此差异已折叠。
develop/doc_cn/index_cn.html
0 → 100644
此差异已折叠。
develop/doc_cn/objects.inv
0 → 100644
此差异已折叠。
develop/doc_cn/py-modindex.html
0 → 100644
此差异已折叠。
develop/doc_cn/search.html
0 → 100644
此差异已折叠。
develop/doc_cn/searchindex.js
0 → 100644
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。