Created by: ysh329
状态:等待review
主要内容
- 内容:移除tf_mobilenetv1/v2的reshape2->squeeze2、resshape2的结构,目前仅限于tf_mobilenetv1/v2。tf模型的mobilenetv1/v2在这两个结构中仅仅做1001x1x1->1001的维度变化没有实际作用,对于gpu来说这种操作十分费时;
- 目的:benchmark。对opencl模型来说,可以移除掉11个op,其中包括原模型中的reshape2->squeeze2和最后的reshape2的3个原有op,以及与之带来的工具类op 8个(layout、io_copy),因为reshape2->squeeze2和reshape2中间有个cpu计算的squeeze2和softmax,而每次上传到gpu上都会有io_copy和layout转换操作。
注:由于担心该pass(在optimizer.h)的执行顺序的位置对其它target有影响,目前只对arm cpu和opencl开启。
该pass实现前后tf_mobilenetv1性能对比
注:这里使用test_model_bin测试(带log多少影响实际性能,实际性能表现后续由QA来测给出具体报告,这里只体现收益百分比),均为armv7。repeats=100,warmup=20;
| kirin820-亮屏 / tf_mobilenetv1 | CPU-st-bigcore | GPU-G57-opencl |
|---|---|---|
| pass实现前性能 | 46ms | 36ms |
| pass实现后性能 | 43ms | 26ms |
| 性能收益相比实现前 | 6.5% | 27.7% |
| snapdragon855-亮屏 / tf_mobilenetv1 | CPU-st-bigcore | GPU-adreno640-opencl |
|---|---|---|
| pass实现前性能 | 37.5ms | 20.7ms |
| pass实现后性能 | 34.0ms | 18.3ms |
| 性能收益相比实现前 | 9.3% | 11.5% |
该pass实现前后tf_mobilenetv2性能对比
注:这里使用test_model_bin测试(带log多少影响实际性能,实际性能表现后续由QA来测给出具体报告,这里只体现收益百分比),均为armv7。repeats=100,warmup=20;
| kirin820-亮屏 / tf_mobilenetv2 | CPU-st-bigcore | GPU-G57-opencl |
|---|---|---|
| pass实现前性能 | 31ms | 35ms |
| pass实现后性能 | 29ms | 29ms |
| 性能收益相比实现前 | 6.4% | 17.1% |
| snapdragon855-亮屏 / tf_mobilenetv2 | CPU-st-bigcore | GPU-adreno640-opencl |
|---|---|---|
| pass实现前性能 | 26.4ms | 29.2ms |
| pass实现后性能 | 24.7ms | 24.5ms |
| 性能收益相比实现前 | 6.4% | 16.0% |
该pass实现前的tensorflow mobilenetv1尾部结构
下面表格为opencl的Profiler信息,conv2d后面为尾部结构:
| OP | KernelPlace |
|---|---|
| conv2d | conv2d:opencl/float16/ImageDefault |
| layout | layout:opencl/any/NCHW |
| io_copy | io_copy:opencl/any/any |
| squeeze2 | squeeze2:arm/float/NCHW |
| io_copy | io_copy:opencl/any/any |
| layout | layout:opencl/any/ImageDefault |
| reshape2 | reshape2:opencl/float16/ImageDefault |
| layout | layout:opencl/any/NCHW |
| io_copy | io_copy:opencl/any/any |
| softmax | softmax:arm/float/NCHW |
| io_copy | io_copy:opencl/any/any |
| layout | layout:opencl/any/ImageDefault |
| reshape2 | reshape2:opencl/float16/ImageDefault |
| layout | layout:opencl/any/NCHW |
| io_copy | io_copy:opencl/any/any |
该pass实现后的tensorflow mobilenetv1尾部结构
conv2d后面为尾部结构:该pass实现后,opencl模型减少11个op,arm cpu减少3个op(reshape2->squeeze2,reshape2)。
| OP | KernelPlace |
|---|---|
| conv2d | conv2d:opencl/float16/ImageDefault |
| layout | layout:opencl/any/NCHW |
| io_copy | io_copy:opencl/any/any |
| softmax | softmax:arm/float/NCHW |
原模型digraph
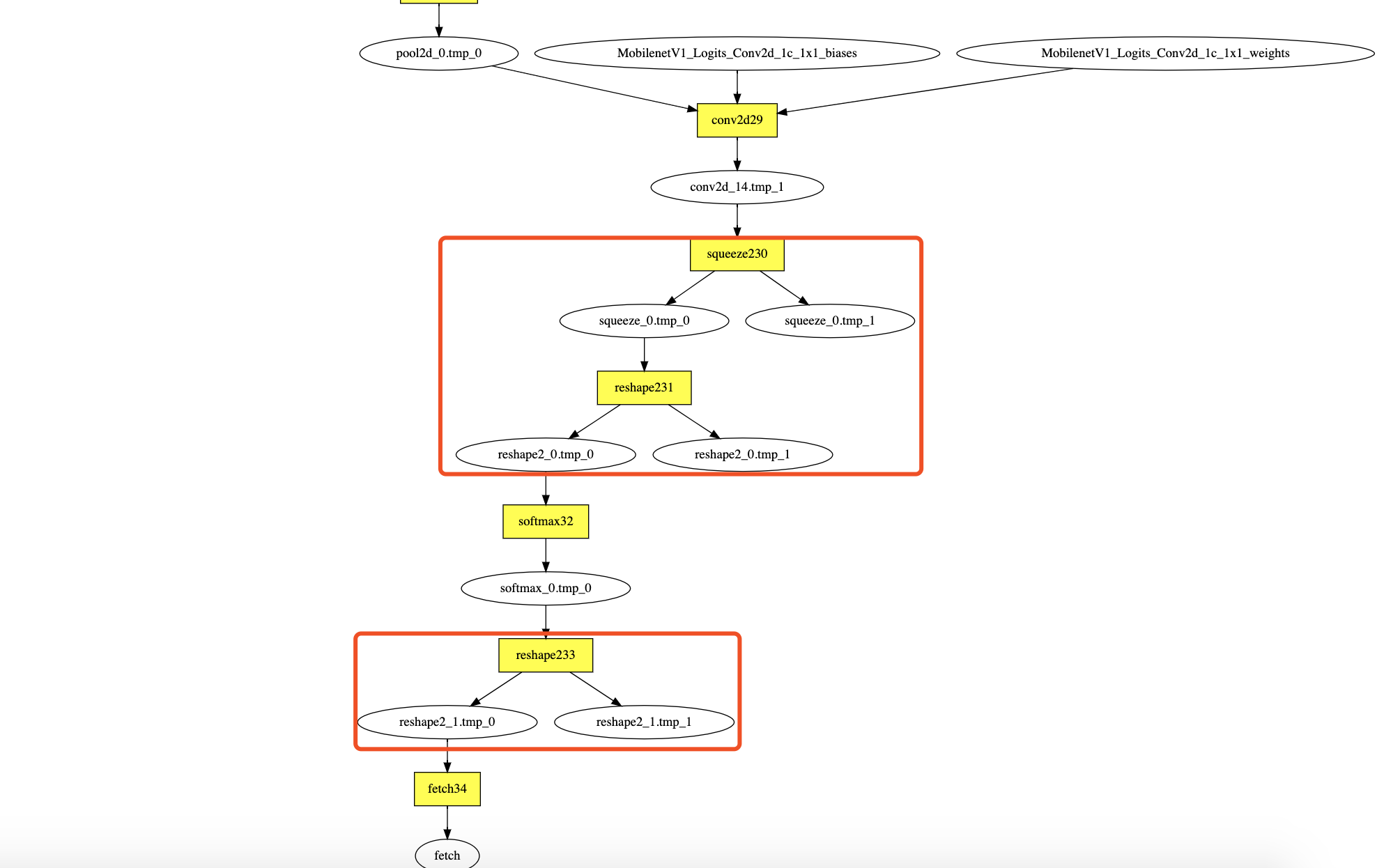
上图是原模型(未加工具op如io_copy、layout、calib等),红框里的op全部优化掉:
- 原模型减少3个op:reshape2->squeeze2,reshape2;
- arm cpu减少3个op,因为没有layout和io_copy;
- opencl减少11个op,另外8个是layout和io_copy。