Created by: cocodark
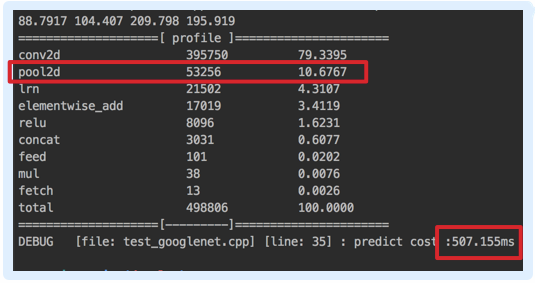
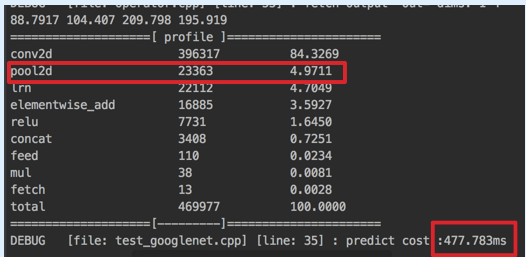
before optimize: after optimize: 3x3 pool kernel is common, then i use neon register to load the input kernel. The asm implementation is as fast as the way with neon intrinsics now.