[](https://gitter.im/PaddlePaddle/Deep_Learning?utm_source=badge&utm_medium=badge&utm_campaign=pr-badge&utm_content=badge)
Semantic role labeling (SRL) is a form of shallow semantic parsing whose goal is to discover the predicate-argument structure of each predicate in a given input sentence. SRL is useful as an intermediate step in a wide range of natural language processing tasks, such as information extraction. automatic document categorization and question answering. An instance is as following [1]:
Semantic role labeling (SRL) is a form of shallow semantic parsing whose goal is to discover the predicate-argument structure of each predicate in a given input sentence. SRL is useful as an intermediate step in a wide range of natural language processing tasks, such as information extraction. automatic document categorization and question answering. An instance is as following [1]:
[ <sub>A0</sub> He ] [ <sub>AM-MOD</sub> would ][ <sub>AM-NEG</sub> n’t ] [ <sub>V</sub> accept] [ <sub>A1</sub> anything of value ] from [<sub>A2</sub> those he was writing about ].
[ <sub>A0</sub> He ] [ <sub>AM-MOD</sub> would ][ <sub>AM-NEG</sub> n’t ] [ <sub>V</sub> accept] [ <sub>A1</sub> anything of value ] from [<sub>A2</sub> those he was writing about ].
- V: verb
- V: verb
- A0: acceptor
- A0: acceptor
- A1: thing accepted
- A1: thing accepted
- A2: accepted-from
- A2: accepted-from
- A3: Attribute
- A3: Attribute
- AM-MOD: modal
- AM-MOD: modal
- AM-NEG: negation
- AM-NEG: negation
Given the verb "accept", the chunks in sentence would play certain semantic roles. Here, the label scheme is from Penn Proposition Bank.
Given the verb "accept", the chunks in sentence would play certain semantic roles. Here, the label scheme is from Penn Proposition Bank.
To this date, most of the successful SRL systems are built on top of some form of parsing results where pre-defined feature templates over the syntactic structure are used. This tutorial will present an end-to-end system using deep bidirectional long short-term memory (DB-LSTM)[2] for solving the SRL task, which largely outperforms the previous state-of-the-art systems. The system regards SRL task as the sequence labelling problem.
To this date, most of the successful SRL systems are built on top of some form of parsing results where pre-defined feature templates over the syntactic structure are used. This tutorial will present an end-to-end system using deep bidirectional long short-term memory (DB-LSTM)[2] for solving the SRL task, which largely outperforms the previous state-of-the-art systems. The system regards SRL task as the sequence labelling problem.
## Data Description
## Data Description
The relevant paper[2] takes the data set in CoNLL-2005&2012 Shared Task for training and testing. Accordingto data license, the demo adopts the test data set of CoNLL-2005, which can be reached on website.
The relevant paper[2] takes the data set in CoNLL-2005&2012 Shared Task for training and testing. Accordingto data license, the demo adopts the test data set of CoNLL-2005, which can be reached on website.
To download and process the original data, user just need to execute the following command:
To download and process the original data, user just need to execute the following command:
```bash
```bash
cd data
cd data
./get_data.sh
./get_data.sh
```
```
Several new files appear in the `data `directory as follows.
Several new files appear in the `data `directory as follows.
```bash
```bash
conll05st-release:the test data set of CoNll-2005 shared task
conll05st-release:the test data set of CoNll-2005 shared task
test.wsj.words:the Wall Street Journal data sentences
test.wsj.words:the Wall Street Journal data sentences
test.wsj.props: the propositional arguments
test.wsj.props: the propositional arguments
src.dict:the dictionary of words in sentences
feature: the extracted features from data set
tgt.dict:the labels dictionary
```
feature: the extracted features from data set
```
## Training
### DB-LSTM
## Training
Please refer to the Sentiment Analysis demo to learn more about the long short-term memory unit.
### DB-LSTM
Please refer to the Sentiment Analysis demo to learn more about the long short-term memory unit.
Unlike Bidirectional-LSTM that used in Sentiment Analysis demo, the DB-LSTM adopts another way to stack LSTM layer. First a standard LSTM processes the sequence in forward direction. The input and output of this LSTM layer are taken by the next LSTM layer as input, processed in reversed direction. These two standard LSTM layers compose a pair of LSTM. Then we stack LSTM layers pair after pair to obtain the deep LSTM model.
Unlike Bidirectional-LSTM that used in Sentiment Analysis demo, the DB-LSTM adopts another way to stack LSTM layer. First a standard LSTM processes the sequence in forward direction. The input and output of this LSTM layer are taken by the next LSTM layer as input, processed in reversed direction. These two standard LSTM layers compose a pair of LSTM. Then we stack LSTM layers pair after pair to obtain the deep LSTM model.
The following figure shows a temporal expanded 2-layer DB-LSTM network.
<center>
The following figure shows a temporal expanded 2-layer DB-LSTM network.

<center>
</center>

</center>
### Features
Two input features play an essential role in this pipeline: predicate (pred) and argument (argu). Two other features: predicate context (ctx-p) and region mark (mr) are also adopted. Because a single predicate word can not exactly describe the predicate information, especially when the same words appear more than one times in a sentence. With the predicate context, the ambiguity can be largely eliminated. Similarly, we use region mark m<sub>r</sub> = 1 to denote the argument position if it locates in the predicate context region, or m<sub>r</sub> = 0 if does not. These four simple features are all we need for our SRL system. Features of one sample with context size set to 1 is showed as following[2]:
### Features
<center>
Two input features play an essential role in this pipeline: predicate (pred) and argument (argu). Two other features: predicate context (ctx-p) and region mark (mr) are also adopted. Because a single predicate word can not exactly describe the predicate information, especially when the same words appear more than one times in a sentence. With the predicate context, the ambiguity can be largely eliminated. Similarly, we use region mark m<sub>r</sub> = 1 to denote the argument position if it locates in the predicate context region, or m<sub>r</sub> = 0 if does not. These four simple features are all we need for our SRL system. Features of one sample with context size set to 1 is showed as following[2]:

<center>
</center>

</center>
In this sample, the coresponding labelled sentence is:
In this sample, the coresponding labelled sentence is:
[ <sub>A1</sub> A record date ] has [ <sub>AM-NEG</sub> n't ] been [ <sub>V</sub> set ] .
[ <sub>A1</sub> A record date ] has [ <sub>AM-NEG</sub> n't ] been [ <sub>V</sub> set ] .
In the demo, we adopt the feature template as above, consists of : `argument`, `predicate`, `ctx-p (p=-1,0,1)`, `mark` and use `B/I/O` scheme to label each argument. These features and labels are stored in `feature` file, and separated by `\t`.
In the demo, we adopt the feature template as above, consists of : `argument`, `predicate`, `ctx-p (p=-1,0,1)`, `mark` and use `B/I/O` scheme to label each argument. These features and labels are stored in `feature` file, and separated by `\t`.
### Data Provider
### Data Provider
`dataprovider.py` is the python file to wrap data. `hook()` function is to define the data slots for network. The Six features and label are all IndexSlots.
```
`dataprovider.py` is the python file to wrap data. `hook()` function is to define the data slots for network. The Six features and label are all IndexSlots.
`db_lstm.py` is the neural network config file to load the dictionaries and define the data provider module and network architecture during the training procedure.
Seven `data_layer` load instances from data provider. Six features are transformed into embedddings respectively, and mixed by `mixed_layer` . Deep bidirectional LSTM layers extract features for the softmax layer. The objective function is cross entropy of labels.
The `process`function yield 9 lists which are 8 features and label.
### Run Training
### Neural Network Config
The script for training is `train.sh`, user just need to execute:
`db_lstm.py` is the neural network config file to load the dictionaries and define the data provider module and network architecture during the training procedure.
```bash
./train.sh
Nine `data_layer` load instances from data provider. Eight features are transformed into embedddings respectively, and mixed by `mixed_layer` . Deep bidirectional LSTM layers extract features for the softmax layer. The objective function is cross entropy of labels.
```
The content in `train.sh`:
### Run Training
```
The script for training is `train.sh`, user just need to execute:
paddle train \
```bash
--config=./db_lstm.py \
./train.sh
--save_dir=./output \
```
--trainer_count=4 \
The content in `train.sh`:
--log_period=10 \
```
--num_passes=500 \
paddle train \
--use_gpu=false \
--config=./db_lstm.py \
--show_parameter_stats_period=10 \
--use_gpu=0 \
--test_all_data_in_one_period=1 \
--log_period=5000 \
2>&1 | tee 'train.log'
--trainer_count=1 \
```
--show_parameter_stats_period=5000 \
--save_dir=./output \
-\--config=./db_lstm.py : network config file.
--num_passes=10000 \
-\--save_di=./output: output path to save models.
--average_test_period=10000000 \
-\--trainer_count=4 : set thread number (or GPU count).
--init_model_path=./data \
-\--log_period=10 : print log every 20 batches.
--load_missing_parameter_strategy=rand \
-\--num_passes=500: set pass number, one pass in PaddlePaddle means training all samples in dataset one time.
--test_all_data_in_one_period=1 \
-\--use_gpu=false: use CPU to train, set true, if you install GPU version of PaddlePaddle and want to use GPU to train.
2>&1 | tee 'train.log'
-\--show_parameter_stats_period=10: show parameter statistic every 100 batches.
```
-\--test_all_data_in_one_period=1: test all data in every testing.
-\--config=./db_lstm.py : network config file.
-\--use_gpu=false: use CPU to train, set true, if you install GPU version of PaddlePaddle and want to use GPU to train, until now crf_layer do not support GPU
After training, the models will be saved in directory `output`.
-\--log_period=500: print log every 20 batches.
-\--trainer_count=1: set thread number (or GPU count).
### Run testing
-\--show_parameter_stats_period=5000: show parameter statistic every 100 batches.
The script for testing is `test.sh`, user just need to execute:
-\--save_dir=./output: output path to save models.
```bash
-\--num_passes=10000: set pass number, one pass in PaddlePaddle means training all samples in dataset one time.
./test.sh
-\--average_test_period=10000000: do test on average parameter every average_test_period batches
-\--load_missing_parameter_strategy=rand: random initialization unexisted parameters
```
-\--test_all_data_in_one_period=1: test all data in one period
paddle train \
--config=./db_lstm.py \
--model_list=$model_list \
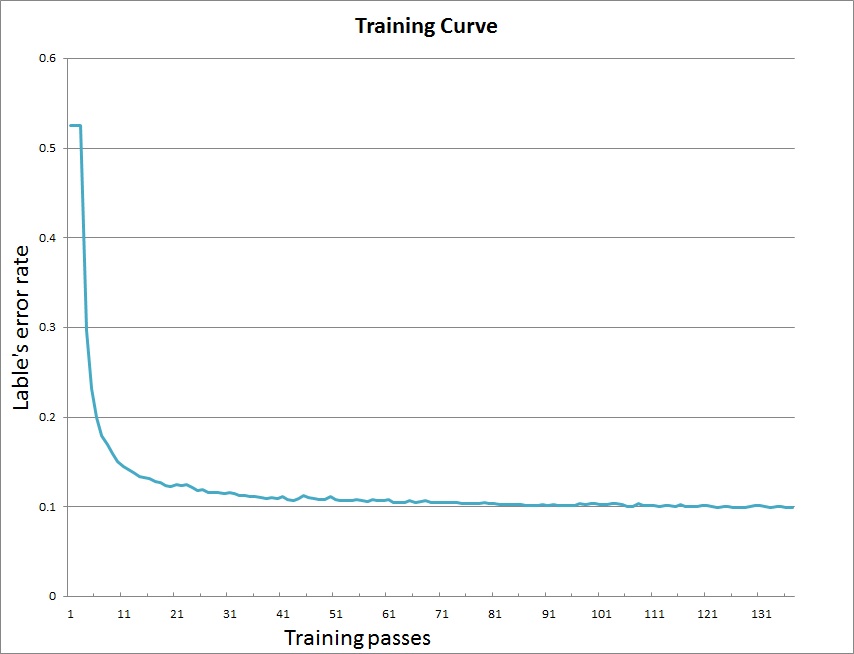
After training, the models will be saved in directory `output`. Our training curve is as following:
--job=test \
<center>
--config_args=is_test=1 \

```
</center>
-\--config=./db_lstm.py: network config file
### Run testing
-\--model_list=$model_list.list: model list file
The script for testing is `test.sh`, user just need to execute:
-\--job=test: indicate the test job
```bash
-\--config_args=is_test=1: flag to indicate test
./test.sh
```
The main part in `tesh.sh`
### Run prediction
```
The script for prediction is `predict.sh`, user just need to execute:
paddle train \
```bash
--config=./db_lstm.py \
./predict.sh
--model_list=$model_list \
--job=test \
```
--config_args=is_test=1 \
In `predict.sh`, user should offer the network config file, model path, label file, word dictionary file, feature file
```
```
python predict.py
-\--config=./db_lstm.py: network config file
-c $config_file
-\--model_list=$model_list.list: model list file
-w $model_path
-\--job=test: indicate the test job
-l $label_file
-\--config_args=is_test=1: flag to indicate test
-d $dict_file
-\--test_all_data_in_one_period=1: test all data in 1 period
-i $input_file
```
### Run prediction
`predict.py` is the main executable python script, which includes functions: load model, load data, data prediction. The network model will output the probability distribution of labels. In the demo, we take the label with maximum probability as result. User can also implement the beam search or viterbi decoding upon the probability distribution matrix.
The script for prediction is `predict.sh`, user just need to execute:
```bash
After prediction, the result is saved in `predict.res`.
./predict.sh
## Reference
```
[1] Martha Palmer, Dan Gildea, and Paul Kingsbury. The Proposition Bank: An Annotated Corpus of Semantic Roles , Computational Linguistics, 31(1), 2005.
In `predict.sh`, user should offer the network config file, model path, label file, word dictionary file, feature file
```
[2] Zhou, Jie, and Wei Xu. "End-to-end learning of semantic role labeling using recurrent neural networks." Proceedings of the Annual Meeting of the Association for Computational Linguistics. 2015.
python predict.py
-c $config_file \
-w $best_model_path \
-l $label_file \
-p $predicate_dict_file \
-d $dict_file \
-i $input_file \
-o $output_file
```
`predict.py` is the main executable python script, which includes functions: load model, load data, data prediction. The network model will output the probability distribution of labels. In the demo, we take the label with maximum probability as result. User can also implement the beam search or viterbi decoding upon the probability distribution matrix.
After prediction, the result is saved in `predict.res`.
## Reference
[1] Martha Palmer, Dan Gildea, and Paul Kingsbury. The Proposition Bank: An Annotated Corpus of Semantic Roles , Computational Linguistics, 31(1), 2005.
[2] Zhou, Jie, and Wei Xu. "End-to-end learning of semantic role labeling using recurrent neural networks." Proceedings of the Annual Meeting of the Association for Computational Linguistics. 2015.
{kind=link}