deal with conflit
Showing
cmake/external/nccl.cmake
0 → 100644
doc/design/dcgan.png
0 → 100644
{kind=link}
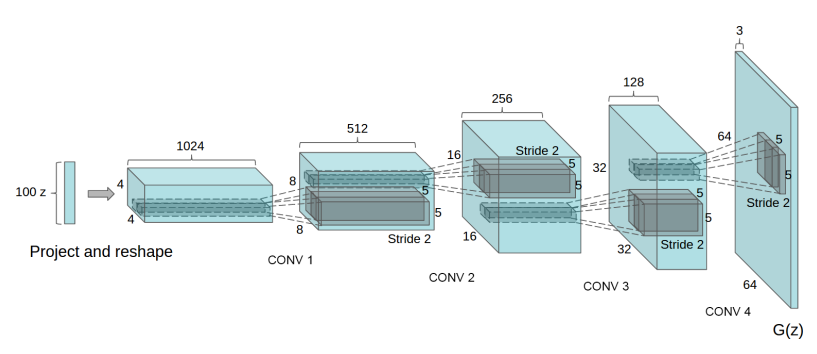
56.6 KB
doc/design/executor.md
0 → 100644
doc/design/gan_api.md
0 → 100644
doc/design/graph_survey.md
0 → 100644
{kind=link}
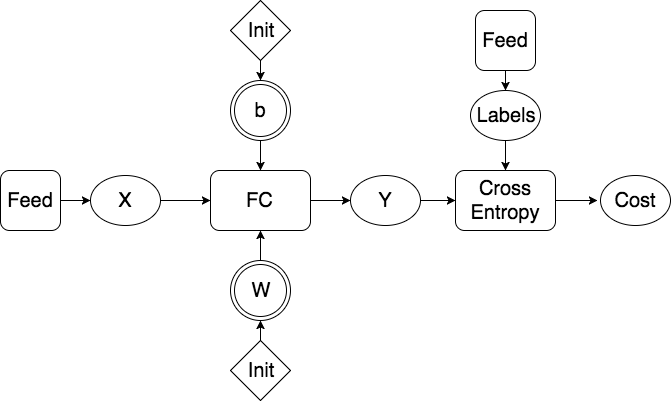
31.5 KB
{kind=link}
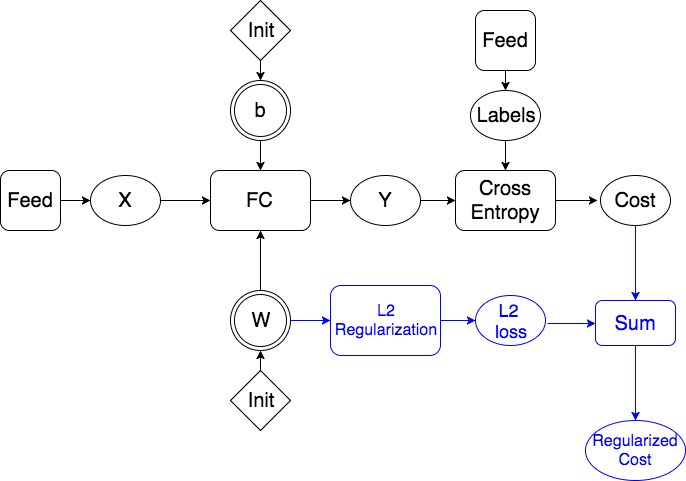
45.0 KB
{kind=link}
{kind=link}
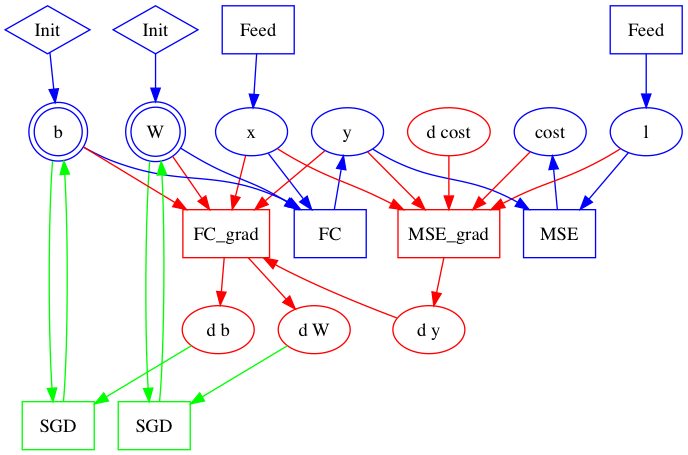
| W: | H:
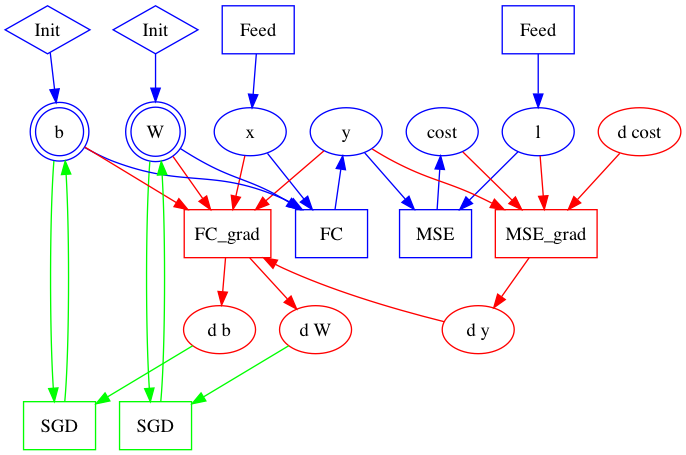
| W: | H:
{kind=link}
{kind=link}
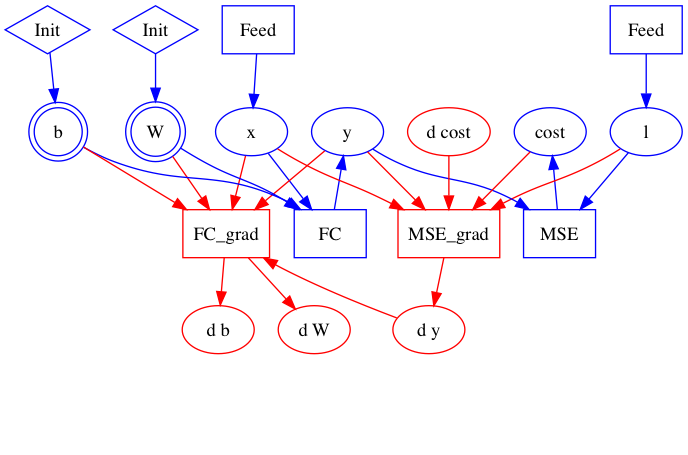
| W: | H:
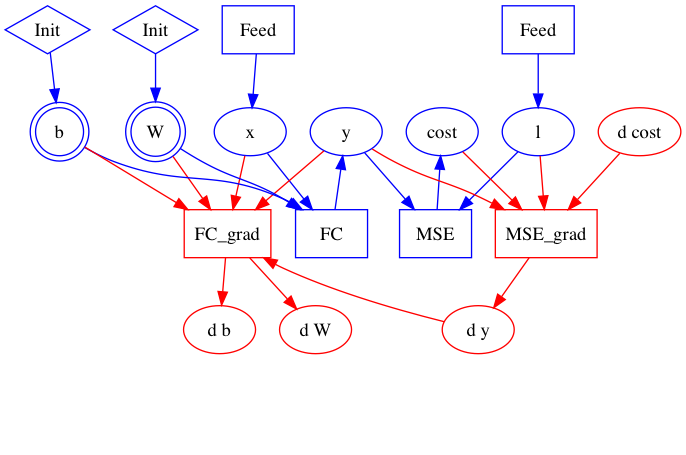
| W: | H:
{kind=link}
{kind=link}
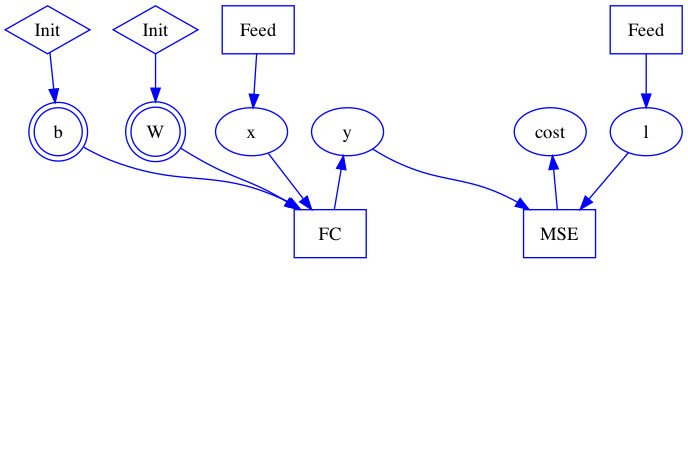
| W: | H:
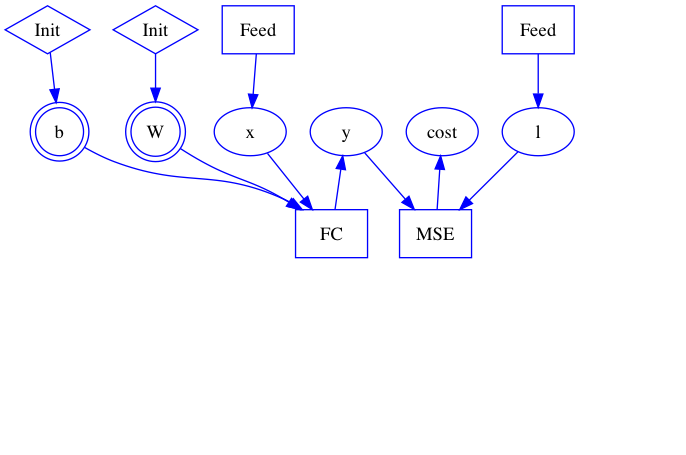
| W: | H:
{kind=link}
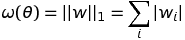
1.1 KB
{kind=link}
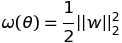
989 字节
{kind=link}
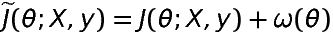
1.6 KB
doc/design/infer_var_type.md
0 → 100644
doc/design/model_format.md
0 → 100644
doc/design/optimizer.md
0 → 100644
doc/design/prune.md
0 → 100644
doc/design/python_api.md
0 → 100644
doc/design/refactor/session.md
0 → 100644
doc/design/register_grad_op.md
0 → 100644
doc/design/regularization.md
0 → 100644
doc/design/selected_rows.md
0 → 100644
doc/design/test.dot
0 → 100644
doc/design/test.dot.png
0 → 100644
{kind=link}
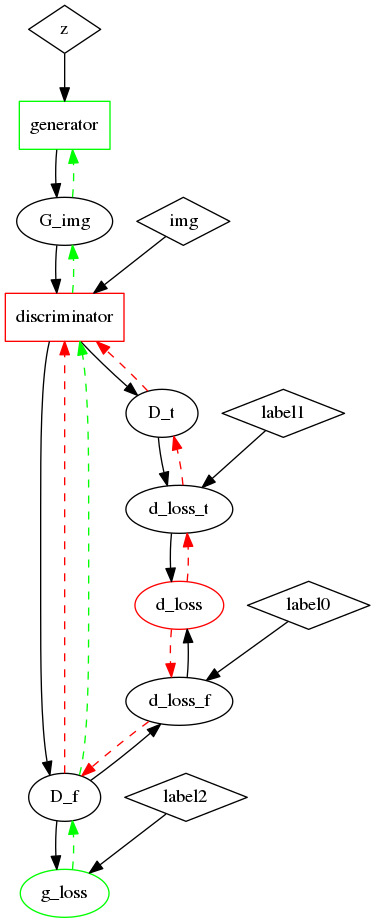
57.6 KB
{kind=link}
文件已移动
{kind=link}
文件已移动
{kind=link}
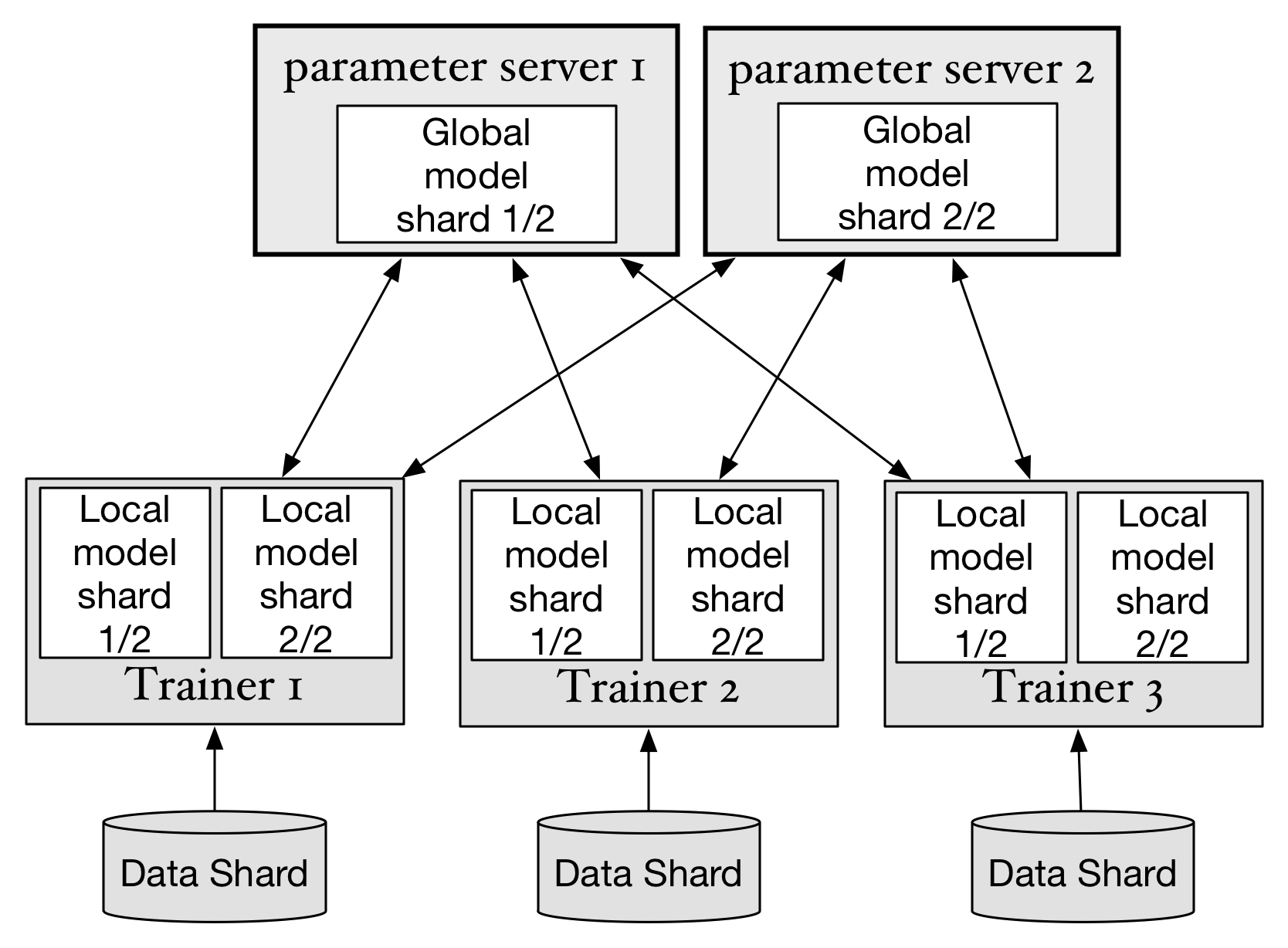
141.7 KB
{kind=link}
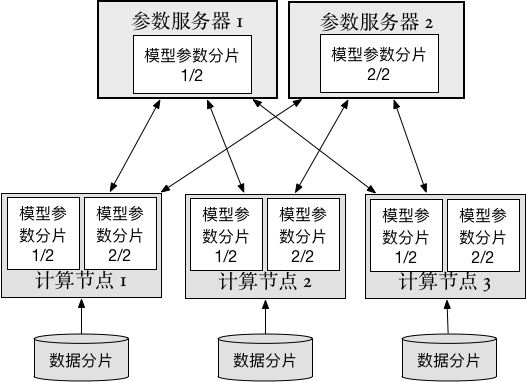
33.1 KB
{kind=link}

455.6 KB
{kind=link}
51.4 KB
{kind=link}
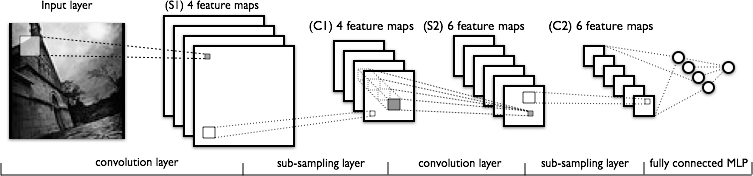
48.7 KB
{kind=link}
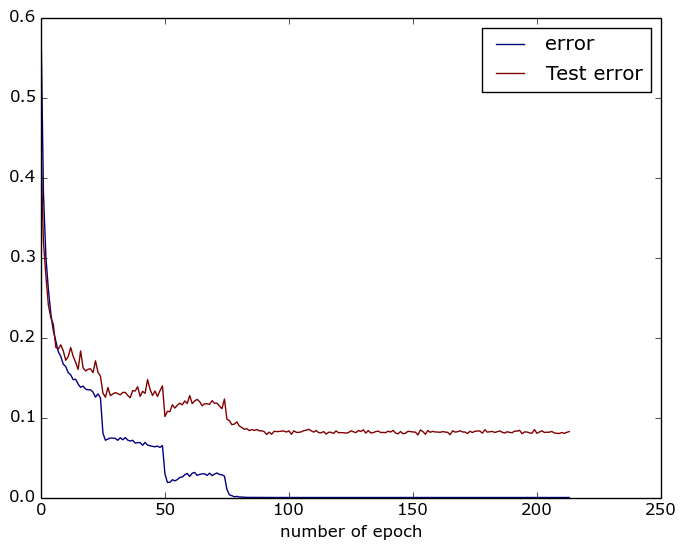
30.3 KB
{kind=link}

455.6 KB
{kind=link}
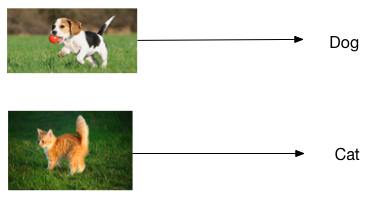
51.4 KB
{kind=link}
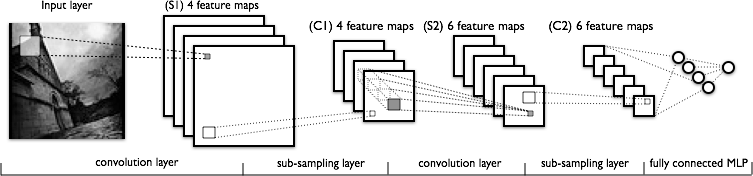
48.7 KB
{kind=link}
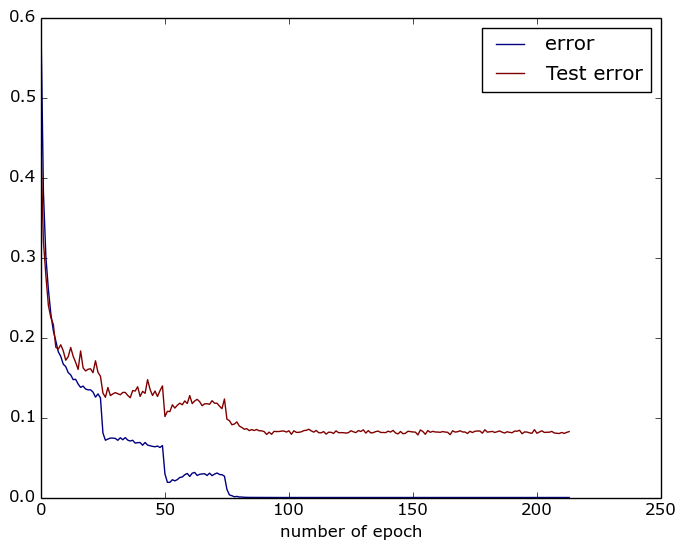
30.3 KB
doc/tutorials/index_cn.md
已删除
100644 → 0
此差异已折叠。
doc/tutorials/index_en.md
已删除
100644 → 0
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
此差异已折叠。
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
此差异已折叠。
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
此差异已折叠。
此差异已折叠。
doc/v1_api_tutorials/README.md
0 → 100644
此差异已折叠。
文件已移动
文件已移动
{kind=link}
文件已移动
{kind=link}
{kind=link}
文件已移动
{kind=link}
文件已移动
{kind=link}
文件已移动
文件已移动
文件已移动
文件已移动
文件已移动
{kind=link}
文件已移动
{kind=link}
文件已移动
{kind=link}
文件已移动
{kind=link}
文件已移动
{kind=link}
文件已移动
{kind=link}
文件已移动
{kind=link}
文件已移动
{kind=link}
文件已移动
{kind=link}
文件已移动
{kind=link}
文件已移动
{kind=link}
文件已移动
{kind=link}
文件已移动
{kind=link}
文件已移动
{kind=link}
文件已移动
{kind=link}
文件已移动
{kind=link}
文件已移动
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
paddle/capi/export.sym
已删除
100644 → 0
paddle/framework/data_type.h
0 → 100644
此差异已折叠。
此差异已折叠。
paddle/framework/executor.cc
0 → 100644
此差异已折叠。
paddle/framework/executor.h
0 → 100644
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
paddle/framework/proto_desc.h
0 → 100644
此差异已折叠。
paddle/framework/prune.cc
0 → 100644
此差异已折叠。
paddle/framework/prune_test.cc
0 → 100644
此差异已折叠。
paddle/framework/saver.proto
0 → 100644
此差异已折叠。
paddle/framework/selected_rows.cc
0 → 100644
此差异已折叠。
paddle/framework/selected_rows.h
0 → 100644
此差异已折叠。
此差异已折叠。
paddle/framework/tensor_array.cc
0 → 100644
此差异已折叠。
paddle/framework/tensor_array.h
0 → 100644
此差异已折叠。
此差异已折叠。
paddle/framework/type_defs.h
0 → 100644
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
paddle/operators/adadelta_op.cc
0 → 100644
此差异已折叠。
paddle/operators/adadelta_op.cu
0 → 100644
此差异已折叠。
paddle/operators/adadelta_op.h
0 → 100644
此差异已折叠。
paddle/operators/adagrad_op.cc
0 → 100644
此差异已折叠。
paddle/operators/adagrad_op.cu
0 → 100644
此差异已折叠。
paddle/operators/adagrad_op.h
0 → 100644
此差异已折叠。
paddle/operators/adam_op.cc
0 → 100644
此差异已折叠。
paddle/operators/adam_op.cu
0 → 100644
此差异已折叠。
paddle/operators/adam_op.h
0 → 100644
此差异已折叠。
paddle/operators/adamax_op.cc
0 → 100644
此差异已折叠。
paddle/operators/adamax_op.h
0 → 100644
此差异已折叠。
paddle/operators/batch_norm_op.cc
0 → 100644
此差异已折叠。
paddle/operators/batch_norm_op.md
0 → 100644
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
paddle/operators/conv_cudnn_op.cc
0 → 100644
此差异已折叠。
paddle/operators/conv_cudnn_op.cu
0 → 100644
此差异已折叠。
paddle/operators/conv_shift_op.cc
0 → 100644
此差异已折叠。
paddle/operators/conv_shift_op.cu
0 → 100644
此差异已折叠。
paddle/operators/conv_shift_op.h
0 → 100644
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
paddle/operators/fc_op.cc
已删除
100644 → 0
此差异已折叠。
paddle/operators/feed_op.cc
0 → 100644
此差异已折叠。
paddle/operators/fetch_op.cc
0 → 100644
此差异已折叠。
此差异已折叠。
paddle/operators/gather.cu.h
0 → 100644
此差异已折叠。
paddle/operators/gru_unit_op.cc
0 → 100644
此差异已折叠。
paddle/operators/gru_unit_op.cu
0 → 100644
此差异已折叠。
paddle/operators/gru_unit_op.h
0 → 100644
此差异已折叠。
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
paddle/operators/increment_op.cc
0 → 100644
此差异已折叠。
paddle/operators/increment_op.cu
0 → 100644
此差异已折叠。
paddle/operators/increment_op.h
0 → 100644
此差异已折叠。
paddle/operators/lstm_op.cc
0 → 100644
此差异已折叠。
paddle/operators/lstm_op.cu
0 → 100644
此差异已折叠。
paddle/operators/lstm_op.h
0 → 100644
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
paddle/operators/math/matmul.h
0 → 100644
此差异已折叠。
paddle/operators/math/pooling.cc
0 → 100644
此差异已折叠。
paddle/operators/math/pooling.cu
0 → 100644
此差异已折叠。
paddle/operators/math/pooling.h
0 → 100644
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
paddle/operators/math/vol2col.cc
0 → 100644
此差异已折叠。
paddle/operators/math/vol2col.cu
0 → 100644
此差异已折叠。
paddle/operators/math/vol2col.h
0 → 100644
此差异已折叠。
此差异已折叠。
paddle/operators/matmul_op.cc
0 → 100644
此差异已折叠。
paddle/operators/matmul_op.cu
0 → 100644
此差异已折叠。
paddle/operators/matmul_op.h
0 → 100644
此差异已折叠。
paddle/operators/momentum_op.cc
0 → 100644
此差异已折叠。
paddle/operators/momentum_op.cu
0 → 100644
此差异已折叠。
paddle/operators/momentum_op.h
0 → 100644
此差异已折叠。
paddle/operators/pool_op.cc
0 → 100644
此差异已折叠。
paddle/operators/pool_op.cu
0 → 100644
此差异已折叠。
paddle/operators/pool_op.h
0 → 100644
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
paddle/operators/rmsprop_op.cc
0 → 100644
此差异已折叠。
paddle/operators/rmsprop_op.cu
0 → 100644
此差异已折叠。
paddle/operators/rmsprop_op.h
0 → 100644
此差异已折叠。
此差异已折叠。
此差异已折叠。
paddle/operators/scatter.cu.h
0 → 100644
此差异已折叠。
paddle/operators/scatter_op.cu
0 → 100644
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
paddle/platform/dynload/nccl.cc
0 → 100644
此差异已折叠。
paddle/platform/dynload/nccl.h
0 → 100644
此差异已折叠。
paddle/platform/nccl_test.cu
0 → 100644
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。